 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Term and Long-Term Context Aggregation Network for Video Inpainting
Paper and Code
Sep 12, 2020
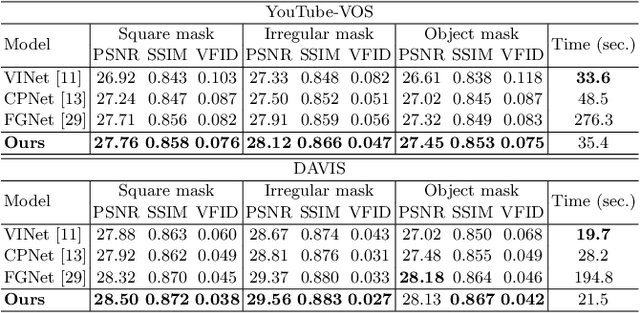


Video inpainting aims to restore missing regions of a video and has many applications such as video editing and object removal. However, existing methods either suffer from inaccurate short-term context aggregation or rarely explore long-term frame information. In this work, we present a novel context aggregation network to effectively exploit both short-term and long-term frame information for video inpainting. In the encoding stage, we propose boundary-aware short-term context aggregation, which aligns and aggregates, from neighbor frames, local regions that are closely related to the boundary context of missing regions into the target frame. Furthermore, we propose dynamic long-term context aggregation to globally refine the feature map generated in the encoding stage using long-term frame features, which are dynamically updated throughout the inpainting process. Experiments show that it outperforms state-of-the-art methods with better inpainting results and fast inpainting speed.