 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Seeing: Evaluating Multimodal LLMs on Tool-Enabled Image Perception, Transformation, and Reasoning
Oct 14, 2025Multimodal Large Language Models (MLLMs) are increasingly applied in real-world scenarios where user-provided images are often imperfect, requiring active image manipulations such as cropping, editing, or enhancement to uncover salient visual cues. Beyond static visual perception, MLLMs must also think with images: dynamically transforming visual content and integrating it with other tools to solve complex tasks. However, this shift from treating vision as passive context to a manipulable cognitive workspace remains underexplored. Most existing benchmarks still follow a think about images paradigm, where images are regarded as static inputs. To address this gap, we introduce IRIS, an Interactive Reasoning with Images and Systems that evaluates MLLMs' ability to perceive, transform, and reason across complex visual-textual tasks under the think with images paradigm. IRIS comprises 1,204 challenging, open-ended vision tasks (603 single-turn, 601 multi-turn) spanning across five diverse domains, each paired with detailed rubrics to enable systematic evaluation. Our evaluation shows that current MLLMs struggle with tasks requiring effective integration of vision and general-purpose tools. Even the strongest model (GPT-5-think) reaches only 18.68% pass rate. We further observe divergent tool-use behaviors, with OpenAI models benefiting from diverse image manipulations while Gemini-2.5-pro shows no improvement. By introducing the first benchmark centered on think with images, IRIS offers critical insights for advancing visual intelligence in MLLMs.
RestoreGrad: Signal Restoration Using Conditional Denoising Diffusion Models with Jointly Learned Prior
Feb 19, 2025Denoising diffusion probabilistic models (DDPMs) can be utilized for recovering a clean signal from its degraded observation(s) by conditioning the model on the degraded signal. The degraded signals are themselves contaminated versions of the clean signals; due to this correlation, they may encompass certain useful information about the target clean data distribution. However, existing adoption of the standard Gaussian as the prior distribution in turn discards such information, resulting in sub-optimal performance. In this paper, we propose to improve conditional DDPMs for signal restoration by leveraging a more informative prior that is jointly learned with the diffusion model. The proposed framework, called RestoreGrad, seamlessly integrates DDPMs into the variational autoencoder framework and exploits the correlation between the degraded and clean signals to encode a better diffusion prior. On speech and image restoration tasks, we show that RestoreGrad demonstrates faster convergence (5-10 times fewer training steps) to achieve better quality of restored signals over existing DDPM baselines, and improved robustness to using fewer sampling steps in inference time (2-2.5 times fewer), advocating the advantages of leveraging jointly learned prior for efficiency improvements in the diffusion process.
CWCL: Cross-Modal Transfer with Continuously Weighted Contrastive Loss
Sep 26, 2023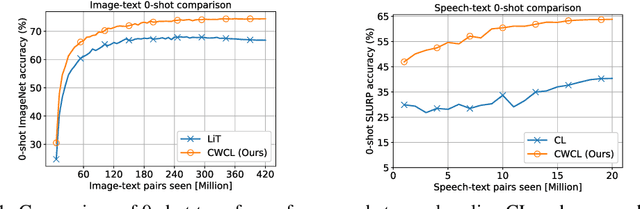
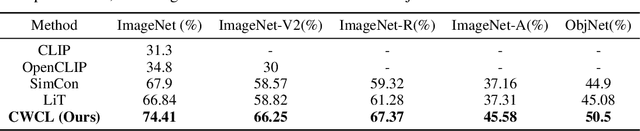
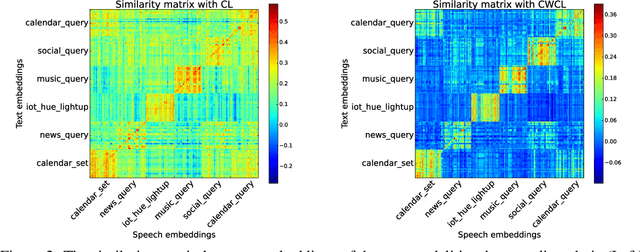

This paper considers contrastive training for cross-modal 0-shot transfer wherein a pre-trained model in one modality is used for representation learning in another domain using pairwise data. The learnt models in the latter domain can then be used for a diverse set of tasks in a zero-shot way, similar to ``Contrastive Language-Image Pre-training (CLIP)'' and ``Locked-image Tuning (LiT)'' that have recently gained considerable attention. Most existing works for cross-modal representation alignment (including CLIP and LiT) use the standard contrastive training objective, which employs sets of positive and negative examples to align similar and repel dissimilar training data samples. However, similarity amongst training examples has a more continuous nature, thus calling for a more `non-binary' treatment. To address this, we propose a novel loss function called Continuously Weighted Contrastive Loss (CWCL) that employs a continuous measure of similarity. With CWCL, we seek to align the embedding space of one modality with another. Owing to the continuous nature of similarity in the proposed loss function, these models outperform existing methods for 0-shot transfer across multiple models, datasets and modalities. Particularly, we consider the modality pairs of image-text and speech-text and our models achieve 5-8% (absolute) improvement over previous state-of-the-art methods in 0-shot image classification and 20-30% (absolute) improvement in 0-shot speech-to-intent classification and keyword classification.
To Wake-up or Not to Wake-up: Reducing Keyword False Alarm by Successive Refinement
Apr 06, 2023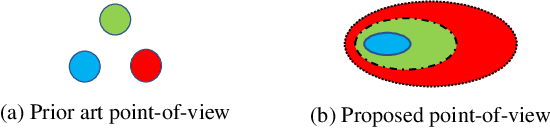
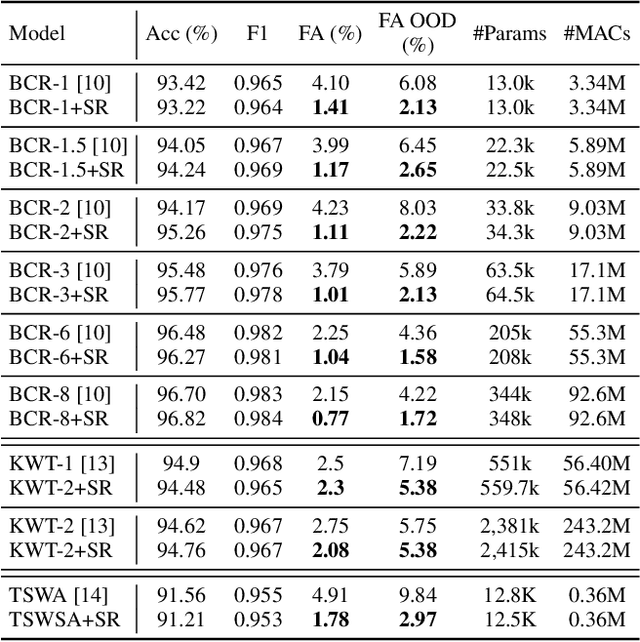
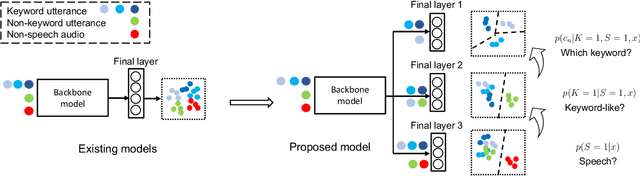
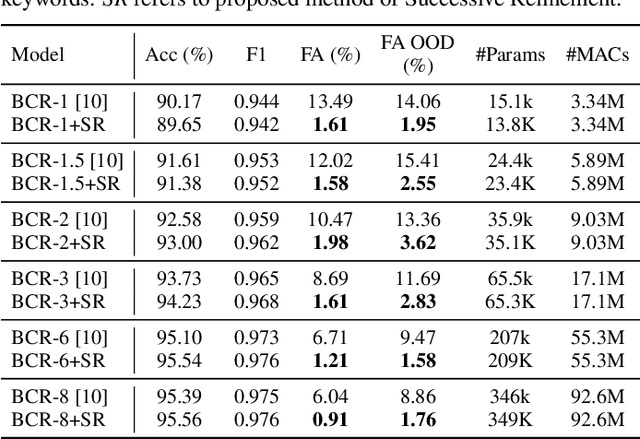
Keyword spotting systems continuously process audio streams to detect keywords. One of the most challenging tasks in designing such systems is to reduce False Alarm (FA) which happens when the system falsely registers a keyword despite the keyword not being uttered. In this paper, we propose a simple yet elegant solution to this problem that follows from the law of total probability. We show that existing deep keyword spotting mechanisms can be improved by Successive Refinement, where the system first classifies whether the input audio is speech or not, followed by whether the input is keyword-like or not, and finally classifies which keyword was uttered. We show across multiple models with size ranging from 13K parameters to 2.41M parameters, the successive refinement technique reduces FA by up to a factor of 8 on in-domain held-out FA data, and up to a factor of 7 on out-of-domain (OOD) FA data. Further, our proposed approach is "plug-and-play" and can be applied to any deep keyword spotting model.