 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoreGrad: Signal Restoration Using Conditional Denoising Diffusion Models with Jointly Learned Prior
Feb 19, 2025Denoising diffusion probabilistic models (DDPMs) can be utilized for recovering a clean signal from its degraded observation(s) by conditioning the model on the degraded signal. The degraded signals are themselves contaminated versions of the clean signals; due to this correlation, they may encompass certain useful information about the target clean data distribution. However, existing adoption of the standard Gaussian as the prior distribution in turn discards such information, resulting in sub-optimal performance. In this paper, we propose to improve conditional DDPMs for signal restoration by leveraging a more informative prior that is jointly learned with the diffusion model. The proposed framework, called RestoreGrad, seamlessly integrates DDPMs into the variational autoencoder framework and exploits the correlation between the degraded and clean signals to encode a better diffusion prior. On speech and image restoration tasks, we show that RestoreGrad demonstrates faster convergence (5-10 times fewer training steps) to achieve better quality of restored signals over existing DDPM baselines, and improved robustness to using fewer sampling steps in inference time (2-2.5 times fewer), advocating the advantages of leveraging jointly learned prior for efficiency improvements in the diffusion process.
CWCL: Cross-Modal Transfer with Continuously Weighted Contrastive Loss
Sep 26, 2023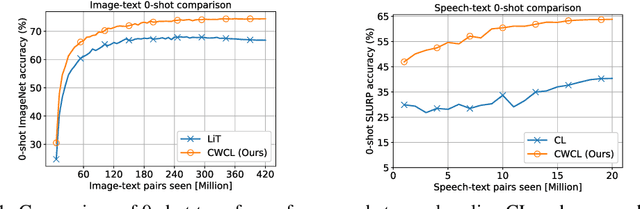
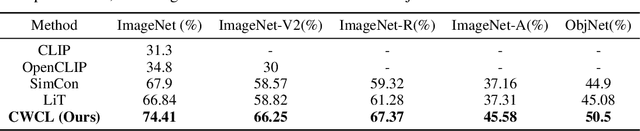
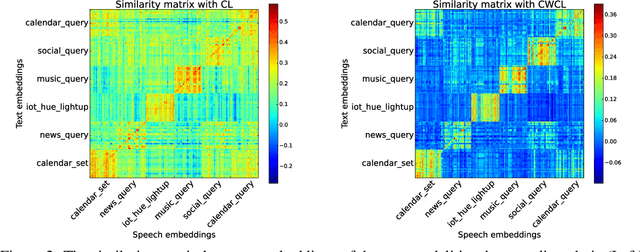

This paper considers contrastive training for cross-modal 0-shot transfer wherein a pre-trained model in one modality is used for representation learning in another domain using pairwise data. The learnt models in the latter domain can then be used for a diverse set of tasks in a zero-shot way, similar to ``Contrastive Language-Image Pre-training (CLIP)'' and ``Locked-image Tuning (LiT)'' that have recently gained considerable attention. Most existing works for cross-modal representation alignment (including CLIP and LiT) use the standard contrastive training objective, which employs sets of positive and negative examples to align similar and repel dissimilar training data samples. However, similarity amongst training examples has a more continuous nature, thus calling for a more `non-binary' treatment. To address this, we propose a novel loss function called Continuously Weighted Contrastive Loss (CWCL) that employs a continuous measure of similarity. With CWCL, we seek to align the embedding space of one modality with another. Owing to the continuous nature of similarity in the proposed loss function, these models outperform existing methods for 0-shot transfer across multiple models, datasets and modalities. Particularly, we consider the modality pairs of image-text and speech-text and our models achieve 5-8% (absolute) improvement over previous state-of-the-art methods in 0-shot image classification and 20-30% (absolute) improvement in 0-shot speech-to-intent classification and keyword classification.
To Wake-up or Not to Wake-up: Reducing Keyword False Alarm by Successive Refinement
Apr 06, 2023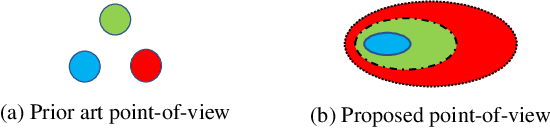
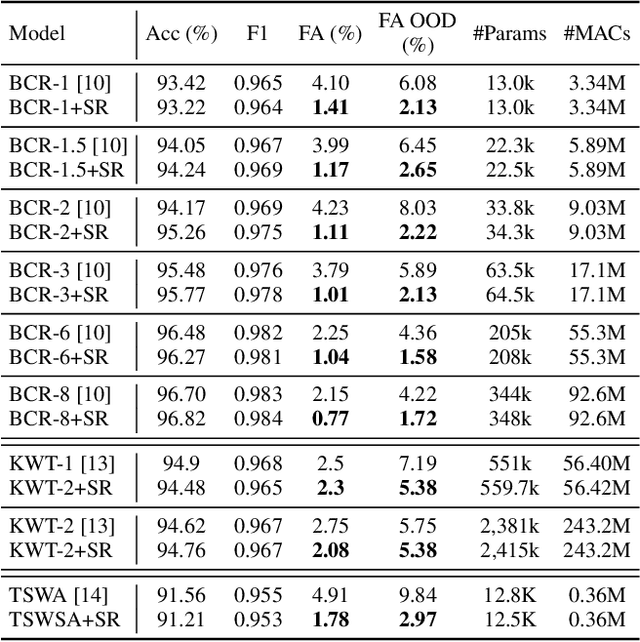
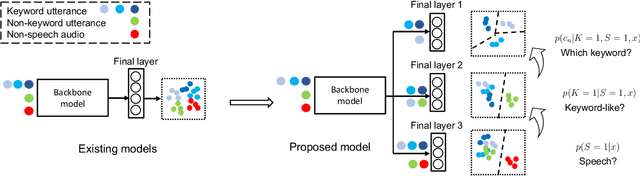
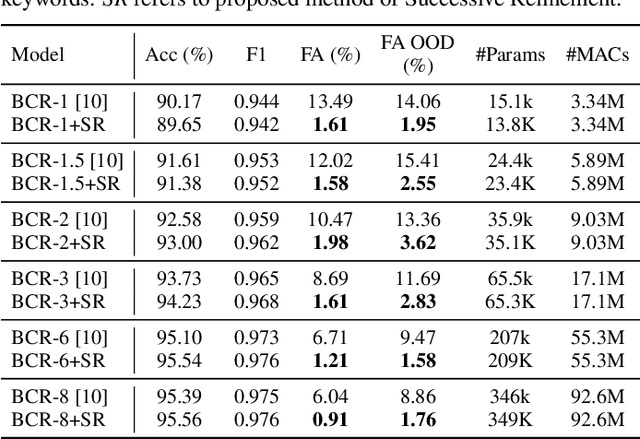
Keyword spotting systems continuously process audio streams to detect keywords. One of the most challenging tasks in designing such systems is to reduce False Alarm (FA) which happens when the system falsely registers a keyword despite the keyword not being uttered. In this paper, we propose a simple yet elegant solution to this problem that follows from the law of total probability. We show that existing deep keyword spotting mechanisms can be improved by Successive Refinement, where the system first classifies whether the input audio is speech or not, followed by whether the input is keyword-like or not, and finally classifies which keyword was uttered. We show across multiple models with size ranging from 13K parameters to 2.41M parameters, the successive refinement technique reduces FA by up to a factor of 8 on in-domain held-out FA data, and up to a factor of 7 on out-of-domain (OOD) FA data. Further, our proposed approach is "plug-and-play" and can be applied to any deep keyword spotting model.
A DNN based Normalized Time-frequency Weighted Criterion for Robust Wideband DoA Estimation
Feb 20, 2023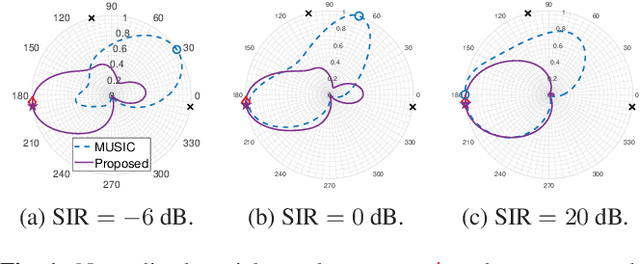



Deep neural networks (DNNs) have greatly benefited direction of arrival (DoA) estimation methods for speech source localization in noisy environments. However, their localization accuracy is still far from satisfactory due to the vulnerability to nonspeech interference. To improve the robustness against interference, we propose a DNN based normalized time-frequency (T-F) weighted criterion which minimizes the distance between the candidate steering vectors and the filtered snapshots in the T-F domain. Our method requires no eigendecomposition and uses a simple normalization to prevent the optimization objective from being misled by noisy filtered snapshots. We also study different designs of T-F weights guided by a DNN. We find that duplicating the Hadamard product of speech ratio masks is highly effective and better than other techniques such as direct masking and taking the mean in the proposed approach. However, the best-performing design of T-F weights is criterion-dependent in general. Experiments show that the proposed method outperforms popular DNN based DoA estimation methods including widely used subspace methods in noisy and reverberant environments.
A Generalized Proportionate-Type Normalized Subband Adaptive Filter
Nov 17, 2021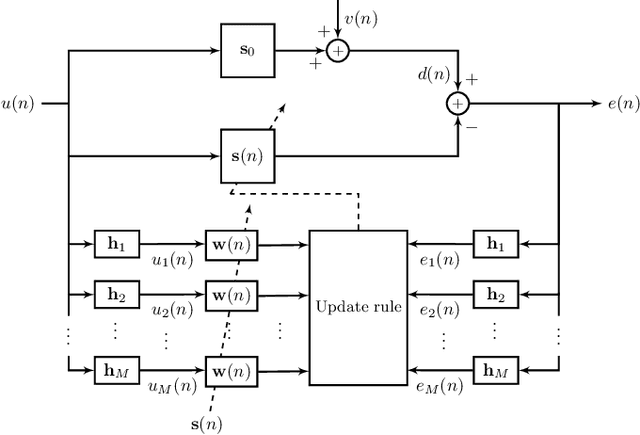
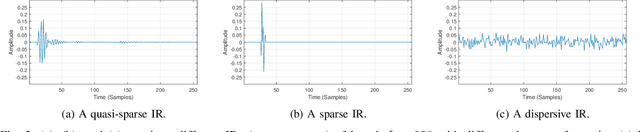
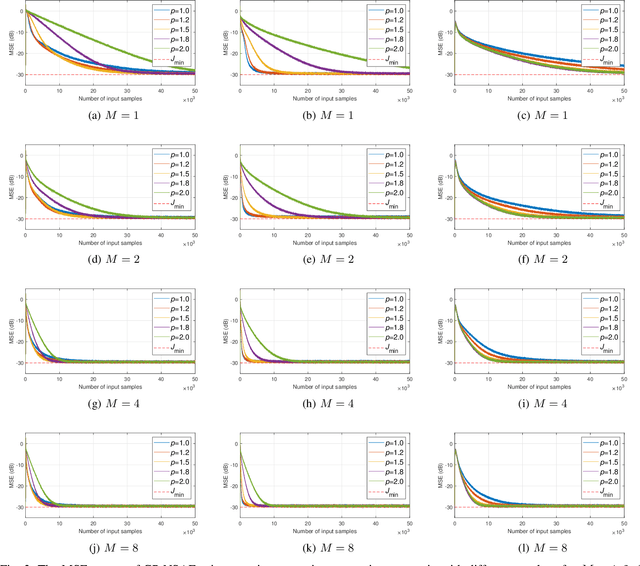

We show that a new design criterion, i.e., the least squares on subband errors regularized by a weighted norm, can be used to generalize the proportionate-type normalized subband adaptive filtering (PtNSAF) framework. The new criterion directly penalizes subband errors and includes a sparsity penalty term which is minimized using the damped regularized Newton's method. The impact of the proposed generalized PtNSAF (GPtNSAF) is studied for the system identification problem via computer simulations. Specifically, we study the effects of using different numbers of subbands and various sparsity penalty terms for quasi-sparse, sparse, and dispersive systems. The results show that the benefit of increasing the number of subbands is larger than promoting sparsity of the estimated filter coefficients when the target system is quasi-sparse or dispersive. On the other hand, for sparse target systems, promoting sparsity becomes more important. More importantly, the two aspects provide complementary and additive benefits to the GPtNSAF for speeding up convergence.
ResNEsts and DenseNEsts: Block-based DNN Models with Improved Representation Guarantees
Nov 10, 2021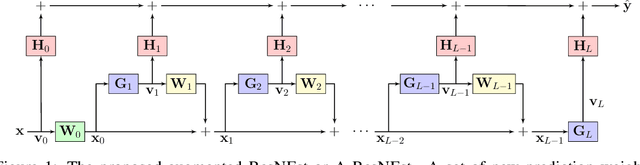


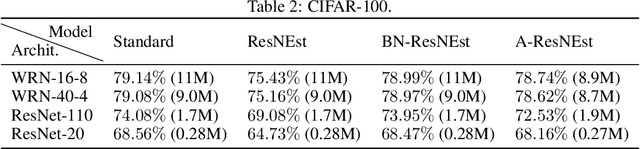
Models recently used in the literature proving residual networks (ResNets) are better than linear predictors are actually different from standard ResNets that have been widely used in computer vision. In addition to the assumptions such as scalar-valued output or single residual block, these models have no nonlinearities at the final residual representation that feeds into the final affine layer. To codify such a difference in nonlinearities and reveal a linear estimation property, we define ResNEsts, i.e., Residual Nonlinear Estimators, by simply dropping nonlinearities at the last residual representation from standard ResNets. We show that wide ResNEsts with bottleneck blocks can always guarantee a very desirable training property that standard ResNets aim to achieve, i.e., adding more blocks does not decrease performance given the same set of basis elements. To prove that, we first recognize ResNEsts are basis function models that are limited by a coupling problem in basis learning and linear prediction. Then, to decouple prediction weights from basis learning, we construct a special architecture termed augmented ResNEst (A-ResNEst) that always guarantees no worse performance with the addition of a block. As a result, such an A-ResNEst establishes empirical risk lower bounds for a ResNEst using corresponding bases. Our results demonstrate ResNEsts indeed have a problem of diminishing feature reuse; however, it can be avoided by sufficiently expanding or widening the input space, leading to the above-mentioned desirable property. Inspired by the DenseNets that have been shown to outperform ResNets, we also propose a corresponding new model called Densely connected Nonlinear Estimator (DenseNEst). We show that any DenseNEst can be represented as a wide ResNEst with bottleneck blocks. Unlike ResNEsts, DenseNEsts exhibit the desirable property without any special architectural re-design.