 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Wake-up or Not to Wake-up: Reducing Keyword False Alarm by Successive Refinement
Paper and Code
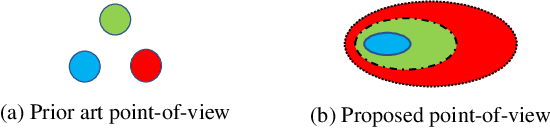
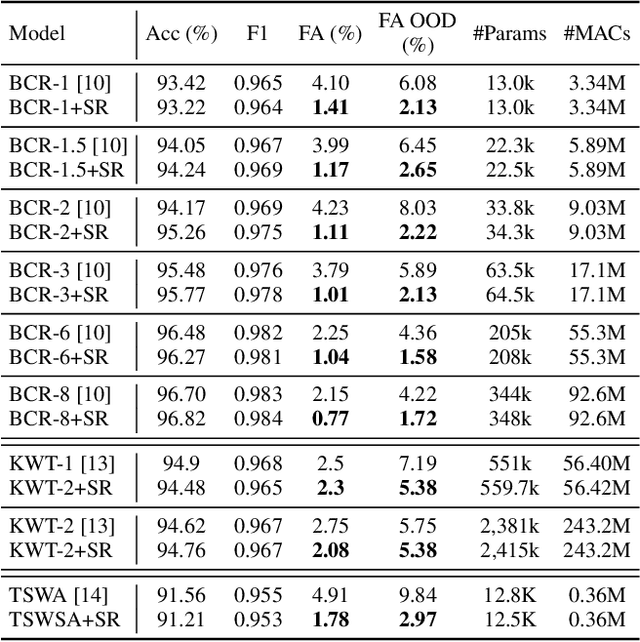
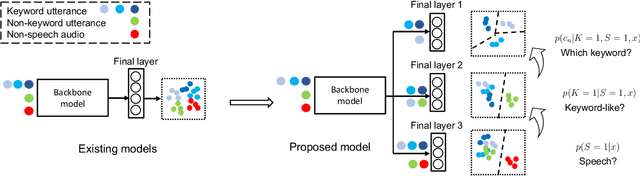
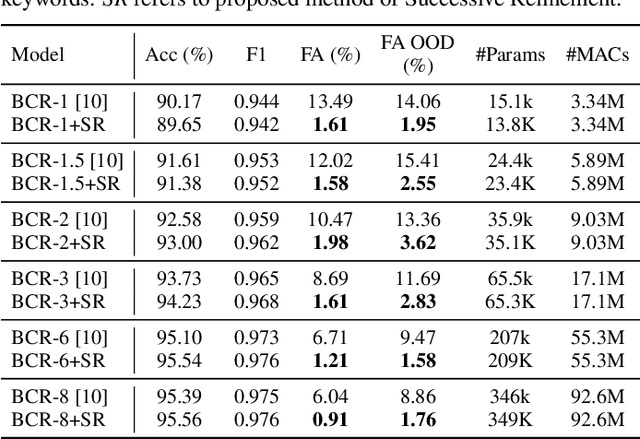
Keyword spotting systems continuously process audio streams to detect keywords. One of the most challenging tasks in designing such systems is to reduce False Alarm (FA) which happens when the system falsely registers a keyword despite the keyword not being uttered. In this paper, we propose a simple yet elegant solution to this problem that follows from the law of total probability. We show that existing deep keyword spotting mechanisms can be improved by Successive Refinement, where the system first classifies whether the input audio is speech or not, followed by whether the input is keyword-like or not, and finally classifies which keyword was uttered. We show across multiple models with size ranging from 13K parameters to 2.41M parameters, the successive refinement technique reduces FA by up to a factor of 8 on in-domain held-out FA data, and up to a factor of 7 on out-of-domain (OOD) FA data. Further, our proposed approach is "plug-and-play" and can be applied to any deep keyword spotting model.