 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOYAGER: A Training Free Approach for Generating Diverse Datasets using LLMs
Dec 12, 2025Large language models (LLMs) are increasingly being used to generate synthetic datasets for the evaluation and training of downstream models. However, prior work has noted that such generated data lacks diversity. In this paper, we propose Voyager, a novel principled approach to generate diverse datasets. Our approach is iterative and directly optimizes a mathematical quantity that optimizes the diversity of the dataset using the machinery of determinantal point processes. Furthermore, our approach is training-free, applicable to closed-source models, and scalable. In addition to providing theoretical justification for the working of our method, we also demonstrate through comprehensive experiments that Voyager significantly outperforms popular baseline approaches by providing a 1.5-3x improvement in diversity.
RestoreGrad: Signal Restoration Using Conditional Denoising Diffusion Models with Jointly Learned Prior
Feb 19, 2025Denoising diffusion probabilistic models (DDPMs) can be utilized for recovering a clean signal from its degraded observation(s) by conditioning the model on the degraded signal. The degraded signals are themselves contaminated versions of the clean signals; due to this correlation, they may encompass certain useful information about the target clean data distribution. However, existing adoption of the standard Gaussian as the prior distribution in turn discards such information, resulting in sub-optimal performance. In this paper, we propose to improve conditional DDPMs for signal restoration by leveraging a more informative prior that is jointly learned with the diffusion model. The proposed framework, called RestoreGrad, seamlessly integrates DDPMs into the variational autoencoder framework and exploits the correlation between the degraded and clean signals to encode a better diffusion prior. On speech and image restoration tasks, we show that RestoreGrad demonstrates faster convergence (5-10 times fewer training steps) to achieve better quality of restored signals over existing DDPM baselines, and improved robustness to using fewer sampling steps in inference time (2-2.5 times fewer), advocating the advantages of leveraging jointly learned prior for efficiency improvements in the diffusion process.
CWCL: Cross-Modal Transfer with Continuously Weighted Contrastive Loss
Sep 26, 2023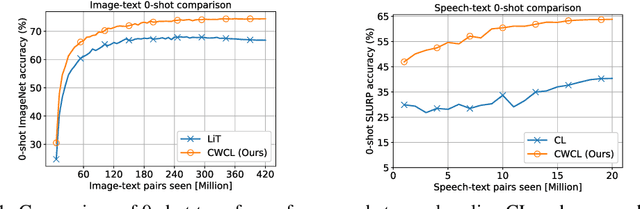
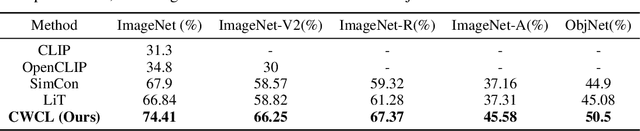
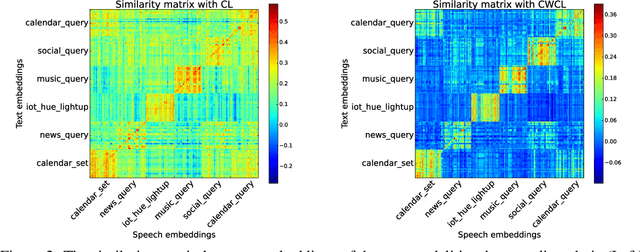

This paper considers contrastive training for cross-modal 0-shot transfer wherein a pre-trained model in one modality is used for representation learning in another domain using pairwise data. The learnt models in the latter domain can then be used for a diverse set of tasks in a zero-shot way, similar to ``Contrastive Language-Image Pre-training (CLIP)'' and ``Locked-image Tuning (LiT)'' that have recently gained considerable attention. Most existing works for cross-modal representation alignment (including CLIP and LiT) use the standard contrastive training objective, which employs sets of positive and negative examples to align similar and repel dissimilar training data samples. However, similarity amongst training examples has a more continuous nature, thus calling for a more `non-binary' treatment. To address this, we propose a novel loss function called Continuously Weighted Contrastive Loss (CWCL) that employs a continuous measure of similarity. With CWCL, we seek to align the embedding space of one modality with another. Owing to the continuous nature of similarity in the proposed loss function, these models outperform existing methods for 0-shot transfer across multiple models, datasets and modalities. Particularly, we consider the modality pairs of image-text and speech-text and our models achieve 5-8% (absolute) improvement over previous state-of-the-art methods in 0-shot image classification and 20-30% (absolute) improvement in 0-shot speech-to-intent classification and keyword classification.
To Wake-up or Not to Wake-up: Reducing Keyword False Alarm by Successive Refinement
Apr 06, 2023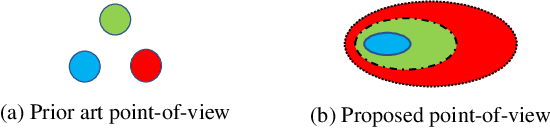
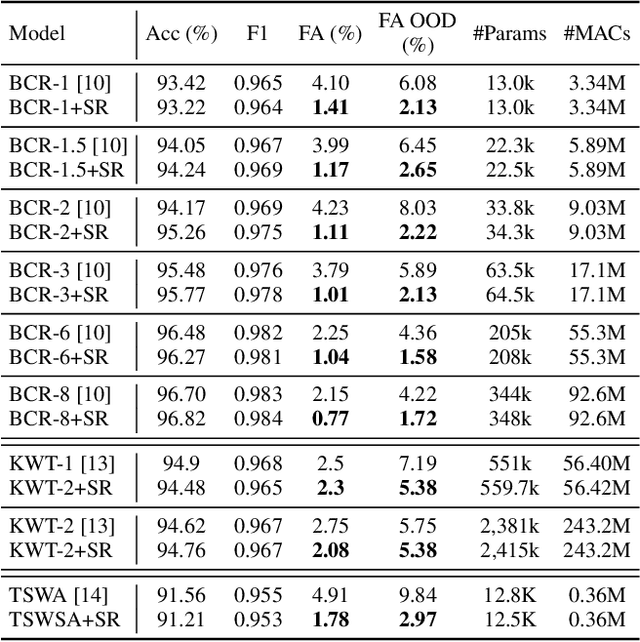
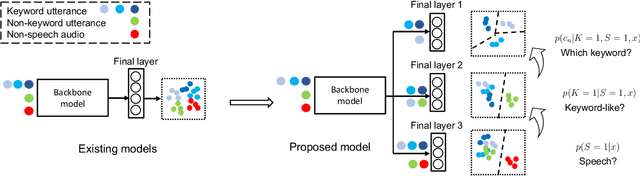
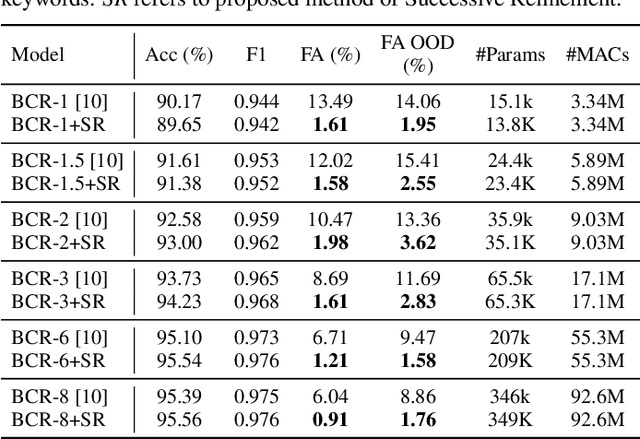
Keyword spotting systems continuously process audio streams to detect keywords. One of the most challenging tasks in designing such systems is to reduce False Alarm (FA) which happens when the system falsely registers a keyword despite the keyword not being uttered. In this paper, we propose a simple yet elegant solution to this problem that follows from the law of total probability. We show that existing deep keyword spotting mechanisms can be improved by Successive Refinement, where the system first classifies whether the input audio is speech or not, followed by whether the input is keyword-like or not, and finally classifies which keyword was uttered. We show across multiple models with size ranging from 13K parameters to 2.41M parameters, the successive refinement technique reduces FA by up to a factor of 8 on in-domain held-out FA data, and up to a factor of 7 on out-of-domain (OOD) FA data. Further, our proposed approach is "plug-and-play" and can be applied to any deep keyword spotting model.
A Machine Learning Framework for Distributed Functional Compression over Wireless Channels in IoT
Jan 24, 2022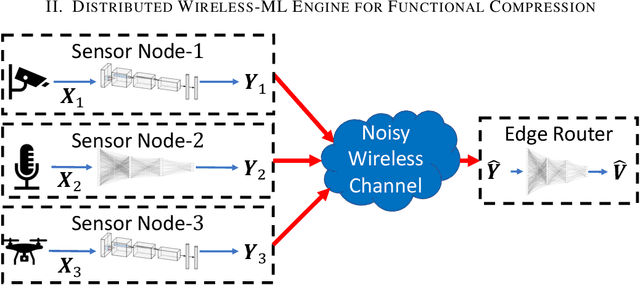
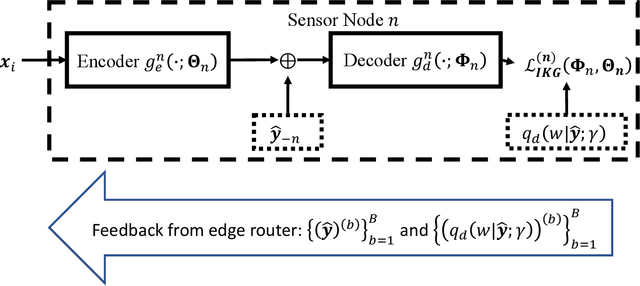
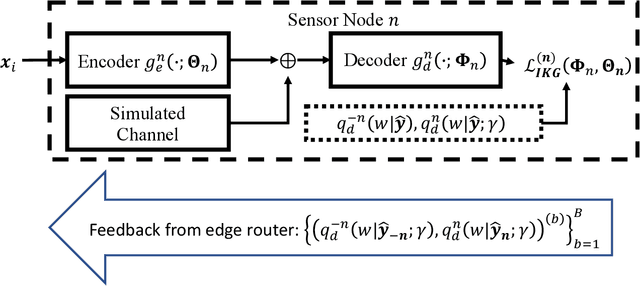

IoT devices generating enormous data and state-of-the-art machine learning techniques together will revolutionize cyber-physical systems. In many diverse fields, from autonomous driving to augmented reality, distributed IoT devices compute specific target functions without simple forms like obstacle detection, object recognition, etc. Traditional cloud-based methods that focus on transferring data to a central location either for training or inference place enormous strain on network resources. To address this, we develop, to the best of our knowledge, the first machine learning framework for distributed functional compression over both the Gaussian Multiple Access Channel (GMAC) and orthogonal AWGN channels. Due to the Kolmogorov-Arnold representation theorem, our machine learning framework can, by design, compute any arbitrary function for the desired functional compression task in IoT. Importantly the raw sensory data are never transferred to a central node for training or inference, thus reducing communication. For these algorithms, we provide theoretical convergence guarantees and upper bounds on communication. Our simulations show that the learned encoders and decoders for functional compression perform significantly better than traditional approaches, are robust to channel condition changes and sensor outages. Compared to the cloud-based scenario, our algorithms reduce channel use by two orders of magnitude.