 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
A Thorough Examination on Zero-shot Dense Retrieval
Apr 27, 2022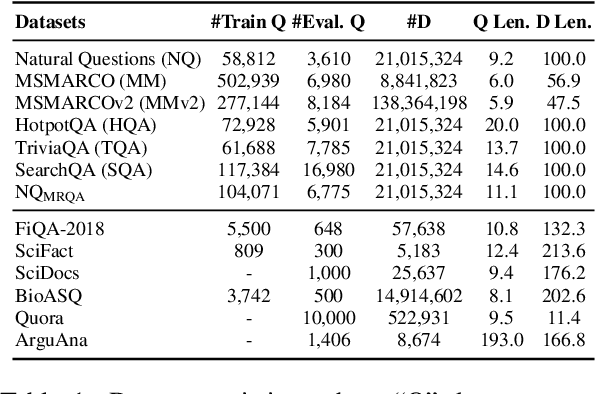
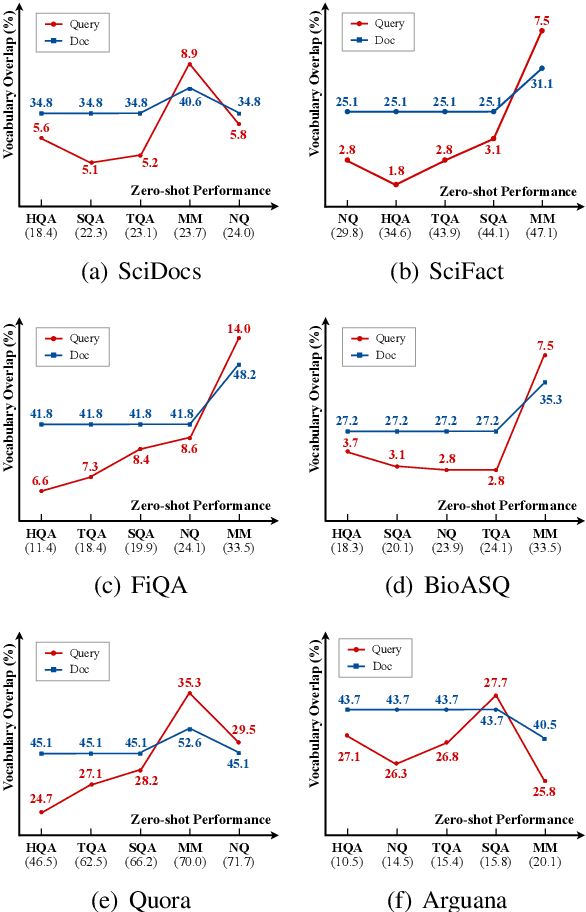
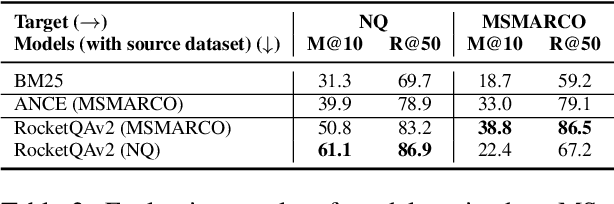
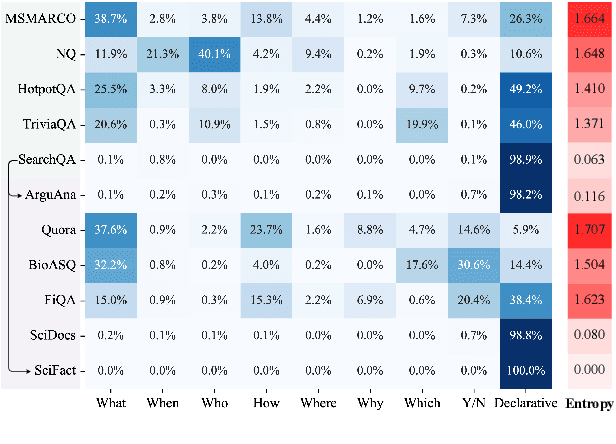
Recent years have witnessed the significant advance in dense retrieval (DR) based on powerful pre-trained language models (PLM). DR models have achieved excellent performance in several benchmark datasets, while they are shown to be not as competitive as traditional sparse retrieval models (e.g., BM25) in a zero-shot retrieval setting. However, in the related literature, there still lacks a detailed and comprehensive study on zero-shot retrieval. In this paper, we present the first thorough examination of the zero-shot capability of DR models. We aim to identify the key factors and analyze how they affect zero-shot retrieval performance. In particular, we discuss the effect of several key factors related to source training set, analyze the potential bias from the target dataset, and review and compare existing zero-shot DR models. Our findings provide important evidence to better understand and develop zero-shot DR models.