 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNADIR: Differential Attention Flow for Non-Autoregressive Transliteration in Indic Languages
Jan 18, 2026In this work, we argue that not all sequence-to-sequence tasks require the strong inductive biases of autoregressive (AR) models. Tasks like multilingual transliteration, code refactoring, grammatical correction or text normalization often rely on local dependencies where the full modeling capacity of AR models can be overkill, creating a trade-off between their high accuracy and high inference latency. While non-autoregressive (NAR) models offer speed, they typically suffer from hallucinations and poor length control. To explore this trade-off, we focus on the multilingual transliteration task in Indic languages and introduce NADIR, a novel NAR architecture designed to strike a balance between speed and accuracy. NADIR integrates a Differential Transformer and a Mixture-of-Experts mechanism, enabling it to robustly model complex character mappings without sequential dependencies. NADIR achieves over a 13x speed-up compared to the state-of-the-art AR baseline. It maintains a competitive mean Character Error Rate of 15.78%, compared to 14.44% for the AR model and 21.88% for a standard NAR equivalent. Importantly, NADIR reduces Repetition errors by 49.53%, Substitution errors by 24.45%, Omission errors by 32.92%, and Insertion errors by 16.87%. This work provides a practical blueprint for building fast and reliable NAR systems, effectively bridging the gap between AR accuracy and the demands of real-time, large-scale deployment.
Recommending the right academic programs: An interest mining approach using BERTopic
Jan 11, 2025



Prospective students face the challenging task of selecting a university program that will shape their academic and professional careers. For decision-makers and support services, it is often time-consuming and extremely difficult to match personal interests with suitable programs due to the vast and complex catalogue information available. This paper presents the first information system that provides students with efficient recommendations based on both program content and personal preferences. BERTopic, a powerful topic modeling algorithm, is used that leverages text embedding techniques to generate topic representations. It enables us to mine interest topics from all course descriptions, representing the full body of knowledge taught at the institution. Underpinned by the student's individual choice of topics, a shortlist of the most relevant programs is computed through statistical backtracking in the knowledge map, a novel characterization of the program-course relationship. This approach can be applied to a wide range of educational settings, including professional and vocational training. A case study at a post-secondary school with 80 programs and over 5,000 courses shows that the system provides immediate and effective decision support. The presented interest topics are meaningful, leading to positive effects such as serendipity, personalization, and fairness, as revealed by a qualitative study involving 65 students. Over 98% of users indicated that the recommendations aligned with their interests, and about 94% stated they would use the tool in the future. Quantitative analysis shows the system can be configured to ensure fairness, achieving 98% program coverage while maintaining a personalization score of 0.77. These findings suggest that this real-time, user-centered, data-driven system could improve the program selection process.
MEETING BOT: Reinforcement Learning for Dialogue Based Meeting Scheduling
Dec 28, 2018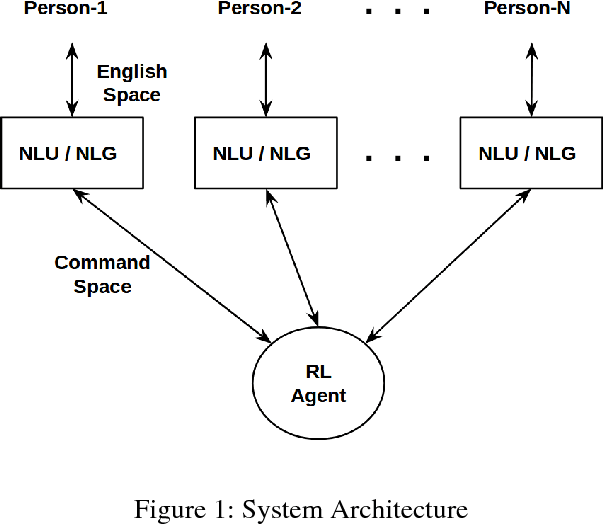
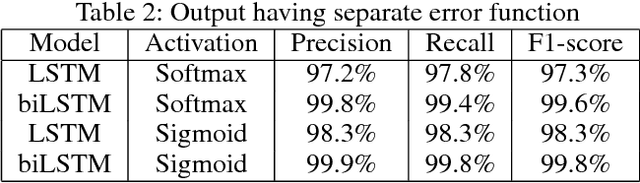
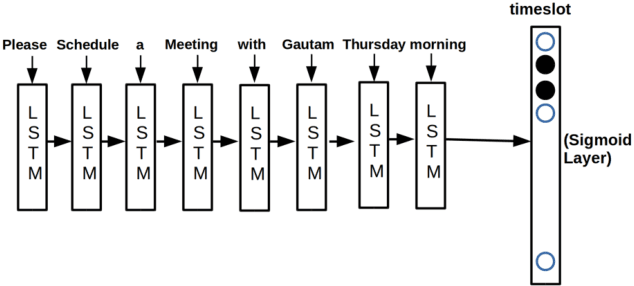
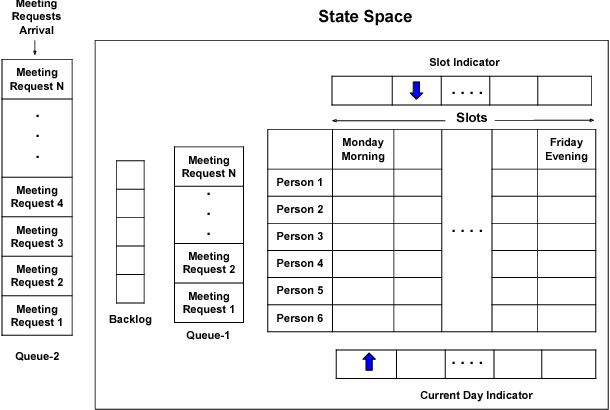
In this paper we present Meeting Bot, a reinforcement learning based conversational system that interacts with multiple users to schedule meetings. The system is able to interpret user utterences and map them to preferred time slots, which are then fed to a reinforcement learning (RL) system with the goal of converging on an agreeable time slot. The RL system is able to adapt to user preferences and environmental changes in meeting arrival rate while still scheduling effectively. Learning is performed via policy gradient with exploration, by utilizing an MLP as an approximator of the policy function. Results demonstrate that the system outperforms standard scheduling algorithms in terms of overall scheduling efficiency. Additionally, the system is able to adapt its strategy to situations when users consistently reject or accept meetings in certain slots (such as Friday afternoon versus Thursday morning), or when the meeting is called by members who are at a more senior designation.
Predicting Remaining Useful Life using Time Series Embeddings based on Recurrent Neural Networks
Oct 06, 2017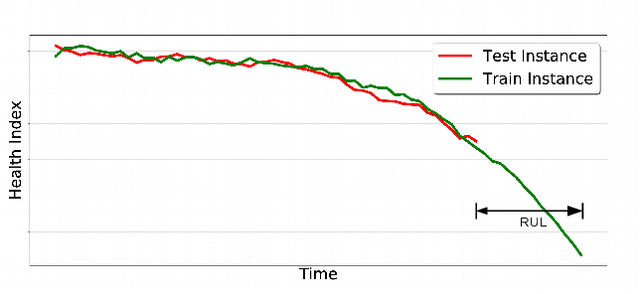



We consider the problem of estimating the remaining useful life (RUL) of a system or a machine from sensor data. Many approaches for RUL estimation based on sensor data make assumptions about how machines degrade. Additionally, sensor data from machines is noisy and often suffers from missing values in many practical settings. We propose Embed-RUL: a novel approach for RUL estimation from sensor data that does not rely on any degradation-trend assumptions, is robust to noise, and handles missing values. Embed-RUL utilizes a sequence-to-sequence model based on Recurrent Neural Networks (RNNs) to generate embeddings for multivariate time series subsequences. The embeddings for normal and degraded machines tend to be different, and are therefore found to be useful for RUL estimation. We show that the embeddings capture the overall pattern in the time series while filtering out the noise, so that the embeddings of two machines with similar operational behavior are close to each other, even when their sensor readings have significant and varying levels of noise content. We perform experiments on publicly available turbofan engine dataset and a proprietary real-world dataset, and demonstrate that Embed-RUL outperforms the previously reported state-of-the-art on several metrics.
TimeNet: Pre-trained deep recurrent neural network for time series classification
Jun 23, 2017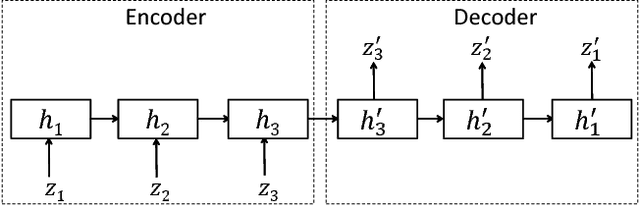


Inspired by the tremendous success of deep Convolutional Neural Networks as generic feature extractors for images, we propose TimeNet: a deep recurrent neural network (RNN) trained on diverse time series in an unsupervised manner using sequence to sequence (seq2seq) models to extract features from time series. Rather than relying on data from the problem domain, TimeNet attempts to generalize time series representation across domains by ingesting time series from several domains simultaneously. Once trained, TimeNet can be used as a generic off-the-shelf feature extractor for time series. The representations or embeddings given by a pre-trained TimeNet are found to be useful for time series classification (TSC). For several publicly available datasets from UCR TSC Archive and an industrial telematics sensor data from vehicles, we observe that a classifier learned over the TimeNet embeddings yields significantly better performance compared to (i) a classifier learned over the embeddings given by a domain-specific RNN, as well as (ii) a nearest neighbor classifier based on Dynamic Time Warping.
Deep Convolutional Neural Networks for Pairwise Causality
Jan 03, 2017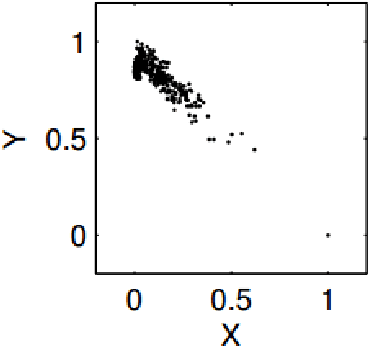



Discovering causal models from observational and interventional data is an important first step preceding what-if analysis or counterfactual reasoning. As has been shown before, the direction of pairwise causal relations can, under certain conditions, be inferred from observational data via standard gradient-boosted classifiers (GBC) using carefully engineered statistical features. In this paper we apply deep convolutional neural networks (CNNs) to this problem by plotting attribute pairs as 2-D scatter plots that are fed to the CNN as images. We evaluate our approach on the 'Cause- Effect Pairs' NIPS 2013 Data Challenge. We observe that a weighted ensemble of CNN with the earlier GBC approach yields significant improvement. Further, we observe that when less training data is available, our approach performs better than the GBC based approach suggesting that CNN models pre-trained to determine the direction of pairwise causal direction could have wider applicability in causal discovery and enabling what-if or counterfactual analysis.
Neuro-symbolic EDA-based Optimisation using ILP-enhanced DBNs
Dec 20, 2016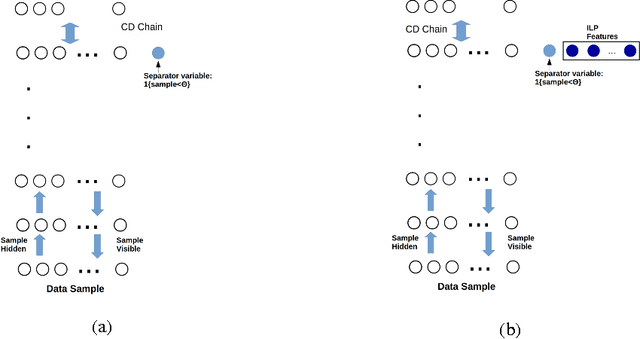
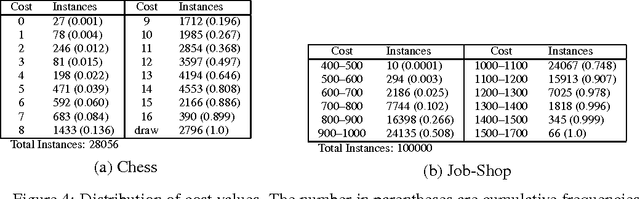
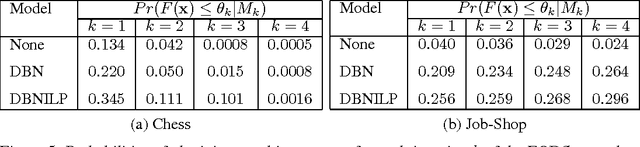
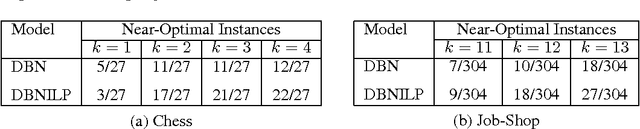
We investigate solving discrete optimisation problems using the estimation of distribution (EDA) approach via a novel combination of deep belief networks(DBN) and inductive logic programming (ILP).While DBNs are used to learn the structure of successively better feasible solutions,ILP enables the incorporation of domain-based background knowledge related to the goodness of solutions.Recent work showed that ILP could be an effective way to use domain knowledge in an EDA scenario.However,in a purely ILP-based EDA,sampling successive populations is either inefficient or not straightforward.In our Neuro-symbolic EDA,an ILP engine is used to construct a model for good solutions using domain-based background knowledge.These rules are introduced as Boolean features in the last hidden layer of DBNs used for EDA-based optimization.This incorporation of logical ILP features requires some changes while training and sampling from DBNs: (a)our DBNs need to be trained with data for units at the input layer as well as some units in an otherwise hidden layer, and (b)we would like the samples generated to be drawn from instances entailed by the logical model.We demonstrate the viability of our approach on instances of two optimisation problems: predicting optimal depth-of-win for the KRK endgame,and jobshop scheduling.Our results are promising: (i)On each iteration of distribution estimation,samples obtained with an ILP-assisted DBN have a substantially greater proportion of good solutions than samples generated using a DBN without ILP features, and (ii)On termination of distribution estimation,samples obtained using an ILP-assisted DBN contain more near-optimal samples than samples from a DBN without ILP features.These results suggest that the use of ILP-constructed theories could be useful for incorporating complex domain-knowledge into deep models for estimation of distribution based procedures.
Generation of Near-Optimal Solutions Using ILP-Guided Sampling
Nov 11, 2016


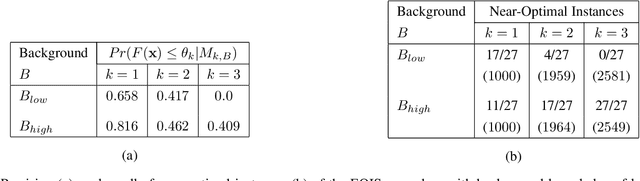
Our interest in this paper is in optimisation problems that are intractable to solve by direct numerical optimisation, but nevertheless have significant amounts of relevant domain-specific knowledge. The category of heuristic search techniques known as estimation of distribution algorithms (EDAs) seek to incrementally sample from probability distributions in which optimal (or near-optimal) solutions have increasingly higher probabilities. Can we use domain knowledge to assist the estimation of these distributions? To answer this in the affirmative, we need: (a)a general-purpose technique for the incorporation of domain knowledge when constructing models for optimal values; and (b)a way of using these models to generate new data samples. Here we investigate a combination of the use of Inductive Logic Programming (ILP) for (a), and standard logic-programming machinery to generate new samples for (b). Specifically, on each iteration of distribution estimation, an ILP engine is used to construct a model for good solutions. The resulting theory is then used to guide the generation of new data instances, which are now restricted to those derivable using the ILP model in conjunction with the background knowledge). We demonstrate the approach on two optimisation problems (predicting optimal depth-of-win for the KRK endgame, and job-shop scheduling). Our results are promising: (a)On each iteration of distribution estimation, samples obtained with an ILP theory have a substantially greater proportion of good solutions than samples without a theory; and (b)On termination of distribution estimation, samples obtained with an ILP theory contain more near-optimal samples than samples without a theory. Taken together, these results suggest that the use of ILP-constructed theories could be a useful technique for incorporating complex domain-knowledge into estimation distribution procedures.
Multi-Sensor Prognostics using an Unsupervised Health Index based on LSTM Encoder-Decoder
Aug 22, 2016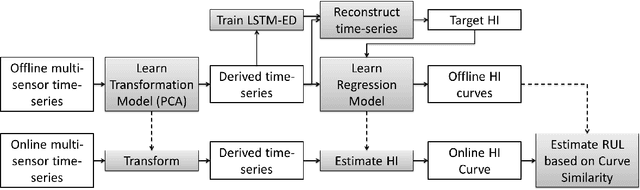
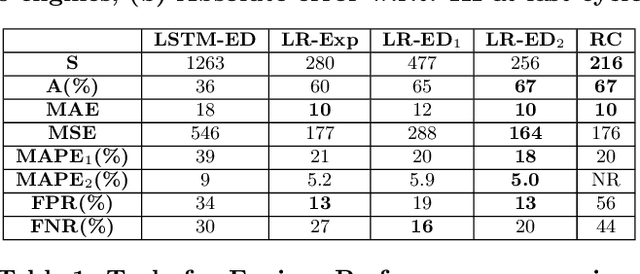
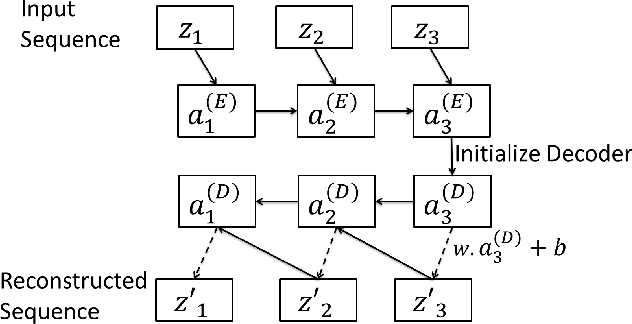
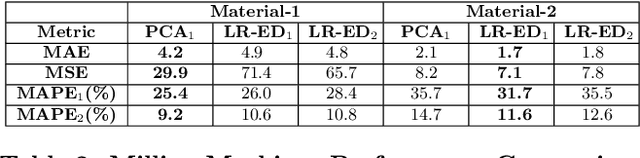
Many approaches for estimation of Remaining Useful Life (RUL) of a machine, using its operational sensor data, make assumptions about how a system degrades or a fault evolves, e.g., exponential degradation. However, in many domains degradation may not follow a pattern. We propose a Long Short Term Memory based Encoder-Decoder (LSTM-ED) scheme to obtain an unsupervised health index (HI) for a system using multi-sensor time-series data. LSTM-ED is trained to reconstruct the time-series corresponding to healthy state of a system. The reconstruction error is used to compute HI which is then used for RUL estimation. We evaluate our approach on publicly available Turbofan Engine and Milling Machine datasets. We also present results on a real-world industry dataset from a pulverizer mill where we find significant correlation between LSTM-ED based HI and maintenance costs.
LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection
Jul 11, 2016
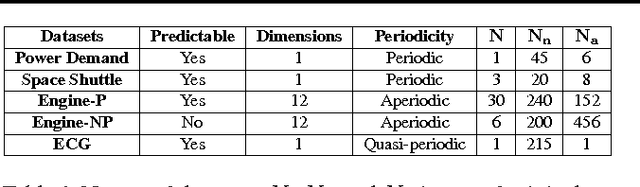
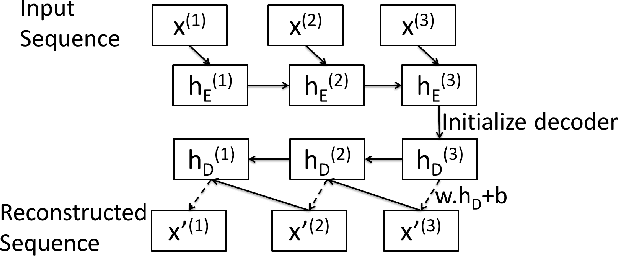
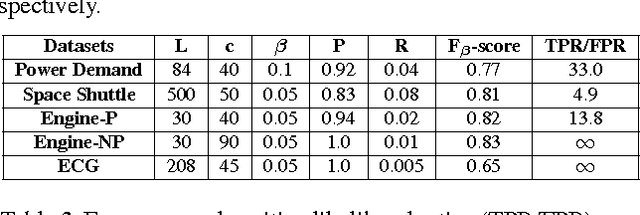
Mechanical devices such as engines, vehicles, aircrafts, etc., are typically instrumented with numerous sensors to capture the behavior and health of the machine. However, there are often external factors or variables which are not captured by sensors leading to time-series which are inherently unpredictable. For instance, manual controls and/or unmonitored environmental conditions or load may lead to inherently unpredictable time-series. Detecting anomalies in such scenarios becomes challenging using standard approaches based on mathematical models that rely on stationarity, or prediction models that utilize prediction errors to detect anomalies. We propose a Long Short Term Memory Networks based Encoder-Decoder scheme for Anomaly Detection (EncDec-AD) that learns to reconstruct 'normal' time-series behavior, and thereafter uses reconstruction error to detect anomalies. We experiment with three publicly available quasi predictable time-series datasets: power demand, space shuttle, and ECG, and two real-world engine datasets with both predictive and unpredictable behavior. We show that EncDec-AD is robust and can detect anomalies from predictable, unpredictable, periodic, aperiodic, and quasi-periodic time-series. Further, we show that EncDec-AD is able to detect anomalies from short time-series (length as small as 30) as well as long time-series (length as large as 500).