 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
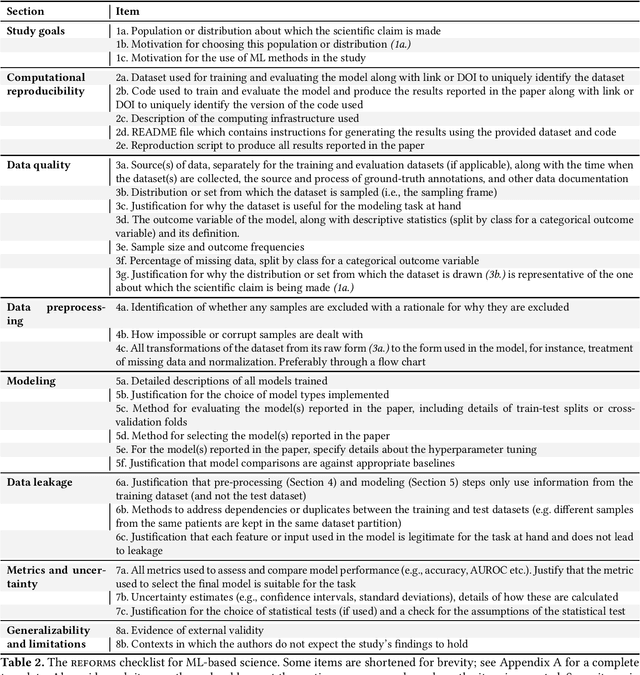
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
The worst of both worlds: A comparative analysis of errors in learning from data in psychology and machine learning
Apr 06, 2022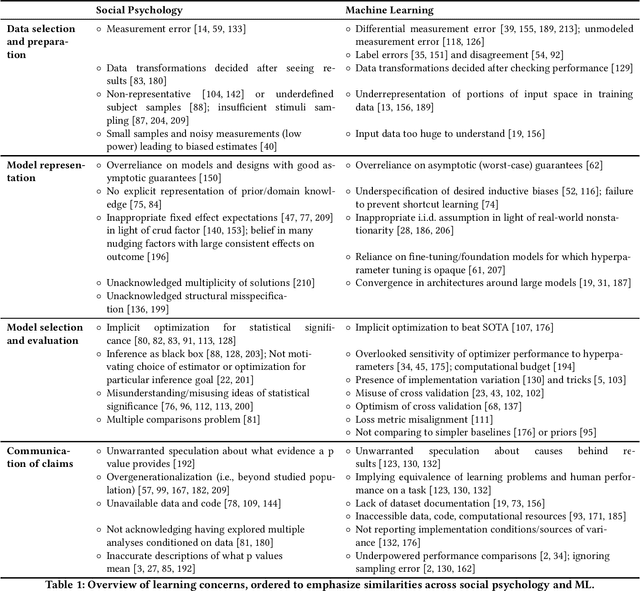
Recent concerns that machine learning (ML) may be facing a reproducibility and replication crisis suggest that some published claims in ML research cannot be taken at face value. These concerns inspire analogies to the replication crisis affecting the social and medical sciences, as well as calls for greater integration of statistical approaches to causal inference and predictive modeling. A deeper understanding of what reproducibility concerns in research in supervised ML have in common with the replication crisis in experimental science can put the new concerns in perspective, and help researchers avoid "the worst of both worlds" that can emerge when ML researchers begin borrowing methodologies from explanatory modeling without understanding their limitations, and vice versa. We contribute a comparative analysis of concerns about inductive learning that arise in different stages of the modeling pipeline in causal attribution as exemplified in psychology versus predictive modeling as exemplified by ML. We identify themes that re-occur in reform discussions like overreliance on asymptotic theory and non-credible beliefs about real-world data generating processes. We argue that in both fields, claims from learning are implied to generalize outside the specific environment studied (e.g., the input dataset or subject sample, modeling implementation, etc.) but are often impossible to refute due to forms of underspecification. In particular, many errors being acknowledged in ML expose cracks in long-held beliefs that optimizing predictive accuracy using huge datasets absolves one from having to make assumptions about the underlying data generating process. We conclude by discussing rhetorical risks like error misdiagnosis that arise in times of methodological uncertainty.