 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improved Semiconductor Defect Inspection for high-NA EUVL based on SEMI-SuperYOLO-NAS
Apr 08, 2024Due to potential pitch reduction, the semiconductor industry is adopting High-NA EUVL technology. However, its low depth of focus presents challenges for High Volume Manufacturing. To address this, suppliers are exploring thinner photoresists and new underlayers/hardmasks. These may suffer from poor SNR, complicating defect detection. Vision-based ML algorithms offer a promising solution for semiconductor defect inspection. However, developing a robust ML model across various image resolutions without explicit training remains a challenge for nano-scale defect inspection. This research's goal is to propose a scale-invariant ADCD framework capable to upscale images, addressing this issue. We propose an improvised ADCD framework as SEMI-SuperYOLO-NAS, which builds upon the baseline YOLO-NAS architecture. This framework integrates a SR assisted branch to aid in learning HR features by the defect detection backbone, particularly for detecting nano-scale defect instances from LR images. Additionally, the SR-assisted branch can recursively generate upscaled images from their corresponding downscaled counterparts, enabling defect detection inference across various image resolutions without requiring explicit training. Moreover, we investigate improved data augmentation strategy aimed at generating diverse and realistic training datasets to enhance model performance. We have evaluated our proposed approach using two original FAB datasets obtained from two distinct processes and captured using two different imaging tools. Finally, we demonstrate zero-shot inference for our model on a new, originating from a process condition distinct from the training dataset and possessing different Pitch characteristics. Experimental validation demonstrates that our proposed ADCD framework aids in increasing the throughput of imaging tools for defect inspection by reducing the required image pixel resolutions.
Deep learning denoiser assisted roughness measurements extraction from thin resists with low Signal-to-Noise Ratio(SNR) SEM images: analysis with SMILE
Oct 23, 2023The technological advance of High Numerical Aperture Extreme Ultraviolet Lithography (High NA EUVL) has opened the gates to extensive researches on thinner photoresists (below 30nm), necessary for the industrial implementation of High NA EUVL. Consequently, images from Scanning Electron Microscopy (SEM) suffer from reduced imaging contrast and low Signal-to-Noise Ratio (SNR), impacting the measurement of unbiased Line Edge Roughness (uLER) and Line Width Roughness (uLWR). Thus, the aim of this work is to enhance the SNR of SEM images by using a Deep Learning denoiser and enable robust roughness extraction of the thin resist. For this study, we acquired SEM images of Line-Space (L/S) patterns with a Chemically Amplified Resist (CAR) with different thicknesses (15nm, 20nm, 25nm, 30nm), underlayers (Spin-On-Glass-SOG, Organic Underlayer-OUL) and frames of averaging (4, 8, 16, 32, and 64 Fr). After denoising, a systematic analysis has been carried out on both noisy and denoised images using an open-source metrology software, SMILE 2.3.2, for investigating mean CD, SNR improvement factor, biased and unbiased LWR/LER Power Spectral Density (PSD). Denoised images with lower number of frames present unaltered Critical Dimensions (CDs), enhanced SNR (especially for low number of integration frames), and accurate measurements of uLER and uLWR, with the same accuracy as for noisy images with a consistent higher number of frames. Therefore, images with a small number of integration frames and with SNR < 2 can be successfully denoised, and advantageously used in improving metrology throughput while maintaining reliable roughness measurements for the thin resist.
Deep Learning based Defect classification and detection in SEM images: A Mask R-CNN approach
Nov 03, 2022In this research work, we have demonstrated the application of Mask-RCNN (Regional Convolutional Neural Network), a deep-learning algorithm for computer vision and specifically object detection, to semiconductor defect inspection domain. Stochastic defect detection and classification during semiconductor manufacturing has grown to be a challenging task as we continuously shrink circuit pattern dimensions (e.g., for pitches less than 32 nm). Defect inspection and analysis by state-of-the-art optical and e-beam inspection tools is generally driven by some rule-based techniques, which in turn often causes to misclassification and thereby necessitating human expert intervention. In this work, we have revisited and extended our previous deep learning-based defect classification and detection method towards improved defect instance segmentation in SEM images with precise extent of defect as well as generating a mask for each defect category/instance. This also enables to extract and calibrate each segmented mask and quantify the pixels that make up each mask, which in turn enables us to count each categorical defect instances as well as to calculate the surface area in terms of pixels. We are aiming at detecting and segmenting different types of inter-class stochastic defect patterns such as bridge, break, and line collapse as well as to differentiate accurately between intra-class multi-categorical defect bridge scenarios (as thin/single/multi-line/horizontal/non-horizontal) for aggressive pitches as well as thin resists (High NA applications). Our proposed approach demonstrates its effectiveness both quantitatively and qualitatively.
Relational Constraints for Metric Learning on Relational Data
Jul 02, 2018



Most of metric learning approaches are dedicated to be applied on data described by feature vectors, with some notable exceptions such as times series, trees or graphs. The objective of this paper is to propose a metric learning algorithm that specifically considers relational data. The proposed approach can take benefit from both the topological structure of the data and supervised labels. For selecting relative constraints representing the relational information, we introduce a link-strength function that measures the strength of relationship links between entities by the side-information of their common parents. We show the performance of the proposed method with two different classical metric learning algorithms, which are ITML (Information Theoretic Metric Learning) and LSML (Least Squares Metric Learning), and test on several real-world datasets. Experimental results show that using relational information improves the quality of the learned metric.
Possibilistic Networks: Parameters Learning from Imprecise Data and Evaluation strategy
Jul 13, 2016There has been an ever-increasing interest in multidisciplinary research on representing and reasoning with imperfect data. Possibilistic networks present one of the powerful frameworks of interest for representing uncertain and imprecise information. This paper covers the problem of their parameters learning from imprecise datasets, i.e., containing multi-valued data. We propose in the rst part of this paper a possibilistic networks sampling process. In the second part, we propose a likelihood function which explores the link between random sets theory and possibility theory. This function is then deployed to parametrize possibilistic networks.
Probabilistic Relational Model Benchmark Generation
Mar 02, 2016



The validation of any database mining methodology goes through an evaluation process where benchmarks availability is essential. In this paper, we aim to randomly generate relational database benchmarks that allow to check probabilistic dependencies among the attributes. We are particularly interested in Probabilistic Relational Models (PRMs), which extend Bayesian Networks (BNs) to a relational data mining context and enable effective and robust reasoning over relational data. Even though a panoply of works have focused, separately , on the generation of random Bayesian networks and relational databases, no work has been identified for PRMs on that track. This paper provides an algorithmic approach for generating random PRMs from scratch to fill this gap. The proposed method allows to generate PRMs as well as synthetic relational data from a randomly generated relational schema and a random set of probabilistic dependencies. This can be of interest not only for machine learning researchers to evaluate their proposals in a common framework, but also for databases designers to evaluate the effectiveness of the components of a database management system.
A Survey on Latent Tree Models and Applications
Feb 04, 2014


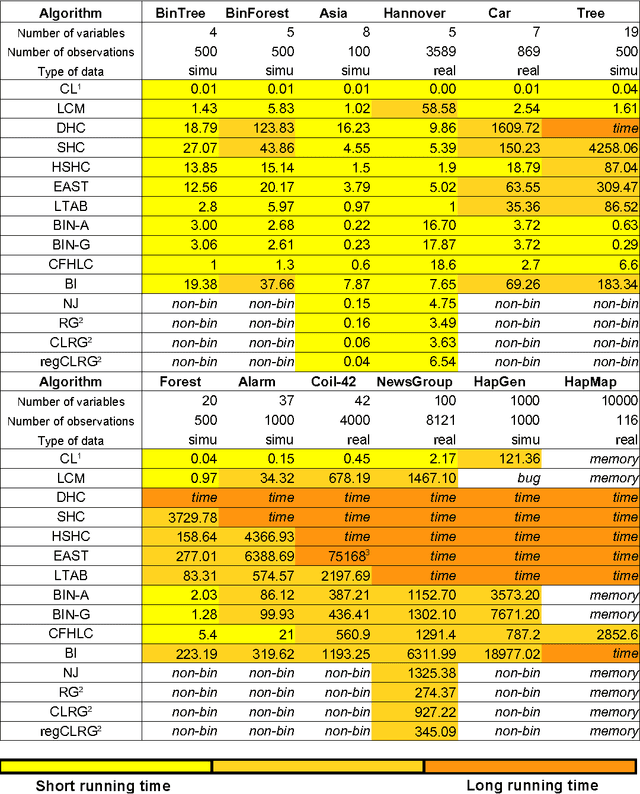
In data analysis, latent variables play a central role because they help provide powerful insights into a wide variety of phenomena, ranging from biological to human sciences. The latent tree model, a particular type of probabilistic graphical models, deserves attention. Its simple structure - a tree - allows simple and efficient inference, while its latent variables capture complex relationships. In the past decade, the latent tree model has been subject to significant theoretical and methodological developments. In this review, we propose a comprehensive study of this model. First we summarize key ideas underlying the model. Second we explain how it can be efficiently learned from data. Third we illustrate its use within three types of applications: latent structure discovery, multidimensional clustering, and probabilistic inference. Finally, we conclude and give promising directions for future researches in this field.