 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and modeling to forecast in time series: a systematic review
Mar 31, 2021



This paper surveys state-of-the-art methods and models dedicated to time series analysis and modeling, with the final aim of prediction. This review aims to offer a structured and comprehensive view of the full process flow, and encompasses time series decomposition, stationary tests, modeling and forecasting. Besides, to meet didactic purposes, a unified presentation has been adopted throughout this survey, to present decomposition frameworks on the one hand and linear and nonlinear time series models on the other hand. First, we decrypt the relationships between stationarity and linearity, and further examine the main classes of methods used to test for weak stationarity. Next, the main frameworks for time series decomposition are presented in a unified way: depending on the time series, a more or less complex decomposition scheme seeks to obtain nonstationary effects (the deterministic components) and a remaining stochastic component. An appropriate modeling of the latter is a critical step to guarantee prediction accuracy. We then present three popular linear models, together with two more flexible variants of the latter. A step further in model complexity, and still in a unified way, we present five major nonlinear models used for time series. Amongst nonlinear models, artificial neural networks hold a place apart as deep learning has recently gained considerable attention. A whole section is therefore dedicated to time series forecasting relying on deep learning approaches. A final section provides a list of R and Python implementations for the methods, models and tests presented throughout this review. In this document, our intention is to bring sufficient in-depth knowledge, while covering a broad range of models and forecasting methods: this compilation spans from well-established conventional approaches to more recent adaptations of deep learning to time series forecasting.
Partially Hidden Markov Chain Linear Autoregressive model: inference and forecasting
Feb 24, 2021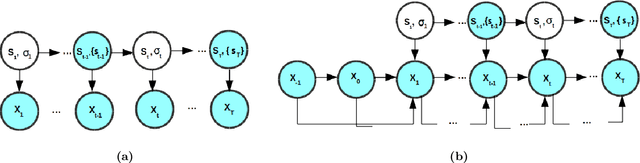
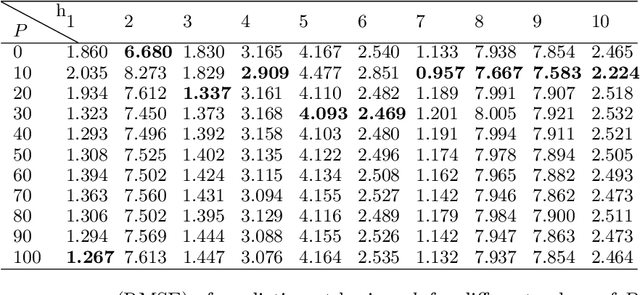
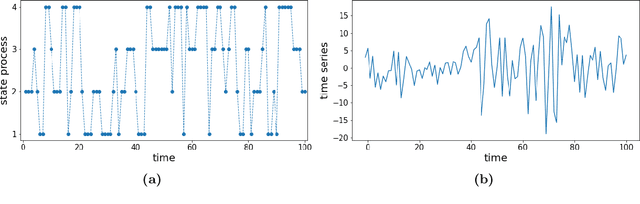
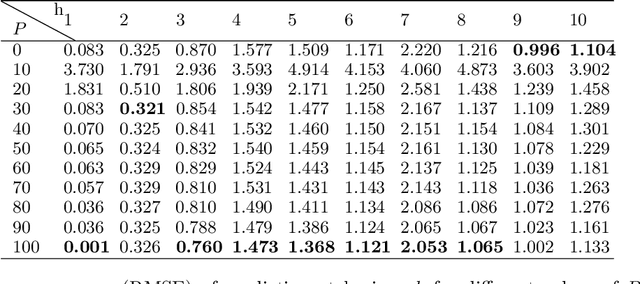
Time series subject to change in regime have attracted much interest in domains such as econometry, finance or meteorology. For discrete-valued regimes, some models such as the popular Hidden Markov Chain (HMC) describe time series whose state process is unknown at all time-steps. Sometimes, time series are firstly labelled thanks to some annotation function. Thus, another category of models handles the case with regimes observed at all time-steps. We present a novel model which addresses the intermediate case: (i) state processes associated to such time series are modelled by Partially Hidden Markov Chains (PHMCs); (ii) a linear autoregressive (LAR) model drives the dynamics of the time series, within each regime. We describe a variant of the expection maximization (EM) algorithm devoted to PHMC-LAR model learning. We propose a hidden state inference procedure and a forecasting function that take into account the observed states when existing. We assess inference and prediction performances, and analyze EM convergence times for the new model, using simulated data. We show the benefits of using partially observed states to decrease EM convergence times. A fully labelled scheme with unreliable labels also speeds up EM. This offers promising prospects to enhance PHMC-LAR model selection. We also point out the robustness of PHMC-LAR to labelling errors in inference task, when large training datasets and moderate labelling error rates are considered. Finally, we highlight the remarkable robustness to error labelling in the prediction task, over the whole range of error rates.
A Survey on Latent Tree Models and Applications
Feb 04, 2014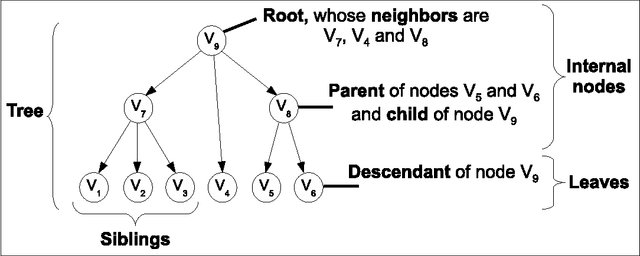


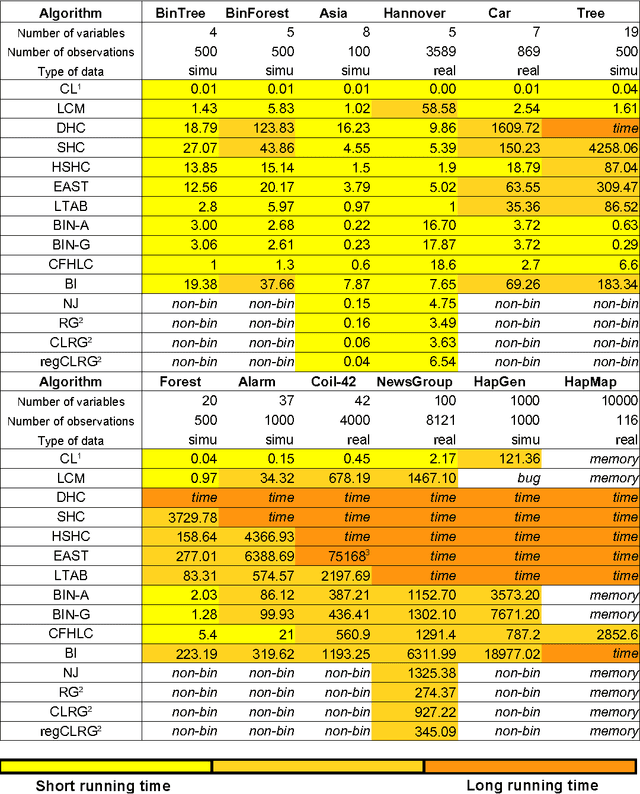
In data analysis, latent variables play a central role because they help provide powerful insights into a wide variety of phenomena, ranging from biological to human sciences. The latent tree model, a particular type of probabilistic graphical models, deserves attention. Its simple structure - a tree - allows simple and efficient inference, while its latent variables capture complex relationships. In the past decade, the latent tree model has been subject to significant theoretical and methodological developments. In this review, we propose a comprehensive study of this model. First we summarize key ideas underlying the model. Second we explain how it can be efficiently learned from data. Third we illustrate its use within three types of applications: latent structure discovery, multidimensional clustering, and probabilistic inference. Finally, we conclude and give promising directions for future researches in this field.