 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Resilient Artificial Intelligence: Survey and Research Issues
Sep 18, 2021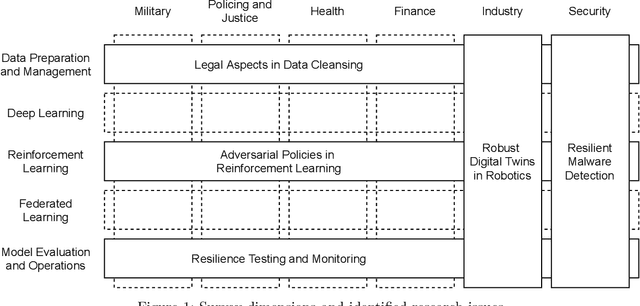
Artificial intelligence (AI) systems are becoming critical components of today's IT landscapes. Their resilience against attacks and other environmental influences needs to be ensured just like for other IT assets. Considering the particular nature of AI, and machine learning (ML) in particular, this paper provides an overview of the emerging field of resilient AI and presents research issues the authors identify as potential future work.
* 7 pages, 1 figure
$k$-Anonymity in Practice: How Generalisation and Suppression Affect Machine Learning Classifiers
Feb 09, 2021
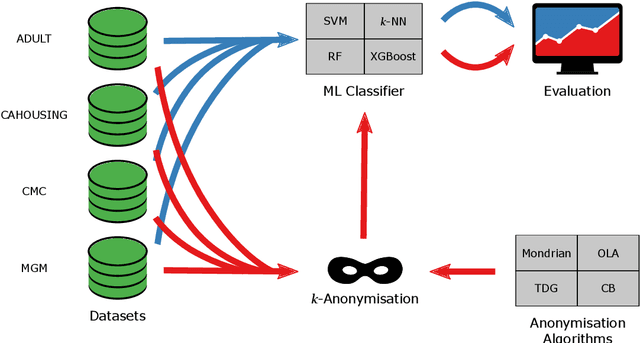
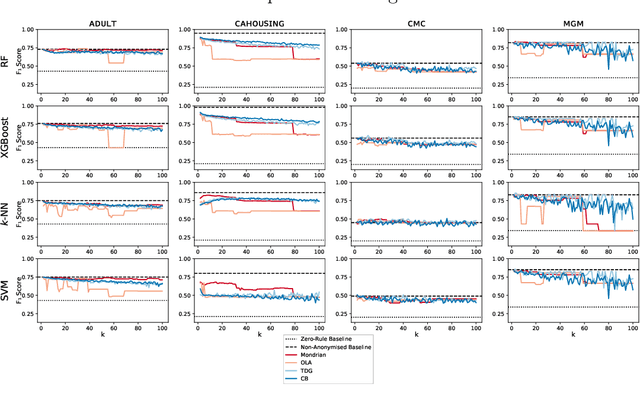
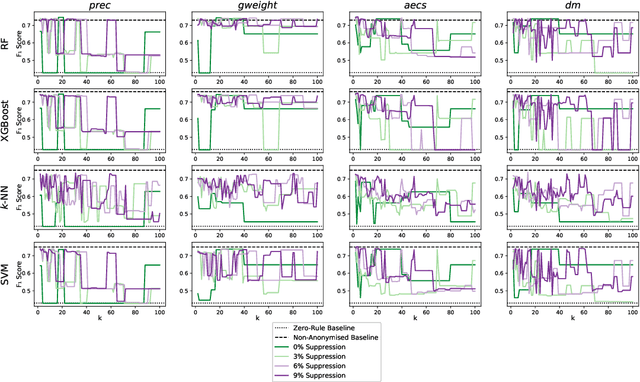
The protection of private information is a crucial issue in data-driven research and business contexts. Typically, techniques like anonymisation or (selective) deletion are introduced in order to allow data sharing, \eg\ in the case of collaborative research endeavours. For use with anonymisation techniques, the $k$-anonymity criterion is one of the most popular, with numerous scientific publications on different algorithms and metrics. Anonymisation techniques often require changing the data and thus necessarily affect the results of machine learning models trained on the underlying data. In this work, we conduct a systematic comparison and detailed investigation into the effects of different $k$-anonymisation algorithms on the results of machine learning models. We investigate a set of popular $k$-anonymisation algorithms with different classifiers and evaluate them on different real-world datasets. Our systematic evaluation shows that with an increasingly strong $k$-anonymity constraint, the classification performance generally degrades, but to varying degrees and strongly depending on the dataset and anonymisation method. Furthermore, Mondrian can be considered as the method with the most appealing properties for subsequent classification.
The Need for Speed of AI Applications: Performance Comparison of Native vs. Browser-based Algorithm Implementations
Feb 11, 2018



AI applications pose increasing demands on performance, so it is not surprising that the era of client-side distributed software is becoming important. On top of many AI applications already using mobile hardware, and even browsers for computationally demanding AI applications, we are already witnessing the emergence of client-side (federated) machine learning algorithms, driven by the interests of large corporations and startups alike. Apart from mathematical and algorithmic concerns, this trend especially demands new levels of computational efficiency from client environments. Consequently, this paper deals with the question of state-of-the-art performance by presenting a comparison study between native code and different browser-based implementations: JavaScript, ASM.js as well as WebAssembly on a representative mix of algorithms. Our results show that current efforts in runtime optimization push the boundaries well towards (and even beyond) native binary performance. We analyze the results obtained and speculate on the reasons behind some surprises, rounding the paper off by outlining future possibilities as well as some of our own research efforts.
Towards the Augmented Pathologist: Challenges of Explainable-AI in Digital Pathology
Dec 18, 2017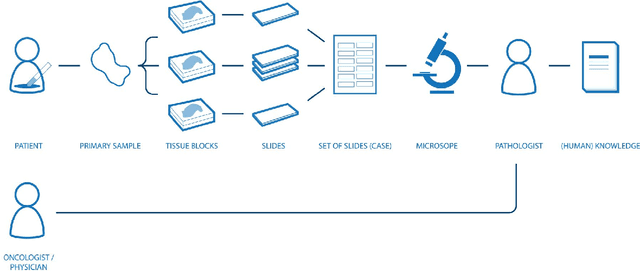
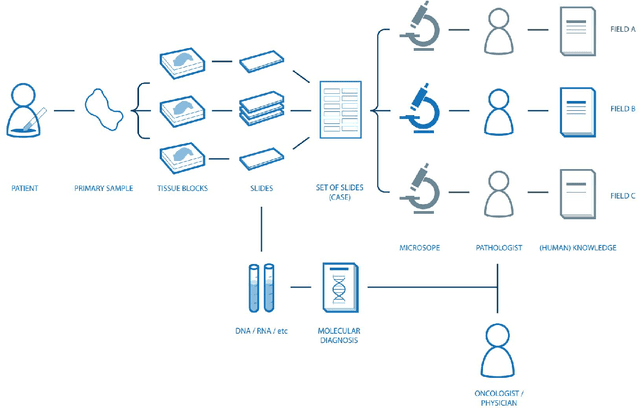
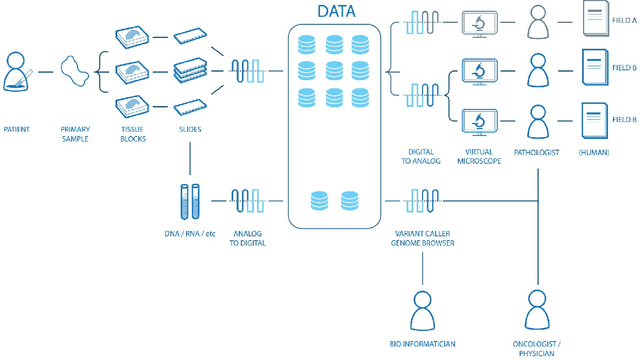
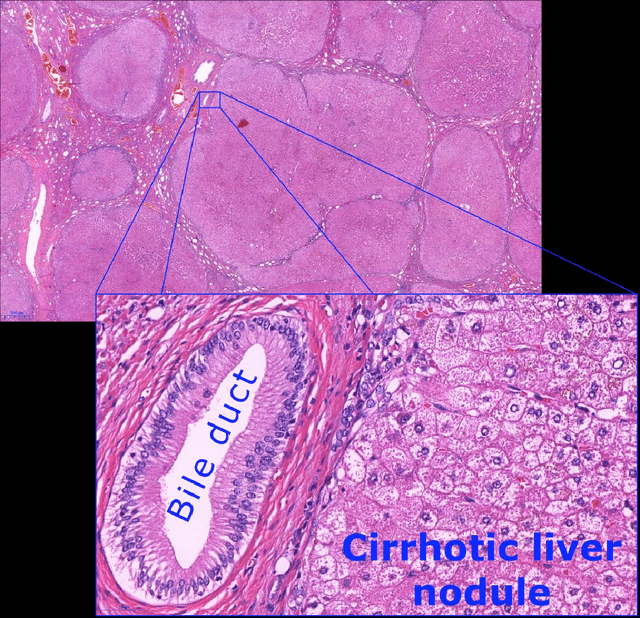
Digital pathology is not only one of the most promising fields of diagnostic medicine, but at the same time a hot topic for fundamental research. Digital pathology is not just the transfer of histopathological slides into digital representations. The combination of different data sources (images, patient records, and *omics data) together with current advances in artificial intelligence/machine learning enable to make novel information accessible and quantifiable to a human expert, which is not yet available and not exploited in current medical settings. The grand goal is to reach a level of usable intelligence to understand the data in the context of an application task, thereby making machine decisions transparent, interpretable and explainable. The foundation of such an "augmented pathologist" needs an integrated approach: While machine learning algorithms require many thousands of training examples, a human expert is often confronted with only a few data points. Interestingly, humans can learn from such few examples and are able to instantly interpret complex patterns. Consequently, the grand goal is to combine the possibilities of artificial intelligence with human intelligence and to find a well-suited balance between them to enable what neither of them could do on their own. This can raise the quality of education, diagnosis, prognosis and prediction of cancer and other diseases. In this paper we describe some (incomplete) research issues which we believe should be addressed in an integrated and concerted effort for paving the way towards the augmented pathologist.