 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelete My Account: Impact of Data Deletion on Machine Learning Classifiers
Nov 17, 2023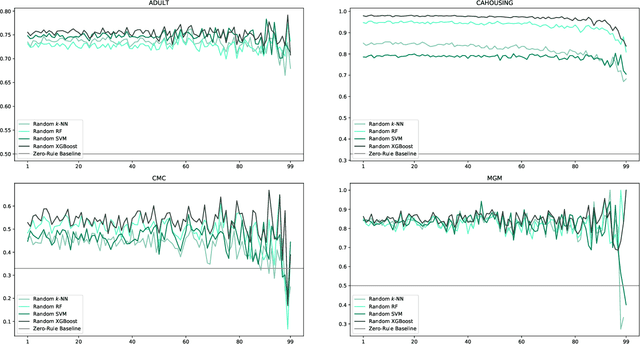
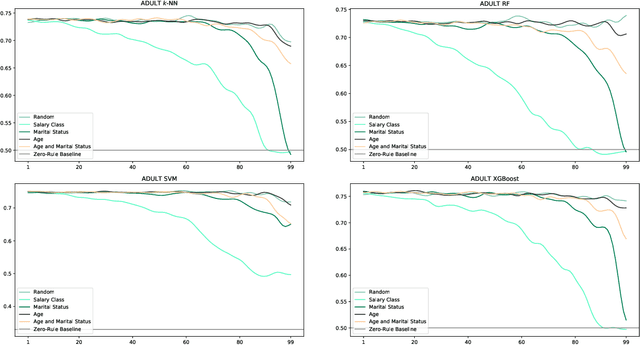
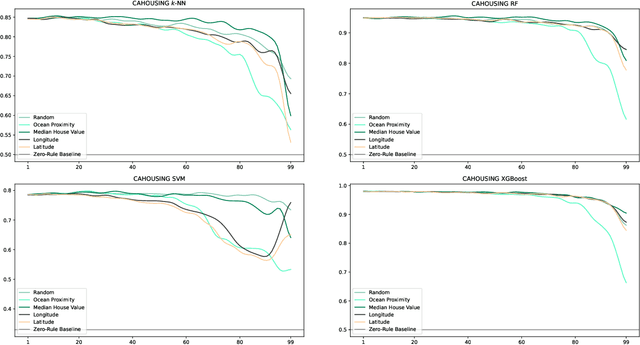
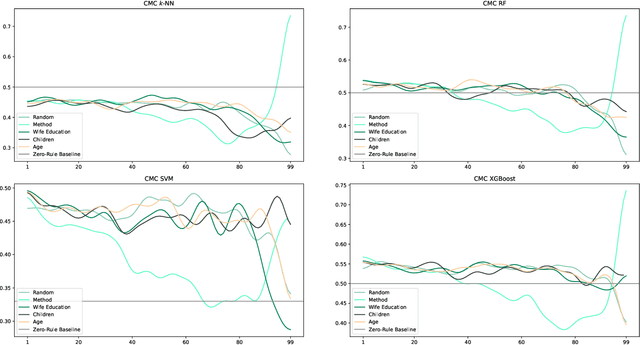
Users are more aware than ever of the importance of their own data, thanks to reports about security breaches and leaks of private, often sensitive data in recent years. Additionally, the GDPR has been in effect in the European Union for over three years and many people have encountered its effects in one way or another. Consequently, more and more users are actively protecting their personal data. One way to do this is to make of the right to erasure guaranteed in the GDPR, which has potential implications for a number of different fields, such as big data and machine learning. Our paper presents an in-depth analysis about the impact of the use of the right to erasure on the performance of machine learning models on classification tasks. We conduct various experiments utilising different datasets as well as different machine learning algorithms to analyse a variety of deletion behaviour scenarios. Due to the lack of credible data on actual user behaviour, we make reasonable assumptions for various deletion modes and biases and provide insight into the effects of different plausible scenarios for right to erasure usage on data quality of machine learning. Our results show that the impact depends strongly on the amount of data deleted, the particular characteristics of the dataset and the bias chosen for deletion and assumptions on user behaviour.
$k$-Anonymity in Practice: How Generalisation and Suppression Affect Machine Learning Classifiers
Feb 09, 2021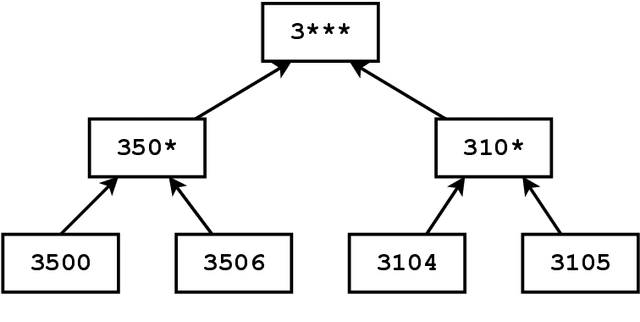
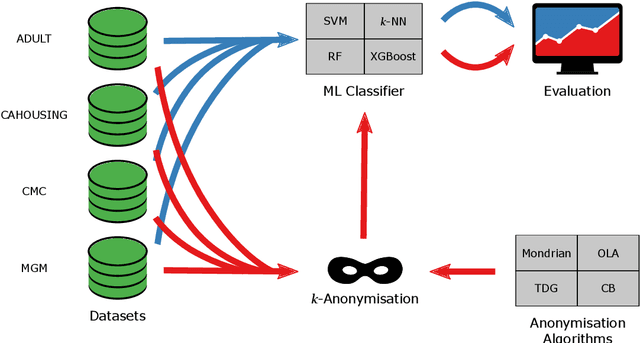
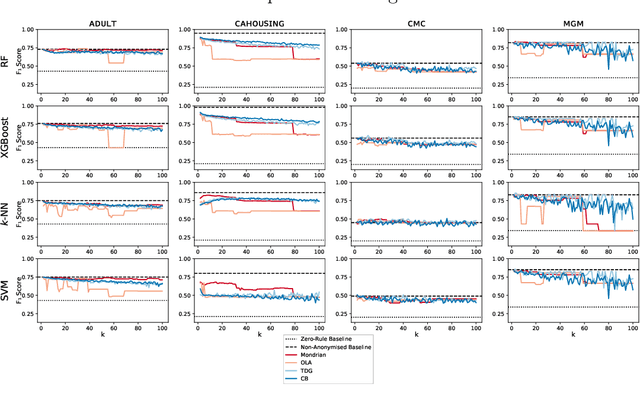
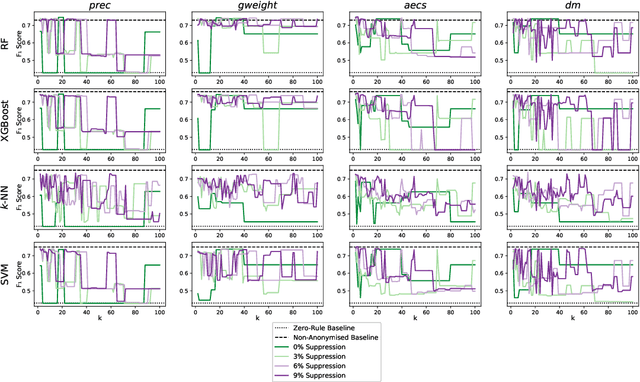
The protection of private information is a crucial issue in data-driven research and business contexts. Typically, techniques like anonymisation or (selective) deletion are introduced in order to allow data sharing, \eg\ in the case of collaborative research endeavours. For use with anonymisation techniques, the $k$-anonymity criterion is one of the most popular, with numerous scientific publications on different algorithms and metrics. Anonymisation techniques often require changing the data and thus necessarily affect the results of machine learning models trained on the underlying data. In this work, we conduct a systematic comparison and detailed investigation into the effects of different $k$-anonymisation algorithms on the results of machine learning models. We investigate a set of popular $k$-anonymisation algorithms with different classifiers and evaluate them on different real-world datasets. Our systematic evaluation shows that with an increasingly strong $k$-anonymity constraint, the classification performance generally degrades, but to varying degrees and strongly depending on the dataset and anonymisation method. Furthermore, Mondrian can be considered as the method with the most appealing properties for subsequent classification.