 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelete My Account: Impact of Data Deletion on Machine Learning Classifiers
Nov 17, 2023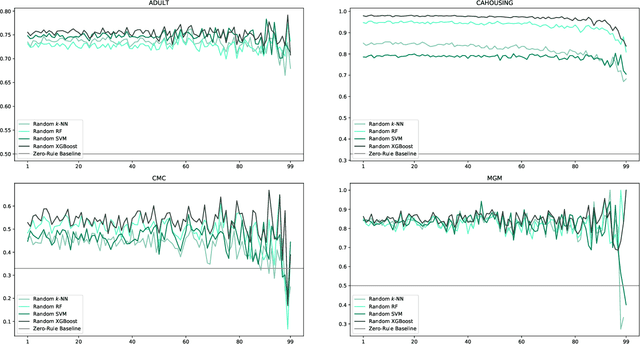
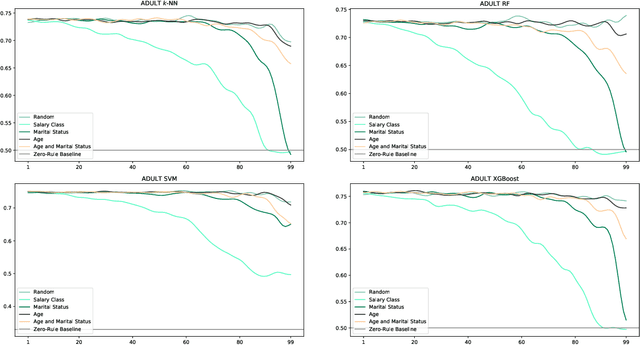
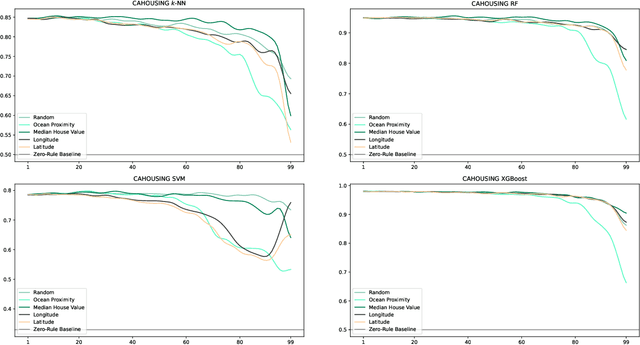
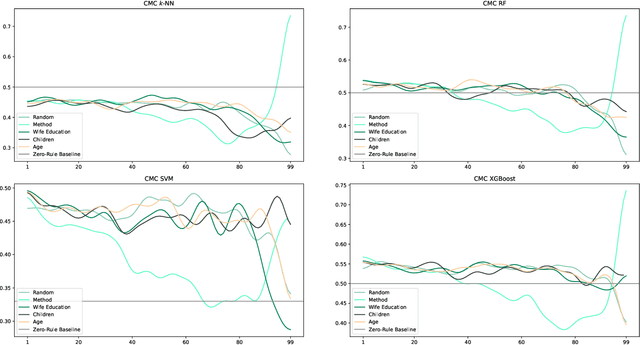
Users are more aware than ever of the importance of their own data, thanks to reports about security breaches and leaks of private, often sensitive data in recent years. Additionally, the GDPR has been in effect in the European Union for over three years and many people have encountered its effects in one way or another. Consequently, more and more users are actively protecting their personal data. One way to do this is to make of the right to erasure guaranteed in the GDPR, which has potential implications for a number of different fields, such as big data and machine learning. Our paper presents an in-depth analysis about the impact of the use of the right to erasure on the performance of machine learning models on classification tasks. We conduct various experiments utilising different datasets as well as different machine learning algorithms to analyse a variety of deletion behaviour scenarios. Due to the lack of credible data on actual user behaviour, we make reasonable assumptions for various deletion modes and biases and provide insight into the effects of different plausible scenarios for right to erasure usage on data quality of machine learning. Our results show that the impact depends strongly on the amount of data deleted, the particular characteristics of the dataset and the bias chosen for deletion and assumptions on user behaviour.
Participatory Research as a Path to Community-Informed, Gender-Fair Machine Translation
Jun 15, 2023Recent years have seen a strongly increased visibility of non-binary people in public discourse. Accordingly, considerations of gender-fair language go beyond a binary conception of male/female. However, language technology, especially machine translation (MT), still suffers from binary gender bias. Proposing a solution for gender-fair MT beyond the binary from a purely technological perspective might fall short to accommodate different target user groups and in the worst case might lead to misgendering. To address this challenge, we propose a method and case study building on participatory action research to include experiential experts, i.e., queer and non-binary people, translators, and MT experts, in the MT design process. The case study focuses on German, where central findings are the importance of context dependency to avoid identity invalidation and a desire for customizable MT solutions.
"Schöne neue Lieferkettenwelt": Workers' Voice und Arbeitsstandards in Zeiten algorithmischer Vorhersage
May 19, 2023The complexity and increasingly tight coupling of supply chains poses a major logistical challenge for leading companies. Another challenge is that leading companies -- under pressure from consumers, a critical public and legislative measures such as supply chain laws -- have to take more responsibility than before for their suppliers' labour standards. In this paper, we discuss a new approach that leading companies are using to try to address these challenges: algorithmic prediction of business risks, but also environmental and social risks. We describe the technical and cultural conditions for algorithmic prediction and explain how -- from the perspective of leading companies -- it helps to address both challenges. We then develop scenarios on how and with what kind of social consequences algorithmic prediction can be used by leading companies. From the scenarios, we derive policy options for different stakeholder groups to help develop algorithmic prediction towards improving labour standards and worker voice. -- Die Komplexit\"at und zunehmend enge Kopplung vieler Lieferketten stellt eine gro{\ss}e logistische Herausforderung f\"ur Leitunternehmen dar. Eine weitere Herausforderung besteht darin, dass Leitunternehmen -- gedr\"angt durch Konsument:innen, eine kritische \"Offentlichkeit und gesetzgeberische Ma{\ss}nahmen wie die Lieferkettengesetze -- st\"arker als bisher Verantwortung f\"ur Arbeitsstandards in ihren Zulieferbetrieben \"ubernehmen m\"ussen. In diesem Beitrag diskutieren wir einen neuen Ansatz, mit dem Leitunternehmen versuchen, diese Herausforderungen zu bearbeiten: die algorithmische Vorhersage von betriebswirtschaftlichen, aber auch \"okologischen und sozialen Risiken. Wir beschreiben die technischen und kulturellen Bedingungen f\"ur algorithmische Vorhersage und erkl\"aren, wie diese -- aus Perspektive von Leitunternehmen -- bei der Bearbeitung beider Herausforderungen hilft. Anschlie{\ss}end entwickeln wir Szenarien, wie und mit welchen sozialen Konsequenzen algorithmische Vorhersage durch Leitunternehmen eingesetzt werden kann. Aus den Szenarien leiten wir Handlungsoptionen f\"ur verschiedene Stakeholder-Gruppen ab, die dabei helfen sollen, algorithmische Vorhersage im Sinne einer Verbesserung von Arbeitsstandards und Workers' Voice weiterzuentwickeln.
* 21 pages, in German
"Es geht um Respekt, nicht um Technologie": Erkenntnisse aus einem Interessensgruppen-übergreifenden Workshop zu genderfairer Sprache und Sprachtechnologie
Sep 06, 2022With the increasing attention non-binary people receive in Western societies, strategies of gender-fair language have started to move away from binary (only female/male) concepts of gender. Nevertheless, hardly any approaches to take these identities into account into machine translation models exist so far. A lack of understanding of the socio-technical implications of such technologies risks further reproducing linguistic mechanisms of oppression and mislabelling. In this paper, we describe the methods and results of a workshop on gender-fair language and language technologies, which was led and organised by ten researchers from TU Wien, St. P\"olten UAS, FH Campus Wien and the University of Vienna and took place in Vienna in autumn 2021. A wide range of interest groups and their representatives were invited to ensure that the topic could be dealt with holistically. Accordingly, we aimed to include translators, machine translation experts and non-binary individuals (as "community experts") on an equal footing. Our analysis shows that gender in machine translation requires a high degree of context sensitivity, that developers of such technologies need to position themselves cautiously in a process still under social negotiation, and that flexible approaches seem most adequate at present. We then illustrate steps that follow from our results for the field of gender-fair language technologies so that technological developments can adequately line up with social advancements. ---- Mit zunehmender gesamtgesellschaftlicher Wahrnehmung nicht-bin\"arer Personen haben sich in den letzten Jahren auch Konzepte von genderfairer Sprache von der bisher verwendeten Binarit\"at (weiblich/m\"annlich) entfernt. Trotzdem gibt es bislang nur wenige Ans\"atze dazu, diese Identit\"aten in maschineller \"Ubersetzung abzubilden. Ein fehlendes Verst\"andnis unterschiedlicher sozio-technischer Implikationen derartiger Technologien birgt in sich die Gefahr, fehlerhafte Ansprachen und Bezeichnungen sowie sprachliche Unterdr\"uckungsmechanismen zu reproduzieren. In diesem Beitrag beschreiben wir die Methoden und Ergebnisse eines Workshops zu genderfairer Sprache in technologischen Zusammenh\"angen, der im Herbst 2021 in Wien stattgefunden hat. Zehn Forscher*innen der TU Wien, FH St. P\"olten, FH Campus Wien und Universit\"at Wien organisierten und leiteten den Workshop. Dabei wurden unterschiedlichste Interessensgruppen und deren Vertreter*innen breit gestreut eingeladen, um sicherzustellen, dass das Thema holistisch behandelt werden kann. Dementsprechend setzten wir uns zum Ziel, Machine-Translation-Entwickler*innen, \"Ubersetzer*innen, und nicht-bin\"are Privatpersonen (als "Lebenswelt-Expert*innen") gleichberechtigt einzubinden. Unsere Analyse zeigt, dass Geschlecht in maschineller \"Ubersetzung eine ma\ss{}geblich kontextsensible Herangehensweise erfordert, die Entwicklung von Sprachtechnologien sich vorsichtig in einem sich noch in Aushandlung befindlichen gesellschaftlichen Prozess positionieren muss, und flexible Ans\"atze derzeit am ad\"aquatesten erscheinen. Wir zeigen auf, welche n\"achsten Schritte im Bereich genderfairer Technologien notwendig sind, damit technische mit sozialen Entwicklungen mithalten k\"onnen.
Wer ist schuld, wenn Algorithmen irren? Entscheidungsautomatisierung, Organisationen und Verantwortung
Jul 21, 2022Algorithmic decision support (ADS) is increasingly used in a whole array of different contexts and structures in various areas of society, influencing many people's lives. Its use raises questions, among others, about accountability, transparency and responsibility. Our article aims to give a brief overview of the central issues connected to ADS, responsibility and decision-making in organisational contexts and identify open questions and research gaps. Furthermore, we describe a set of guidelines and a complementary digital tool to assist practitioners in mapping responsibility when introducing ADS within their organisational context. -- Algorithmenunterst\"utzte Entscheidungsfindung (algorithmic decision support, ADS) kommt in verschiedenen Kontexten und Strukturen vermehrt zum Einsatz und beeinflusst in diversen gesellschaftlichen Bereichen das Leben vieler Menschen. Ihr Einsatz wirft einige Fragen auf, unter anderem zu den Themen Rechenschaft, Transparenz und Verantwortung. Im Folgenden m\"ochten wir einen \"Uberblick \"uber die wichtigsten Fragestellungen rund um ADS, Verantwortung und Entscheidungsfindung in organisationalen Kontexten geben und einige offene Fragen und Forschungsl\"ucken aufzeigen. Weiters beschreiben wir als konkrete Hilfestellung f\"ur die Praxis einen von uns entwickelten Leitfaden samt erg\"anzendem digitalem Tool, welches Anwender:innen insbesondere bei der Verortung und Zuordnung von Verantwortung bei der Nutzung von ADS in organisationalen Kontexten helfen soll.
* 18 pages, 2 figures, in German
Towards Resilient Artificial Intelligence: Survey and Research Issues
Sep 18, 2021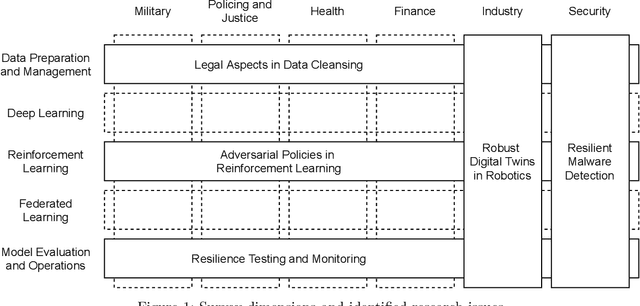
Artificial intelligence (AI) systems are becoming critical components of today's IT landscapes. Their resilience against attacks and other environmental influences needs to be ensured just like for other IT assets. Considering the particular nature of AI, and machine learning (ML) in particular, this paper provides an overview of the emerging field of resilient AI and presents research issues the authors identify as potential future work.
* 7 pages, 1 figure
$k$-Anonymity in Practice: How Generalisation and Suppression Affect Machine Learning Classifiers
Feb 09, 2021
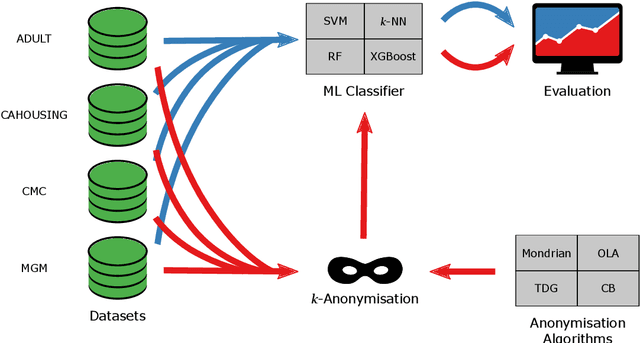
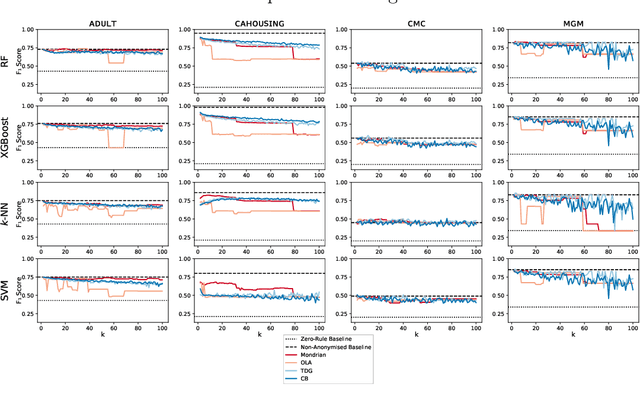
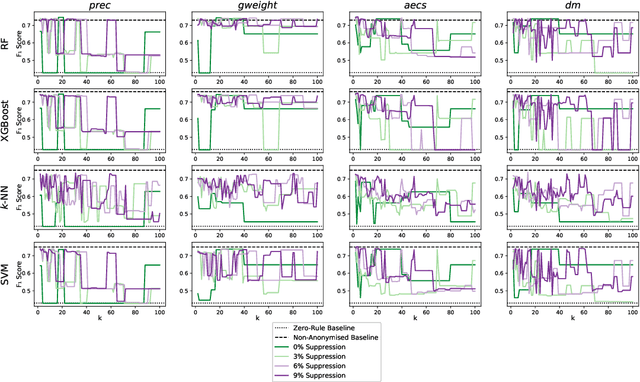
The protection of private information is a crucial issue in data-driven research and business contexts. Typically, techniques like anonymisation or (selective) deletion are introduced in order to allow data sharing, \eg\ in the case of collaborative research endeavours. For use with anonymisation techniques, the $k$-anonymity criterion is one of the most popular, with numerous scientific publications on different algorithms and metrics. Anonymisation techniques often require changing the data and thus necessarily affect the results of machine learning models trained on the underlying data. In this work, we conduct a systematic comparison and detailed investigation into the effects of different $k$-anonymisation algorithms on the results of machine learning models. We investigate a set of popular $k$-anonymisation algorithms with different classifiers and evaluate them on different real-world datasets. Our systematic evaluation shows that with an increasingly strong $k$-anonymity constraint, the classification performance generally degrades, but to varying degrees and strongly depending on the dataset and anonymisation method. Furthermore, Mondrian can be considered as the method with the most appealing properties for subsequent classification.
Anomaly Detection Support Using Process Classification
Jan 13, 2021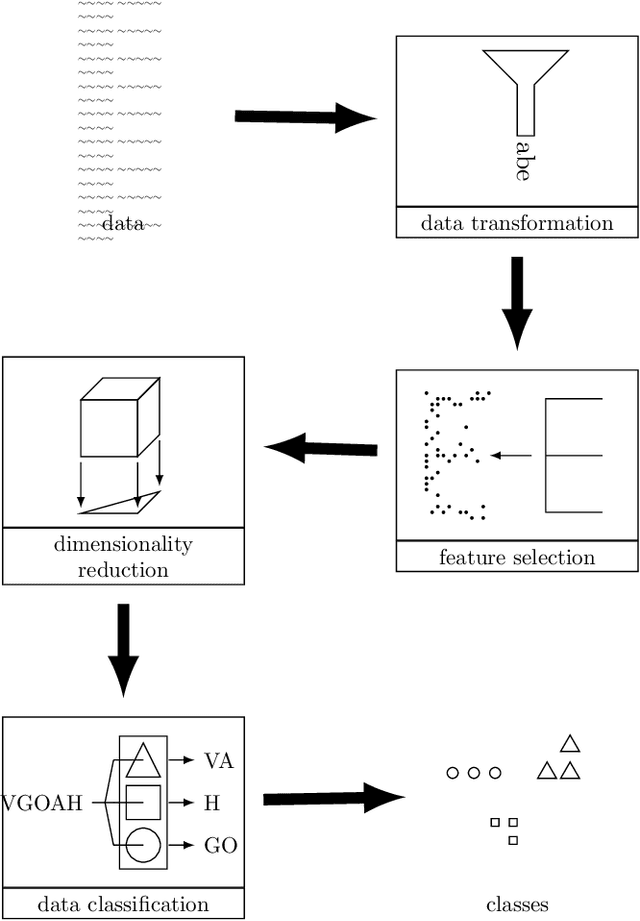
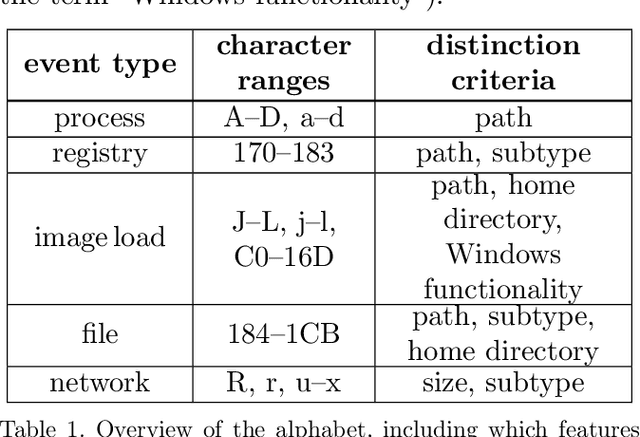

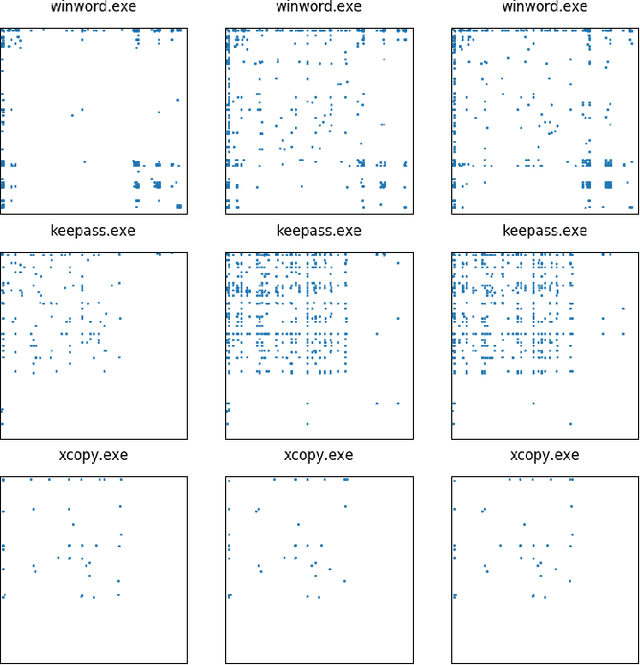
Anomaly detection systems need to consider a lot of information when scanning for anomalies. One example is the context of the process in which an anomaly might occur, because anomalies for one process might not be anomalies for a different one. Therefore data -- such as system events -- need to be assigned to the program they originate from. This paper investigates whether it is possible to infer from a list of system events the program whose behavior caused the occurrence of these system events. To that end, we model transition probabilities between non-equivalent events and apply the $k$-nearest neighbors algorithm. This system is evaluated on non-malicious, real-world data using four different evaluation scores. Our results suggest that the approach proposed in this paper is capable of correctly inferring program names from system events.
* 14 pages, 6 figures