 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticipatory Research as a Path to Community-Informed, Gender-Fair Machine Translation
Jun 15, 2023Recent years have seen a strongly increased visibility of non-binary people in public discourse. Accordingly, considerations of gender-fair language go beyond a binary conception of male/female. However, language technology, especially machine translation (MT), still suffers from binary gender bias. Proposing a solution for gender-fair MT beyond the binary from a purely technological perspective might fall short to accommodate different target user groups and in the worst case might lead to misgendering. To address this challenge, we propose a method and case study building on participatory action research to include experiential experts, i.e., queer and non-binary people, translators, and MT experts, in the MT design process. The case study focuses on German, where central findings are the importance of context dependency to avoid identity invalidation and a desire for customizable MT solutions.
"Es geht um Respekt, nicht um Technologie": Erkenntnisse aus einem Interessensgruppen-übergreifenden Workshop zu genderfairer Sprache und Sprachtechnologie
Sep 06, 2022With the increasing attention non-binary people receive in Western societies, strategies of gender-fair language have started to move away from binary (only female/male) concepts of gender. Nevertheless, hardly any approaches to take these identities into account into machine translation models exist so far. A lack of understanding of the socio-technical implications of such technologies risks further reproducing linguistic mechanisms of oppression and mislabelling. In this paper, we describe the methods and results of a workshop on gender-fair language and language technologies, which was led and organised by ten researchers from TU Wien, St. P\"olten UAS, FH Campus Wien and the University of Vienna and took place in Vienna in autumn 2021. A wide range of interest groups and their representatives were invited to ensure that the topic could be dealt with holistically. Accordingly, we aimed to include translators, machine translation experts and non-binary individuals (as "community experts") on an equal footing. Our analysis shows that gender in machine translation requires a high degree of context sensitivity, that developers of such technologies need to position themselves cautiously in a process still under social negotiation, and that flexible approaches seem most adequate at present. We then illustrate steps that follow from our results for the field of gender-fair language technologies so that technological developments can adequately line up with social advancements. ---- Mit zunehmender gesamtgesellschaftlicher Wahrnehmung nicht-bin\"arer Personen haben sich in den letzten Jahren auch Konzepte von genderfairer Sprache von der bisher verwendeten Binarit\"at (weiblich/m\"annlich) entfernt. Trotzdem gibt es bislang nur wenige Ans\"atze dazu, diese Identit\"aten in maschineller \"Ubersetzung abzubilden. Ein fehlendes Verst\"andnis unterschiedlicher sozio-technischer Implikationen derartiger Technologien birgt in sich die Gefahr, fehlerhafte Ansprachen und Bezeichnungen sowie sprachliche Unterdr\"uckungsmechanismen zu reproduzieren. In diesem Beitrag beschreiben wir die Methoden und Ergebnisse eines Workshops zu genderfairer Sprache in technologischen Zusammenh\"angen, der im Herbst 2021 in Wien stattgefunden hat. Zehn Forscher*innen der TU Wien, FH St. P\"olten, FH Campus Wien und Universit\"at Wien organisierten und leiteten den Workshop. Dabei wurden unterschiedlichste Interessensgruppen und deren Vertreter*innen breit gestreut eingeladen, um sicherzustellen, dass das Thema holistisch behandelt werden kann. Dementsprechend setzten wir uns zum Ziel, Machine-Translation-Entwickler*innen, \"Ubersetzer*innen, und nicht-bin\"are Privatpersonen (als "Lebenswelt-Expert*innen") gleichberechtigt einzubinden. Unsere Analyse zeigt, dass Geschlecht in maschineller \"Ubersetzung eine ma\ss{}geblich kontextsensible Herangehensweise erfordert, die Entwicklung von Sprachtechnologien sich vorsichtig in einem sich noch in Aushandlung befindlichen gesellschaftlichen Prozess positionieren muss, und flexible Ans\"atze derzeit am ad\"aquatesten erscheinen. Wir zeigen auf, welche n\"achsten Schritte im Bereich genderfairer Technologien notwendig sind, damit technische mit sozialen Entwicklungen mithalten k\"onnen.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020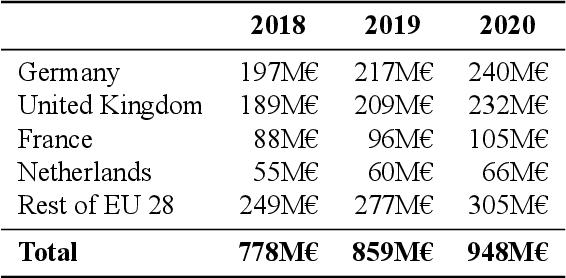
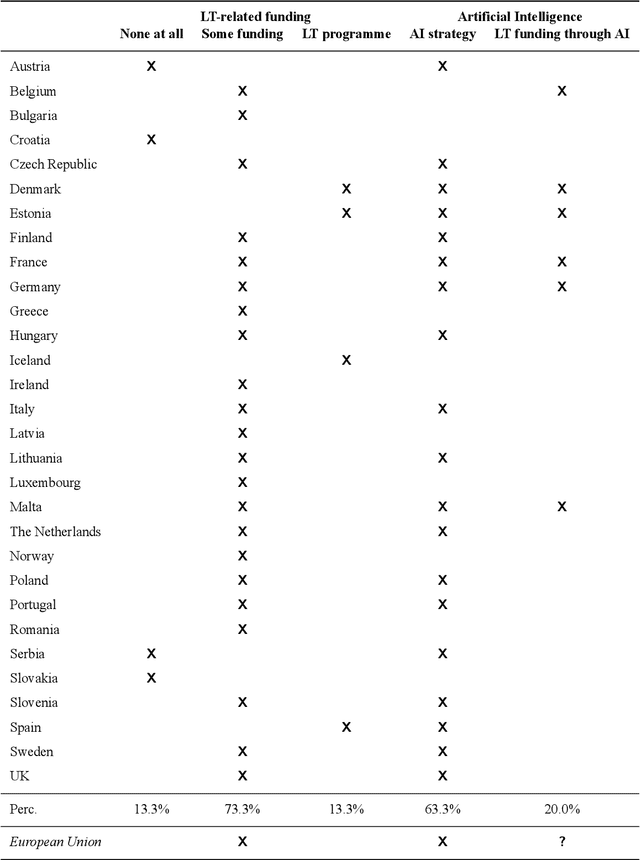
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
Neural Machine Translating from Natural Language to SPARQL
Jun 21, 2019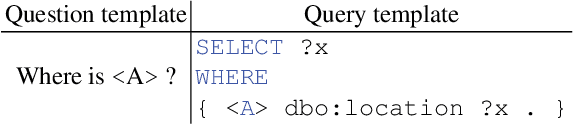
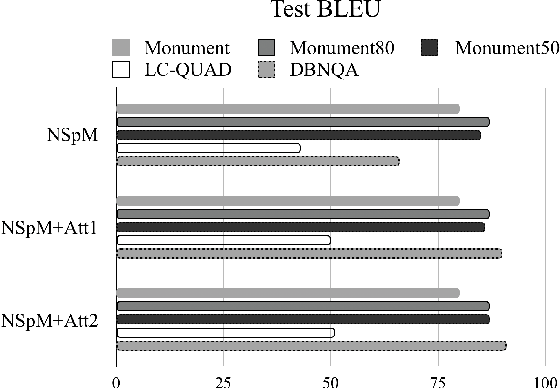

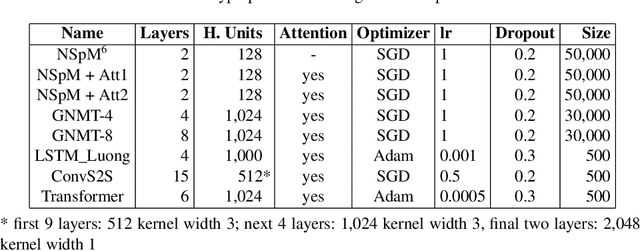
SPARQL is a highly powerful query language for an ever-growing number of Linked Data resources and Knowledge Graphs. Using it requires a certain familiarity with the entities in the domain to be queried as well as expertise in the language's syntax and semantics, none of which average human web users can be assumed to possess. To overcome this limitation, automatically translating natural language questions to SPARQL queries has been a vibrant field of research. However, to this date, the vast success of deep learning methods has not yet been fully propagated to this research problem. This paper contributes to filling this gap by evaluating the utilization of eight different Neural Machine Translation (NMT) models for the task of translating from natural language to the structured query language SPARQL. While highlighting the importance of high-quantity and high-quality datasets, the results show a dominance of a CNN-based architecture with a BLEU score of up to 98 and accuracy of up to 94%.