 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Optimisation of Machine Learning Models for Smart Irrigation in Urban Parks
Oct 03, 2024Urban environments face significant challenges due to climate change, including extreme heat, drought, and water scarcity, which impact public health, community well-being, and local economies. Effective management of these issues is crucial, particularly in areas like Sydney Olympic Park, which relies on one of Australia's largest irrigation systems. The Smart Irrigation Management for Parks and Cool Towns (SIMPaCT) project, initiated in 2021, leverages advanced technologies and machine learning models to optimize irrigation and induce physical cooling. This paper introduces two novel methods to enhance the efficiency of the SIMPaCT system's extensive sensor network and applied machine learning models. The first method employs clustering of sensor time series data using K-shape and K-means algorithms to estimate readings from missing sensors, ensuring continuous and reliable data. This approach can detect anomalies, correct data sources, and identify and remove redundant sensors to reduce maintenance costs. The second method involves sequential data collection from different sensor locations using robotic systems, significantly reducing the need for high numbers of stationary sensors. Together, these methods aim to maintain accurate soil moisture predictions while optimizing sensor deployment and reducing maintenance costs, thereby enhancing the efficiency and effectiveness of the smart irrigation system. Our evaluations demonstrate significant improvements in the efficiency and cost-effectiveness of soil moisture monitoring networks. The cluster-based replacement of missing sensors provides up to 5.4% decrease in average error. The sequential sensor data collection as a robotic emulation shows 17.2% and 2.1% decrease in average error for circular and linear paths respectively.
A Unified Manifold Similarity Measure Enhancing Few-Shot, Transfer, and Reinforcement Learning in Manifold-Distributed Datasets
Aug 12, 2024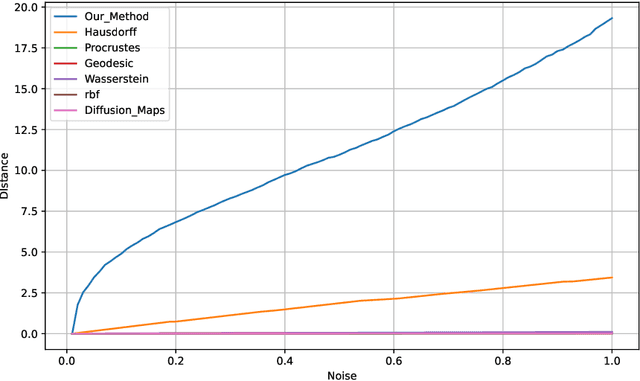


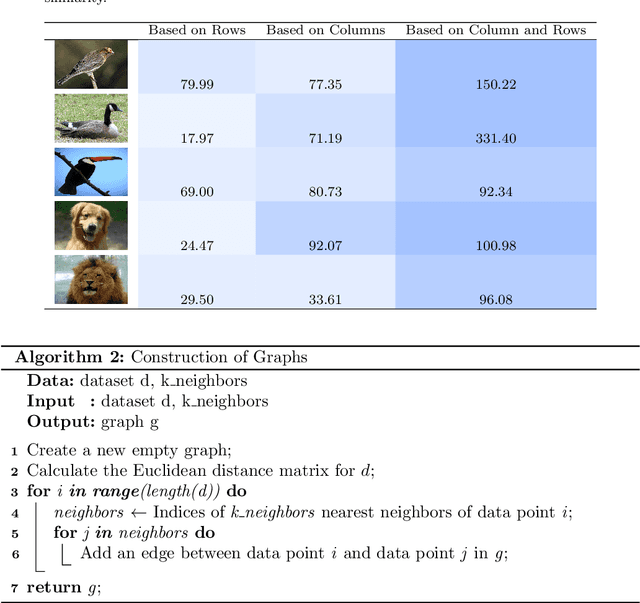
Training a classifier with high mean accuracy from a manifold-distributed dataset can be challenging. This problem is compounded further when there are only few labels available for training. For transfer learning to work, both the source and target datasets must have a similar manifold structure. As part of this study, we present a novel method for determining the similarity between two manifold structures. This method can be used to determine whether the target and source datasets have a similar manifold structure suitable for transfer learning. We then present a few-shot learning method to classify manifold-distributed datasets with limited labels using transfer learning. Based on the base and target datasets, a similarity comparison is made to determine if the two datasets are suitable for transfer learning. A manifold structure and label distribution are learned from the base and target datasets. When the structures are similar, the manifold structure and its relevant label information from the richly labeled source dataset is transferred to target dataset. We use the transferred information, together with the labels and unlabeled data from the target dataset, to develop a few-shot classifier that produces high mean classification accuracy on manifold-distributed datasets. In the final part of this article, we discuss the application of our manifold structure similarity measure to reinforcement learning and image recognition.
TurtleRabbit 2024 SSL Team Description Paper
Feb 13, 2024

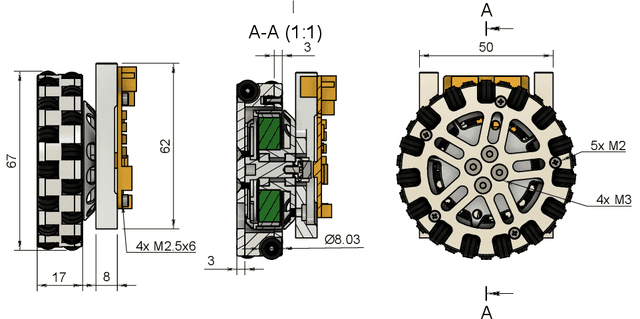

TurtleRabbit is a new RoboCup SSL team from Western Sydney University. This team description paper presents our approach in navigating some of the challenges in developing a new SSL team from scratch. SSL is dominated by teams with extensive experience and customised equipment that has been developed over many years. Here, we outline our approach in overcoming some of the complexities associated with replicating advanced open-sourced designs and managing the high costs of custom components. Opting for simplicity and cost-effectiveness, our strategy primarily employs off-the-shelf electronics components and ``hobby'' brushless direct current (BLDC) motors, complemented by 3D printing and CNC milling. This approach helped us to streamline the development process and, with our open-sourced hardware design, hopefully will also lower the bar for other teams to enter RoboCup SSL in the future. The paper details the specific hardware choices, their approximate costs, the integration of electronics and mechanics, and the initial steps taken in software development, for our entry into SSL that aims to be simple yet competitive.
Analyzing Echo-state Networks Using Fractal Dimension
May 26, 2022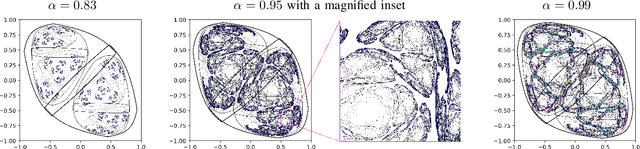
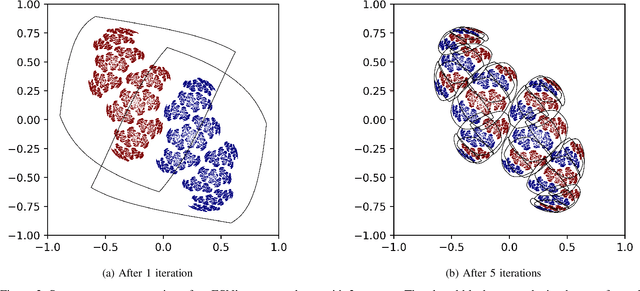
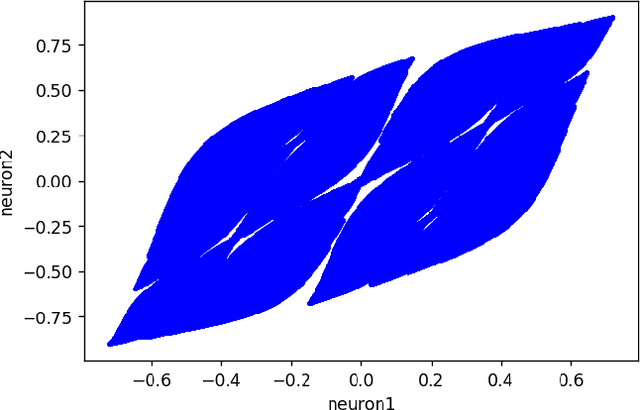
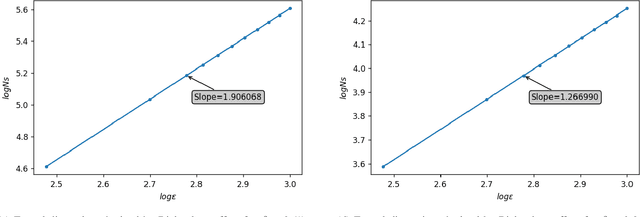
This work joins aspects of reservoir optimization, information-theoretic optimal encoding, and at its center fractal analysis. We build on the observation that, due to the recursive nature of recurrent neural networks, input sequences appear as fractal patterns in their hidden state representation. These patterns have a fractal dimension that is lower than the number of units in the reservoir. We show potential usage of this fractal dimension with regard to optimization of recurrent neural network initialization. We connect the idea of `ideal' reservoirs to lossless optimal encoding using arithmetic encoders. Our investigation suggests that the fractal dimension of the mapping from input to hidden state shall be close to the number of units in the network. This connection between fractal dimension and network connectivity is an interesting new direction for recurrent neural network initialization and reservoir computing.
A Systematic Literature Review of Automated ICD Coding and Classification Systems using Discharge Summaries
Jul 12, 2021
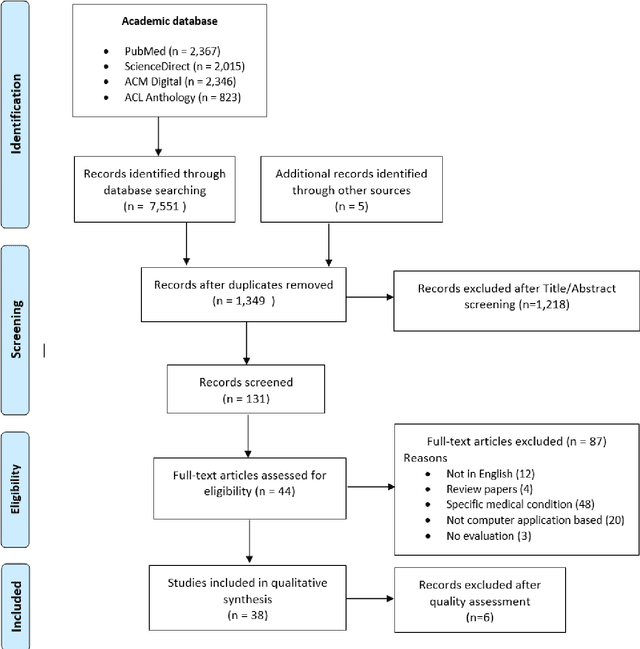


Codification of free-text clinical narratives have long been recognised to be beneficial for secondary uses such as funding, insurance claim processing and research. The current scenario of assigning codes is a manual process which is very expensive, time-consuming and error prone. In recent years, many researchers have studied the use of Natural Language Processing (NLP), related Machine Learning (ML) and Deep Learning (DL) methods and techniques to resolve the problem of manual coding of clinical narratives and to assist human coders to assign clinical codes more accurately and efficiently. This systematic literature review provides a comprehensive overview of automated clinical coding systems that utilises appropriate NLP, ML and DL methods and techniques to assign ICD codes to discharge summaries. We have followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses(PRISMA) guidelines and conducted a comprehensive search of publications from January, 2010 to December 2020 in four academic databases- PubMed, ScienceDirect, Association for Computing Machinery(ACM) Digital Library, and the Association for Computational Linguistics(ACL) Anthology. We reviewed 7,556 publications; 38 met the inclusion criteria. This review identified: datasets having discharge summaries; NLP techniques along with some other data extraction processes, different feature extraction and embedding techniques. To measure the performance of classification methods, different evaluation metrics are used. Lastly, future research directions are provided to scholars who are interested in automated ICD code assignment. Efforts are still required to improve ICD code prediction accuracy, availability of large-scale de-identified clinical corpora with the latest version of the classification system. This can be a platform to guide and share knowledge with the less experienced coders and researchers.
A New Pathway to Approximate Energy Expenditure and Recovery of an Athlete
Apr 16, 2021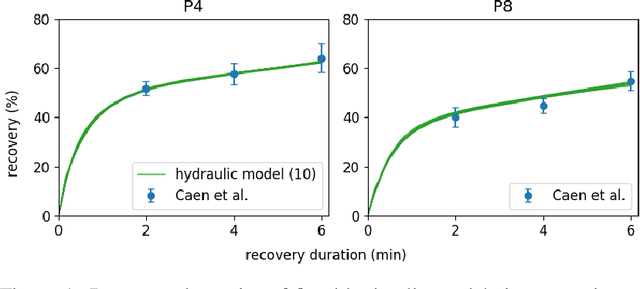

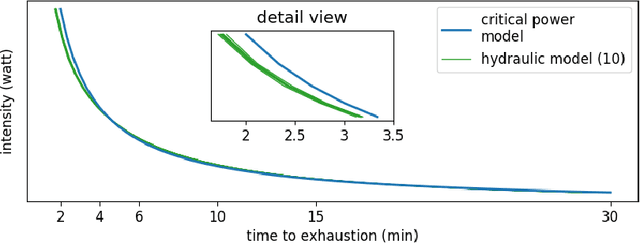

This work proposes to use evolutionary computation as a pathway to allow a new perspective on the modeling of energy expenditure and recovery of an individual athlete during exercise. We revisit a theoretical concept called the "three component hydraulic model" which is designed to simulate metabolic systems during exercise and which is able to address recently highlighted shortcomings of currently applied performance models. This hydraulic model has not been entirely validated on individual athletes because it depends on physiological measures that cannot be acquired in the required precision or quantity. This paper introduces a generalized interpretation and formalization of the three component hydraulic model that removes its ties to concrete metabolic measures and allows to use evolutionary computation to fit its parameters to an athlete.
Predictive Neural Networks
May 02, 2018


Recurrent neural networks are a powerful means to cope with time series. We show that already linearly activated recurrent neural networks can approximate any time-dependent function f(t) given by a number of function values. The approximation can effectively be learned by simply solving a linear equation system; no backpropagation or similar methods are needed. Furthermore, the network size can be reduced by taking only the most relevant components of the network. Thus, in contrast to others, our approach not only learns network weights but also the network architecture. The networks have interesting properties: In the stationary case they end up in ellipse trajectories in the long run, and they allow the prediction of further values and compact representations of functions. We demonstrate this by several experiments, among them multiple superimposed oscillators (MSO) and robotic soccer. Predictive neural networks outperform the previous state-of-the-art for the MSO task with a minimal number of units.
Information Maximizing Exploration with a Latent Dynamics Model
Apr 04, 2018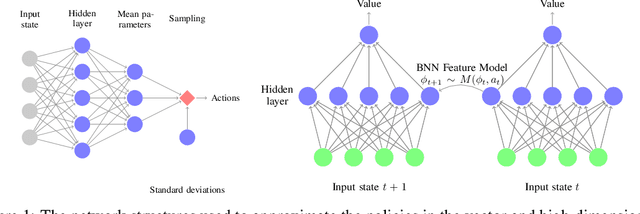

All reinforcement learning algorithms must handle the trade-off between exploration and exploitation. Many state-of-the-art deep reinforcement learning methods use noise in the action selection, such as Gaussian noise in policy gradient methods or $\epsilon$-greedy in Q-learning. While these methods are appealing due to their simplicity, they do not explore the state space in a methodical manner. We present an approach that uses a model to derive reward bonuses as a means of intrinsic motivation to improve model-free reinforcement learning. A key insight of our approach is that this dynamics model can be learned in the latent feature space of a value function, representing the dynamics of the agent and the environment. This method is both theoretically grounded and computationally advantageous, permitting the efficient use of Bayesian information-theoretic methods in high-dimensional state spaces. We evaluate our method on several continuous control tasks, focusing on improving exploration.
RoboCupSimData: A RoboCup soccer research dataset
Nov 06, 2017

RoboCup is an international scientific robot competition in which teams of multiple robots compete against each other. Its different leagues provide many sources of robotics data, that can be used for further analysis and application of machine learning. This paper describes a large dataset from games of some of the top teams (from 2016 and 2017) in RoboCup Soccer Simulation League (2D), where teams of 11 robots (agents) compete against each other. Overall, we used 10 different teams to play each other, resulting in 45 unique pairings. For each pairing, we ran 25 matches (of 10mins), leading to 1125 matches or more than 180 hours of game play. The generated CSV files are 17GB of data (zipped), or 229GB (unzipped). The dataset is unique in the sense that it contains both the ground truth data (global, complete, noise-free information of all objects on the field), as well as the noisy, local and incomplete percepts of each robot. These data are made available as CSV files, as well as in the original soccer simulator formats.
Analysing Soccer Games with Clustering and Conceptors
Aug 19, 2017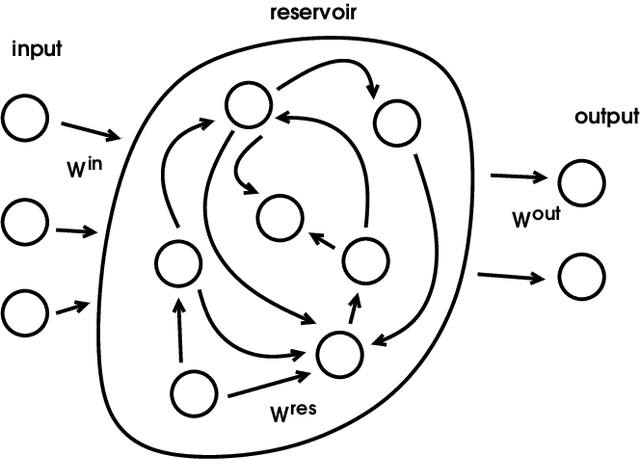



We present a new approach for identifying situations and behaviours, which we call "moves", from soccer games in the 2D simulation league. Being able to identify key situations and behaviours are useful capabilities for analysing soccer matches, anticipating opponent behaviours to aid selection of appropriate tactics, and also as a prerequisite for automatic learning of behaviours and policies. To support a wide set of strategies, our goal is to identify situations from data, in an unsupervised way without making use of pre-defined soccer specific concepts such as "pass" or "dribble". The recurrent neural networks we use in our approach act as a high-dimensional projection of the recent history of a situation on the field. Similar situations, i.e., with similar histories, are found by clustering of network states. The same networks are also used to learn so-called conceptors, that are lower-dimensional manifolds that describe trajectories through a high-dimensional state space that enable situation-specific predictions from the same neural network. With the proposed approach, we can segment games into sequences of situations that are learnt in an unsupervised way, and learn conceptors that are useful for the prediction of the near future of the respective situation.
* To appear in RoboCup 2017: Robot World Cup XXI; Springer, 2018