 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompensating trajectory bias for unsupervised patient stratification using adversarial recurrent neural networks
Dec 14, 2021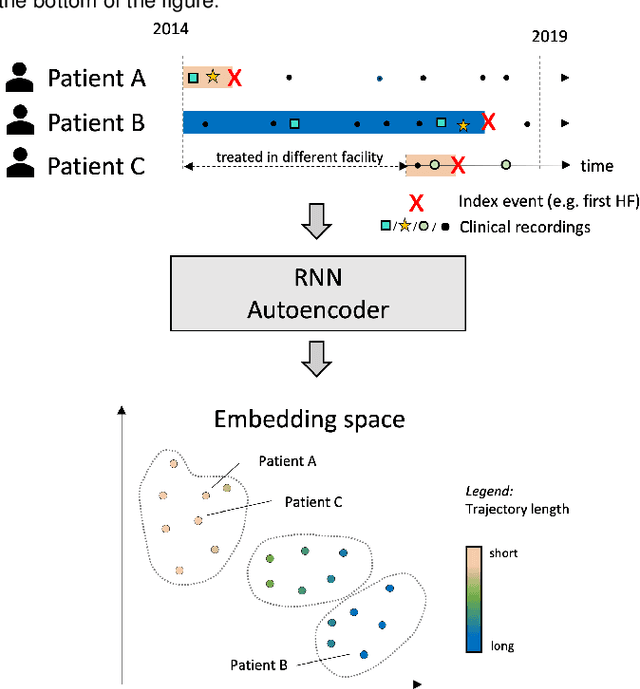
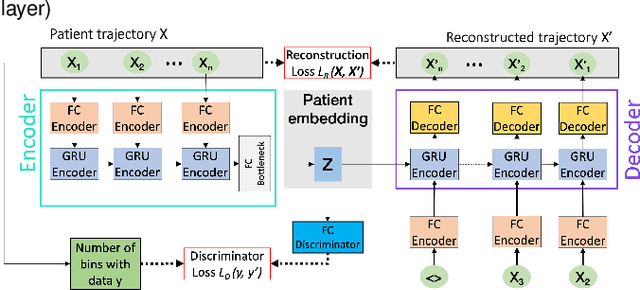
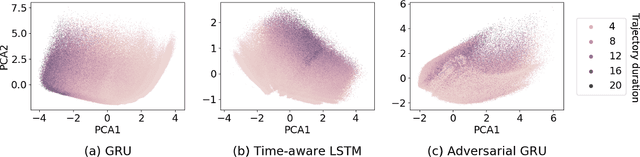
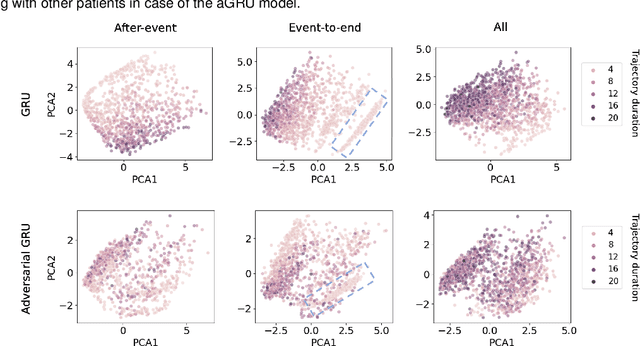
Electronic healthcare records are an important source of information which can be used in patient stratification to discover novel disease phenotypes. However, they can be challenging to work with as data is often sparse and irregularly sampled. One approach to solve these limitations is learning dense embeddings that represent individual patient trajectories using a recurrent neural network autoencoder (RNN-AE). This process can be susceptible to unwanted data biases. We show that patient embeddings and clusters using previously proposed RNN-AE models might be impacted by a trajectory bias, meaning that results are dominated by the amount of data contained in each patients trajectory, instead of clinically relevant details. We investigate this bias on 2 datasets (from different hospitals) and 2 disease areas as well as using different parts of the patient trajectory. Our results using 2 previously published baseline methods indicate a particularly strong bias in case of an event-to-end trajectory. We present a method that can overcome this issue using an adversarial training scheme on top of a RNN-AE. Our results show that our approach can reduce the trajectory bias in all cases.
Longitudinal patient stratification of electronic health records with flexible adjustment for clinical outcomes
Nov 11, 2021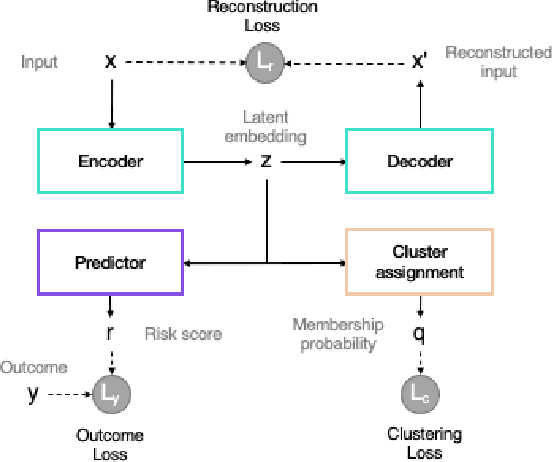
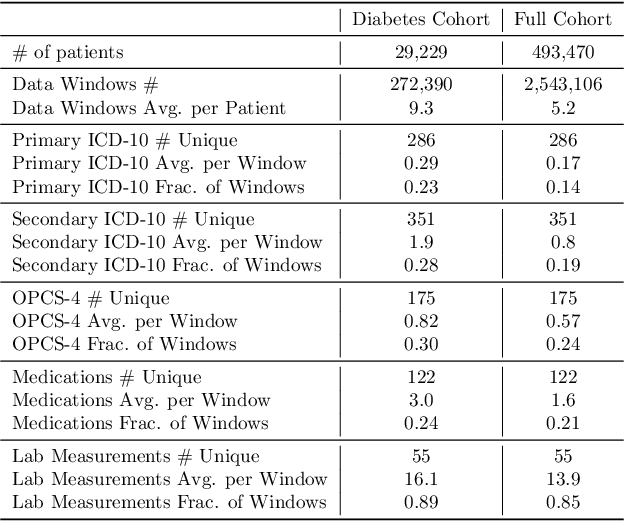
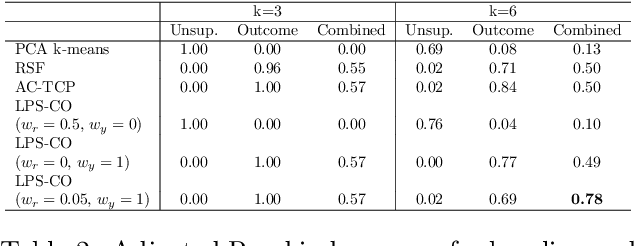
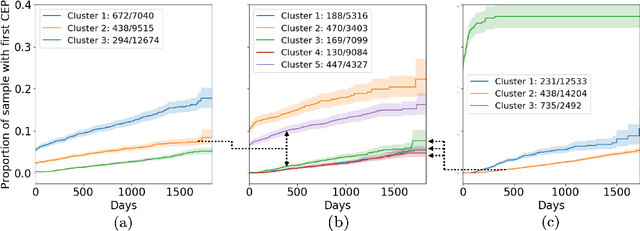
The increase in availability of longitudinal electronic health record (EHR) data is leading to improved understanding of diseases and discovery of novel phenotypes. The majority of clustering algorithms focus only on patient trajectories, yet patients with similar trajectories may have different outcomes. Finding subgroups of patients with different trajectories and outcomes can guide future drug development and improve recruitment to clinical trials. We develop a recurrent neural network autoencoder to cluster EHR data using reconstruction, outcome, and clustering losses which can be weighted to find different types of patient clusters. We show our model is able to discover known clusters from both data biases and outcome differences, outperforming baseline models. We demonstrate the model performance on $29,229$ diabetes patients, showing it finds clusters of patients with both different trajectories and different outcomes which can be utilized to aid clinical decision making.
Deep Semi-Supervised Embedded Clustering (DSEC) for Stratification of Heart Failure Patients
Jan 17, 2021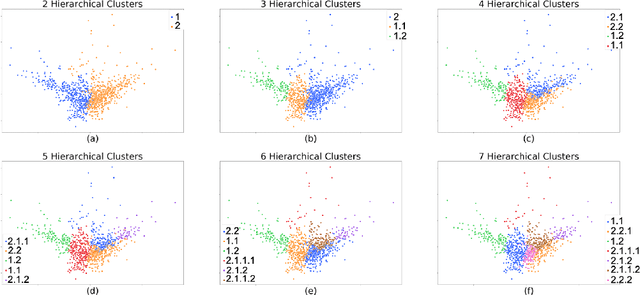

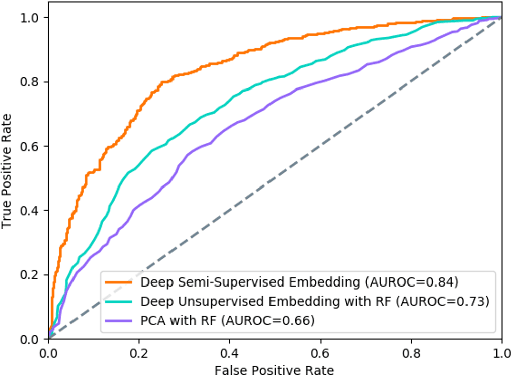
Determining phenotypes of diseases can have considerable benefits for in-hospital patient care and to drug development. The structure of high dimensional data sets such as electronic health records are often represented through an embedding of the data, with clustering methods used to group data of similar structure. If subgroups are known to exist within data, supervised methods may be used to influence the clusters discovered. We propose to extend deep embedded clustering to a semi-supervised deep embedded clustering algorithm to stratify subgroups through known labels in the data. In this work we apply deep semi-supervised embedded clustering to determine data-driven patient subgroups of heart failure from the electronic health records of 4,487 heart failure and control patients. We find clinically relevant clusters from an embedded space derived from heterogeneous data. The proposed algorithm can potentially find new undiagnosed subgroups of patients that have different outcomes, and, therefore, lead to improved treatments.
Prediction of the onset of cardiovascular diseases from electronic health records using multi-task gated recurrent units
Jul 16, 2020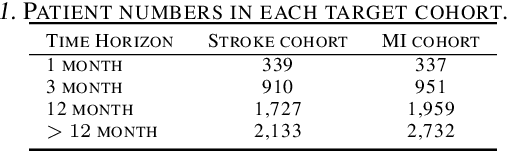
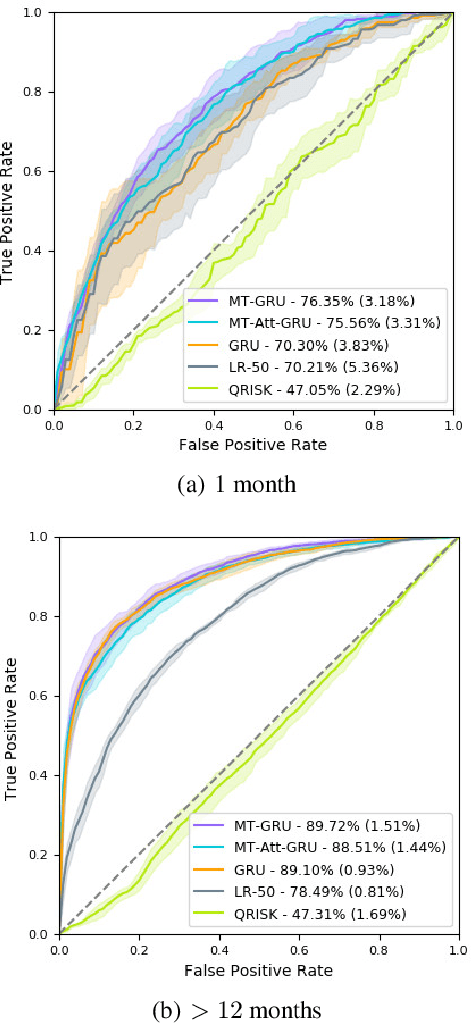
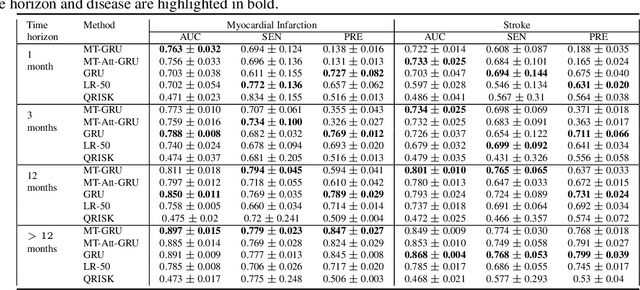
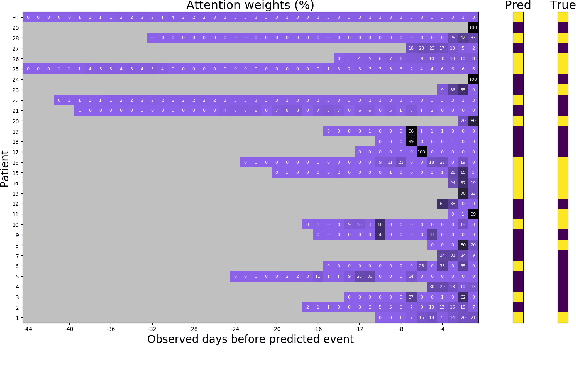
In this work, we propose a multi-task recurrent neural network with attention mechanism for predicting cardiovascular events from electronic health records (EHRs) at different time horizons. The proposed approach is compared to a standard clinical risk predictor (QRISK) and machine learning alternatives using 5-year data from a NHS Foundation Trust. The proposed model outperforms standard clinical risk scores in predicting stroke (AUC=0.85) and myocardial infarction (AUC=0.89), considering the largest time horizon. Benefit of using an \gls{mt} setting becomes visible for very short time horizons, which results in an AUC increase between 2-6%. Further, we explored the importance of individual features and attention weights in predicting cardiovascular events. Our results indicate that the recurrent neural network approach benefits from the hospital longitudinal information and demonstrates how machine learning techniques can be applied to secondary care.