 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Semi-Supervised Embedded Clustering (DSEC) for Stratification of Heart Failure Patients
Paper and Code
Jan 17, 2021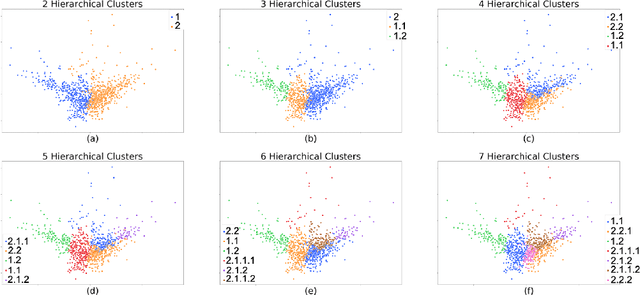

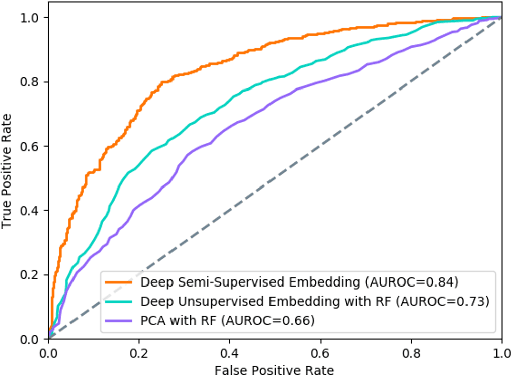
Determining phenotypes of diseases can have considerable benefits for in-hospital patient care and to drug development. The structure of high dimensional data sets such as electronic health records are often represented through an embedding of the data, with clustering methods used to group data of similar structure. If subgroups are known to exist within data, supervised methods may be used to influence the clusters discovered. We propose to extend deep embedded clustering to a semi-supervised deep embedded clustering algorithm to stratify subgroups through known labels in the data. In this work we apply deep semi-supervised embedded clustering to determine data-driven patient subgroups of heart failure from the electronic health records of 4,487 heart failure and control patients. We find clinically relevant clusters from an embedded space derived from heterogeneous data. The proposed algorithm can potentially find new undiagnosed subgroups of patients that have different outcomes, and, therefore, lead to improved treatments.