 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Synergies between Self-supervised Learning and Dynamic Computation
Jan 22, 2023



Self-supervised learning (SSL) approaches have made major strides forward by emulating the performance of their supervised counterparts on several computer vision benchmarks. This, however, comes at a cost of substantially larger model sizes, and computationally expensive training strategies, which eventually lead to larger inference times making it impractical for resource constrained industrial settings. Techniques like knowledge distillation (KD), dynamic computation (DC), and pruning are often used to obtain a lightweight sub-network, which usually involves multiple epochs of fine-tuning of a large pre-trained model, making it more computationally challenging. In this work we propose a novel perspective on the interplay between SSL and DC paradigms that can be leveraged to simultaneously learn a dense and gated (sparse/lightweight) sub-network from scratch offering a good accuracy-efficiency trade-off, and therefore yielding a generic and multi-purpose architecture for application specific industrial settings. Our study overall conveys a constructive message: exhaustive experiments on several image classification benchmarks: CIFAR-10, STL-10, CIFAR-100, and ImageNet-100, demonstrates that the proposed training strategy provides a dense and corresponding sparse sub-network that achieves comparable (on-par) performance compared with the vanilla self-supervised setting, but at a significant reduction in computation in terms of FLOPs under a range of target budgets.
Discerning Generic Event Boundaries in Long-Form Wild Videos
Jun 18, 2021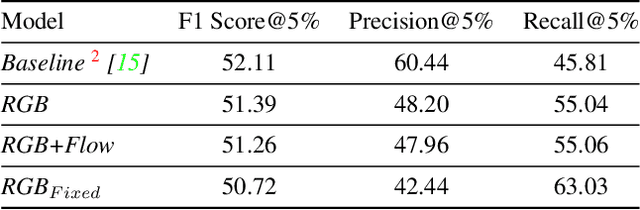
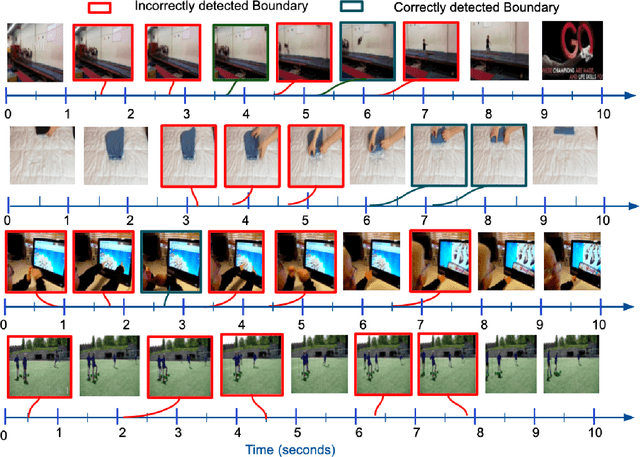
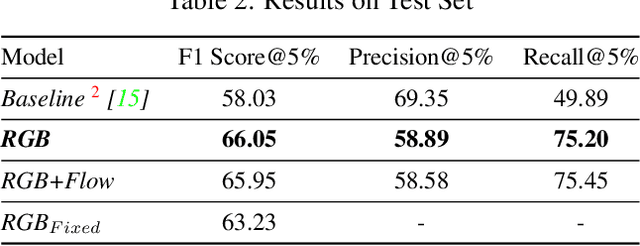
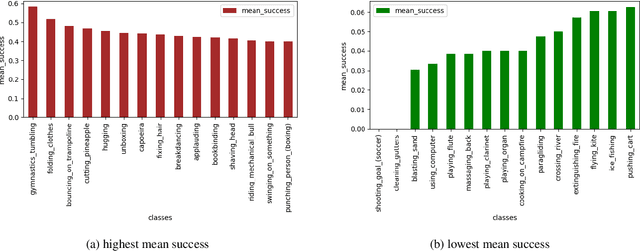
Detecting generic, taxonomy-free event boundaries invideos represents a major stride forward towards holisticvideo understanding. In this paper we present a technique forgeneric event boundary detection based on a two stream in-flated 3D convolutions architecture, which can learn spatio-temporal features from videos. Our work is inspired from theGeneric Event Boundary Detection Challenge (part of CVPR2021 Long Form Video Understanding- LOVEU Workshop).Throughout the paper we provide an in-depth analysis ofthe experiments performed along with an interpretation ofthe results obtained.
Investigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020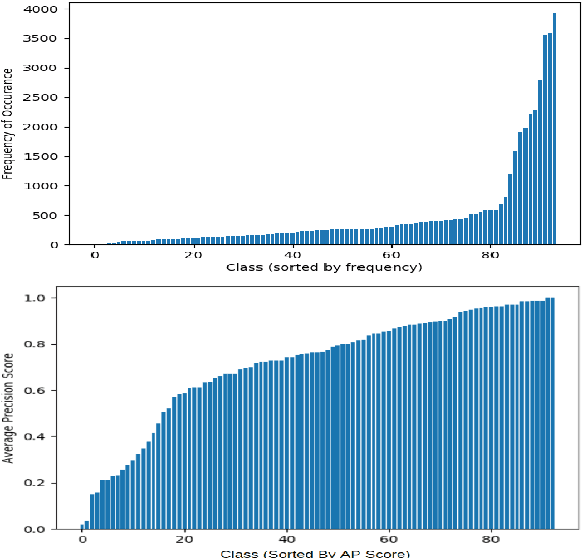

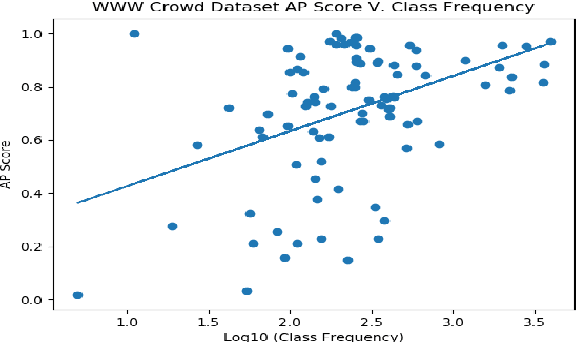

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.
Predicting knee osteoarthritis severity: comparative modeling based on patient's data and plain X-ray images
Aug 23, 2019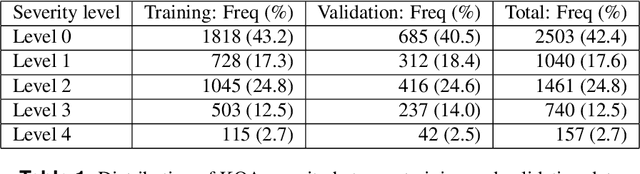
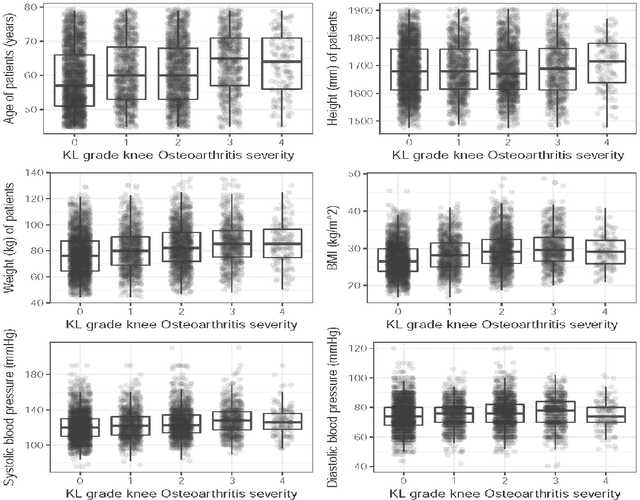
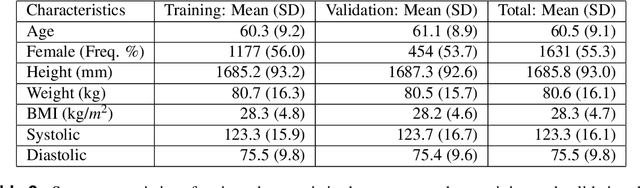
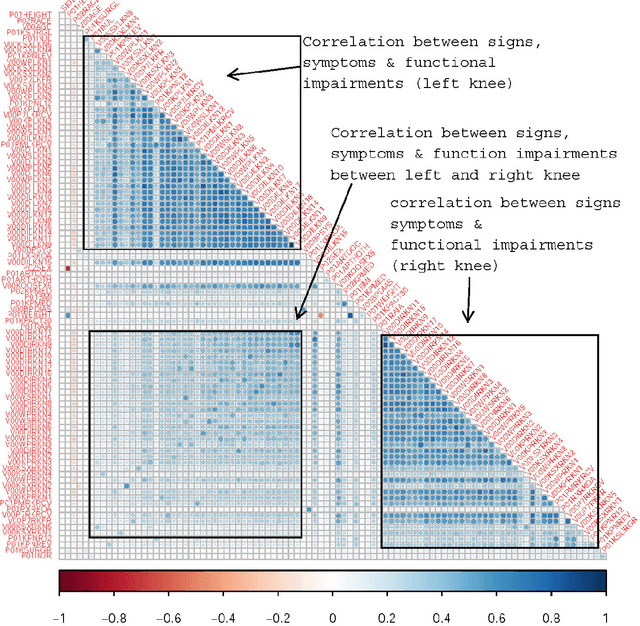
Knee osteoarthritis (KOA) is a disease that impairs knee function and causes pain. A radiologist reviews knee X-ray images and grades the severity level of the impairments according to the Kellgren and Lawrence grading scheme; a five-point ordinal scale (0--4). In this study, we used Elastic Net (EN) and Random Forests (RF) to build predictive models using patient assessment data (i.e. signs and symptoms of both knees and medication use) and a convolution neural network (CNN) trained using X-ray images only. Linear mixed effect models (LMM) were used to model the within subject correlation between the two knees. The root mean squared error for the CNN, EN, and RF models was 0.77, 0.97, and 0.94 respectively. The LMM shows similar overall prediction accuracy as the EN regression but correctly accounted for the hierarchical structure of the data resulting in more reliable inference. Useful explanatory variables were identified that could be used for patient monitoring before X-ray imaging. Our analyses suggest that the models trained for predicting the KOA severity levels achieve comparable results when modeling X-ray images and patient data. The subjectivity in the KL grade is still a primary concern.
* Published in Nature Scientific Reports, 2019
Automatic Detection of Knee Joints and Quantification of Knee Osteoarthritis Severity using Convolutional Neural Networks
Mar 29, 2017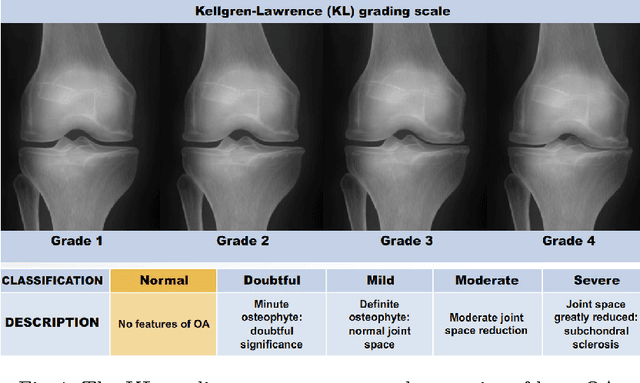

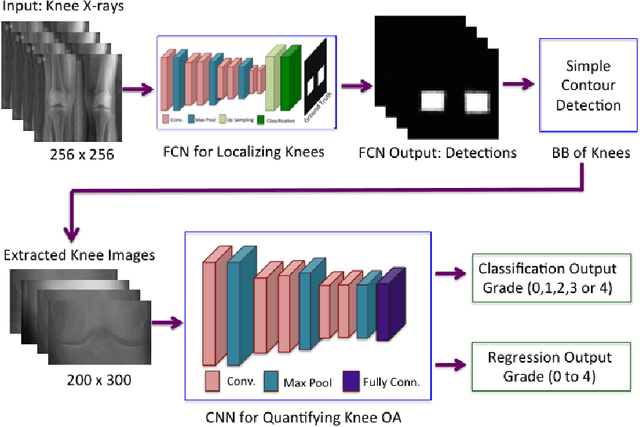

This paper introduces a new approach to automatically quantify the severity of knee OA using X-ray images. Automatically quantifying knee OA severity involves two steps: first, automatically localizing the knee joints; next, classifying the localized knee joint images. We introduce a new approach to automatically detect the knee joints using a fully convolutional neural network (FCN). We train convolutional neural networks (CNN) from scratch to automatically quantify the knee OA severity optimizing a weighted ratio of two loss functions: categorical cross-entropy and mean-squared loss. This joint training further improves the overall quantification of knee OA severity, with the added benefit of naturally producing simultaneous multi-class classification and regression outputs. Two public datasets are used to evaluate our approach, the Osteoarthritis Initiative (OAI) and the Multicenter Osteoarthritis Study (MOST), with extremely promising results that outperform existing approaches.