Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscerning Generic Event Boundaries in Long-Form Wild Videos
Paper and Code
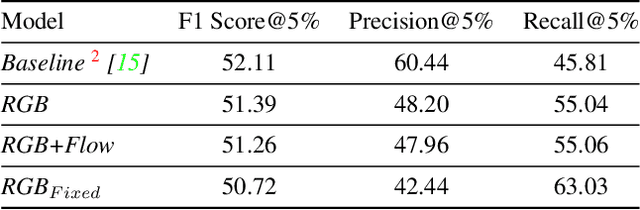
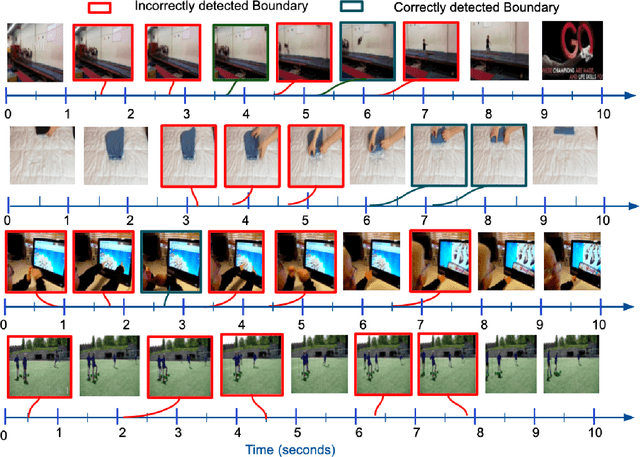
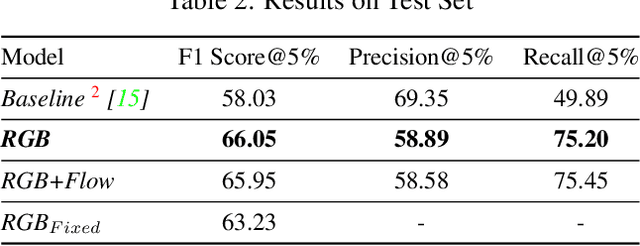
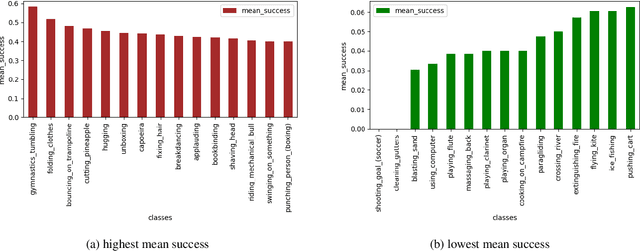
Detecting generic, taxonomy-free event boundaries invideos represents a major stride forward towards holisticvideo understanding. In this paper we present a technique forgeneric event boundary detection based on a two stream in-flated 3D convolutions architecture, which can learn spatio-temporal features from videos. Our work is inspired from theGeneric Event Boundary Detection Challenge (part of CVPR2021 Long Form Video Understanding- LOVEU Workshop).Throughout the paper we provide an in-depth analysis ofthe experiments performed along with an interpretation ofthe results obtained.
* Technical Report for Generic Event Boundary Challenge - LOVEU
Challenge (CVPR 2021)
View paper on