 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Graph-based Total Variation for Tomographic Reconstructions
Mar 14, 2018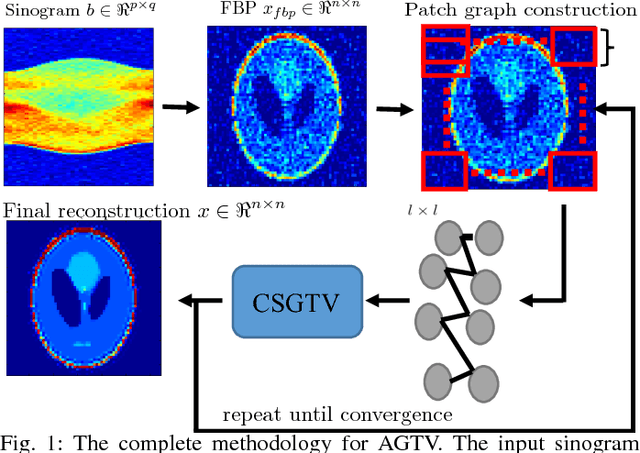
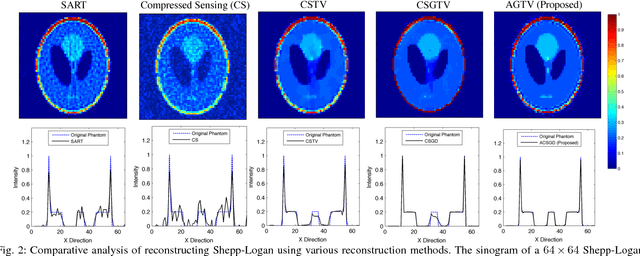
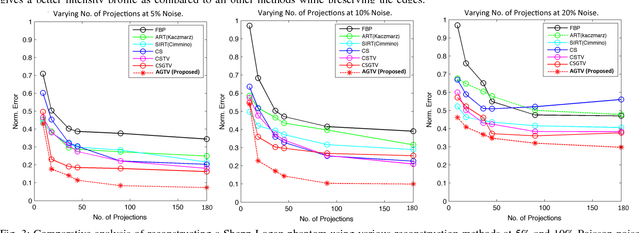
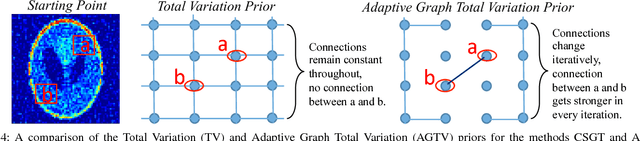
Sparsity exploiting image reconstruction (SER) methods have been extensively used with Total Variation (TV) regularization for tomographic reconstructions. Local TV methods fail to preserve texture details and often create additional artefacts due to over-smoothing. Non-Local TV (NLTV) methods have been proposed as a solution to this but they either lack continuous updates due to computational constraints or limit the locality to a small region. In this paper, we propose Adaptive Graph-based TV (AGTV). The proposed method goes beyond spatial similarity between different regions of an image being reconstructed by establishing a connection between similar regions in the entire image regardless of spatial distance. As compared to NLTV the proposed method is computationally efficient and involves updating the graph prior during every iteration making the connection between similar regions stronger. Moreover, it promotes sparsity in the wavelet and graph gradient domains. Since TV is a special case of graph TV the proposed method can also be seen as a generalization of SER and TV methods.
Multilinear Low-Rank Tensors on Graphs & Applications
Nov 15, 2016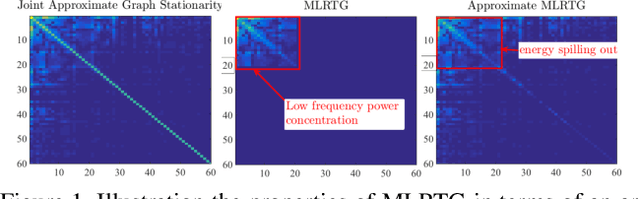

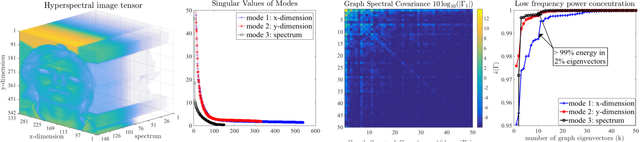

We propose a new framework for the analysis of low-rank tensors which lies at the intersection of spectral graph theory and signal processing. As a first step, we present a new graph based low-rank decomposition which approximates the classical low-rank SVD for matrices and multi-linear SVD for tensors. Then, building on this novel decomposition we construct a general class of convex optimization problems for approximately solving low-rank tensor inverse problems, such as tensor Robust PCA. The whole framework is named as 'Multilinear Low-rank tensors on Graphs (MLRTG)'. Our theoretical analysis shows: 1) MLRTG stands on the notion of approximate stationarity of multi-dimensional signals on graphs and 2) the approximation error depends on the eigen gaps of the graphs. We demonstrate applications for a wide variety of 4 artificial and 12 real tensor datasets, such as EEG, FMRI, BCI, surveillance videos and hyperspectral images. Generalization of the tensor concepts to non-euclidean domain, orders of magnitude speed-up, low-memory requirement and significantly enhanced performance at low SNR are the key aspects of our framework.
Compressive PCA for Low-Rank Matrices on Graphs
Oct 04, 2016


We introduce a novel framework for an approxi- mate recovery of data matrices which are low-rank on graphs, from sampled measurements. The rows and columns of such matrices belong to the span of the first few eigenvectors of the graphs constructed between their rows and columns. We leverage this property to recover the non-linear low-rank structures efficiently from sampled data measurements, with a low cost (linear in n). First, a Resrtricted Isometry Property (RIP) condition is introduced for efficient uniform sampling of the rows and columns of such matrices based on the cumulative coherence of graph eigenvectors. Secondly, a state-of-the-art fast low-rank recovery method is suggested for the sampled data. Finally, several efficient, parallel and parameter-free decoders are presented along with their theoretical analysis for decoding the low-rank and cluster indicators for the full data matrix. Thus, we overcome the computational limitations of the standard linear low-rank recovery methods for big datasets. Our method can also be seen as a major step towards efficient recovery of non- linear low-rank structures. For a matrix of size n X p, on a single core machine, our method gains a speed up of $p^2/k$ over Robust Principal Component Analysis (RPCA), where k << p is the subspace dimension. Numerically, we can recover a low-rank matrix of size 10304 X 1000, 100 times faster than Robust PCA.
Low-Rank Matrices on Graphs: Generalized Recovery & Applications
May 25, 2016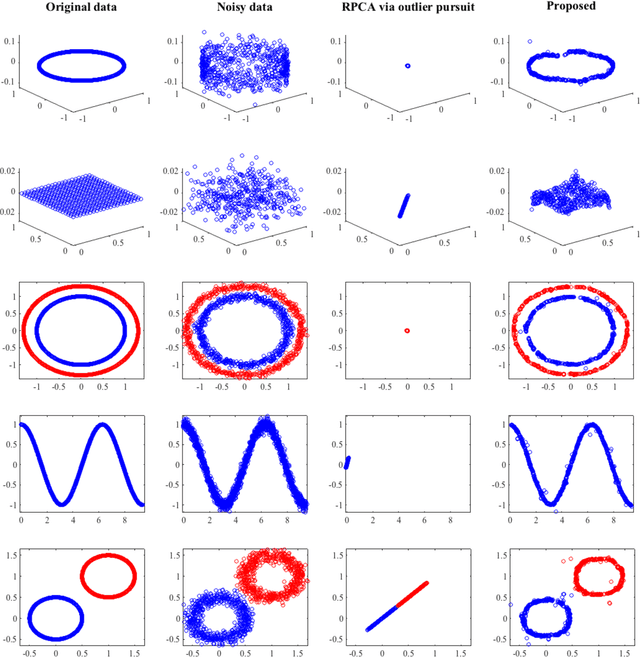
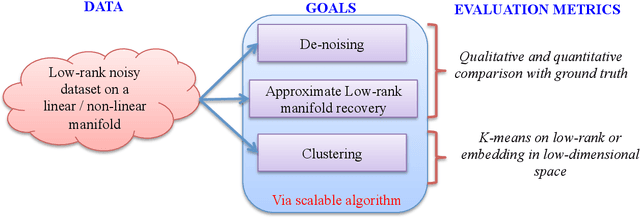

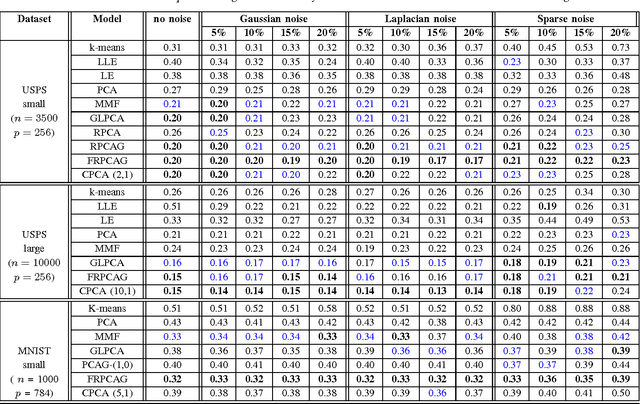
Many real world datasets subsume a linear or non-linear low-rank structure in a very low-dimensional space. Unfortunately, one often has very little or no information about the geometry of the space, resulting in a highly under-determined recovery problem. Under certain circumstances, state-of-the-art algorithms provide an exact recovery for linear low-rank structures but at the expense of highly inscalable algorithms which use nuclear norm. However, the case of non-linear structures remains unresolved. We revisit the problem of low-rank recovery from a totally different perspective, involving graphs which encode pairwise similarity between the data samples and features. Surprisingly, our analysis confirms that it is possible to recover many approximate linear and non-linear low-rank structures with recovery guarantees with a set of highly scalable and efficient algorithms. We call such data matrices as \textit{Low-Rank matrices on graphs} and show that many real world datasets satisfy this assumption approximately due to underlying stationarity. Our detailed theoretical and experimental analysis unveils the power of the simple, yet very novel recovery framework \textit{Fast Robust PCA on Graphs}
Graph Based Sinogram Denoising for Tomographic Reconstructions
Mar 14, 2016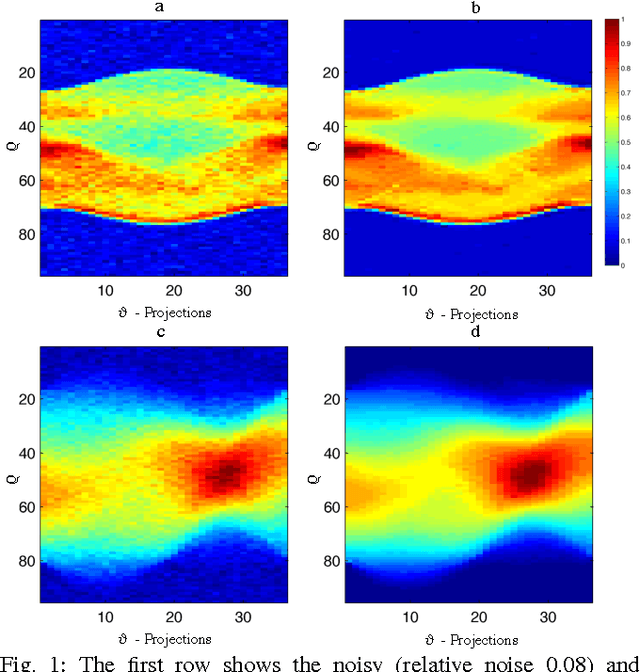
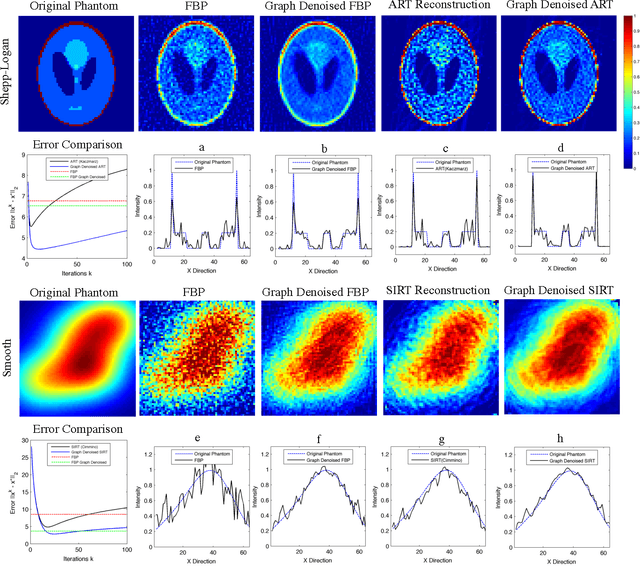
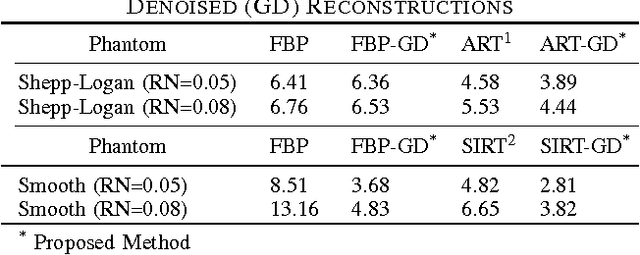
Limited data and low dose constraints are common problems in a variety of tomographic reconstruction paradigms which lead to noisy and incomplete data. Over the past few years sinogram denoising has become an essential pre-processing step for low dose Computed Tomographic (CT) reconstructions. We propose a novel sinogram denoising algorithm inspired by the modern field of signal processing on graphs. Graph based methods often perform better than standard filtering operations since they can exploit the signal structure. This makes the sinogram an ideal candidate for graph based denoising since it generally has a piecewise smooth structure. We test our method with a variety of phantoms and different reconstruction methods. Our numerical study shows that the proposed algorithm improves the performance of analytical filtered back-projection (FBP) and iterative methods ART (Kaczmarz) and SIRT (Cimmino).We observed that graph denoised sinogram always minimizes the error measure and improves the accuracy of the solution as compared to regular reconstructions.
Fast Robust PCA on Graphs
Jan 25, 2016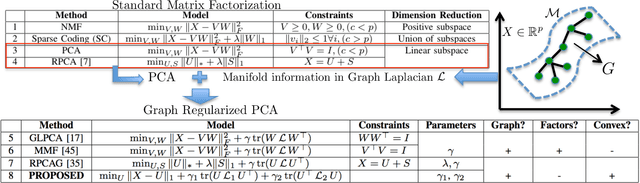
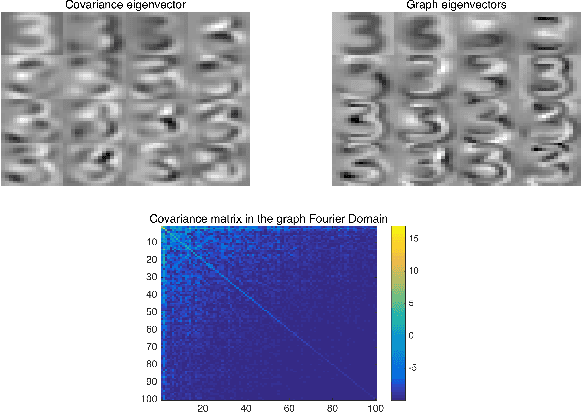
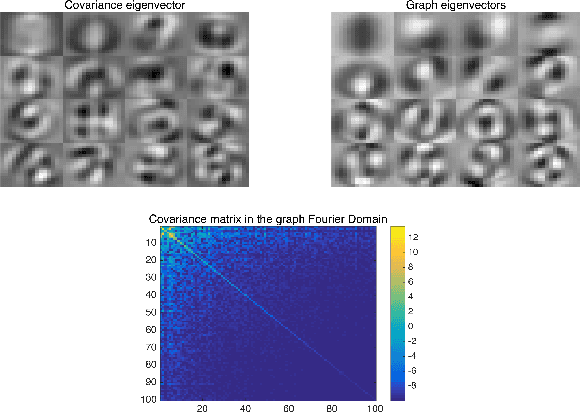
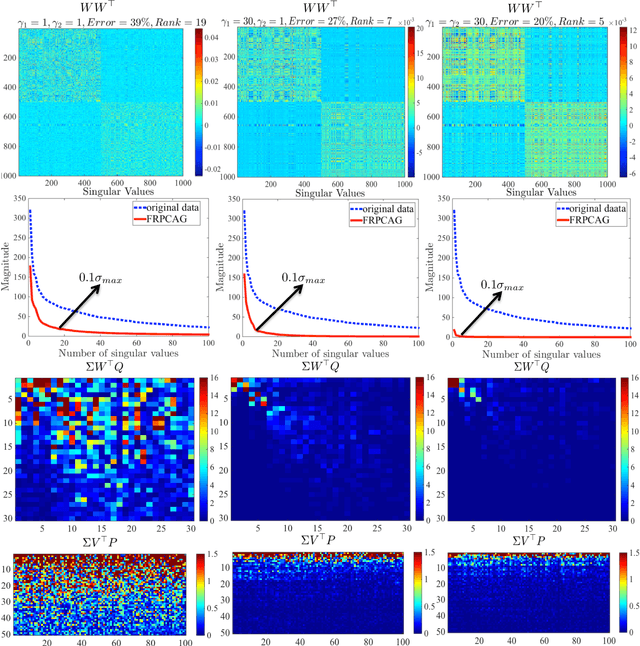
Mining useful clusters from high dimensional data has received significant attention of the computer vision and pattern recognition community in the recent years. Linear and non-linear dimensionality reduction has played an important role to overcome the curse of dimensionality. However, often such methods are accompanied with three different problems: high computational complexity (usually associated with the nuclear norm minimization), non-convexity (for matrix factorization methods) and susceptibility to gross corruptions in the data. In this paper we propose a principal component analysis (PCA) based solution that overcomes these three issues and approximates a low-rank recovery method for high dimensional datasets. We target the low-rank recovery by enforcing two types of graph smoothness assumptions, one on the data samples and the other on the features by designing a convex optimization problem. The resulting algorithm is fast, efficient and scalable for huge datasets with O(nlog(n)) computational complexity in the number of data samples. It is also robust to gross corruptions in the dataset as well as to the model parameters. Clustering experiments on 7 benchmark datasets with different types of corruptions and background separation experiments on 3 video datasets show that our proposed model outperforms 10 state-of-the-art dimensionality reduction models. Our theoretical analysis proves that the proposed model is able to recover approximate low-rank representations with a bounded error for clusterable data.
Robust Principal Component Analysis on Graphs
Apr 23, 2015
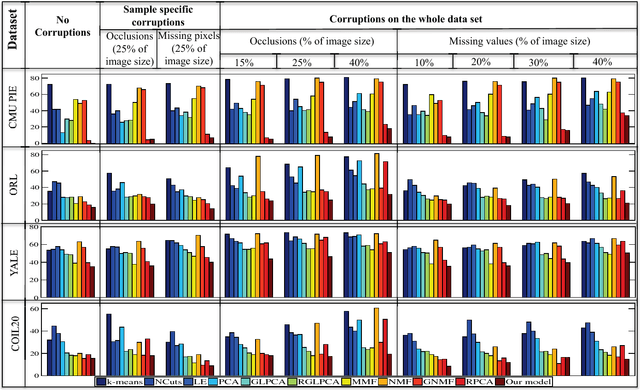
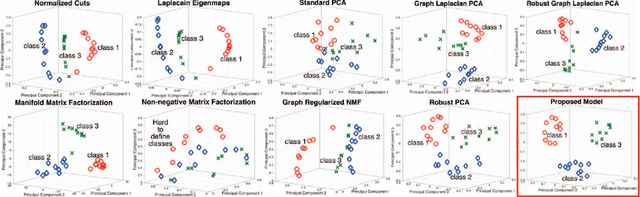
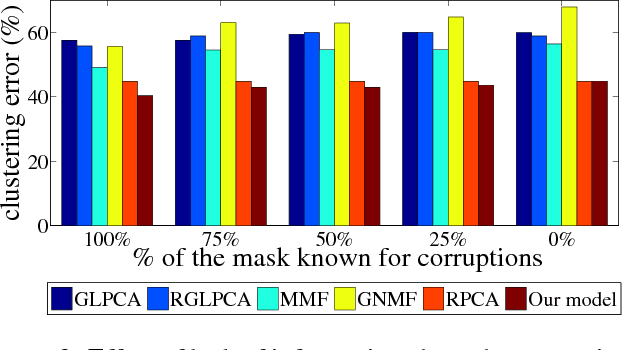
Principal Component Analysis (PCA) is the most widely used tool for linear dimensionality reduction and clustering. Still it is highly sensitive to outliers and does not scale well with respect to the number of data samples. Robust PCA solves the first issue with a sparse penalty term. The second issue can be handled with the matrix factorization model, which is however non-convex. Besides, PCA based clustering can also be enhanced by using a graph of data similarity. In this article, we introduce a new model called "Robust PCA on Graphs" which incorporates spectral graph regularization into the Robust PCA framework. Our proposed model benefits from 1) the robustness of principal components to occlusions and missing values, 2) enhanced low-rank recovery, 3) improved clustering property due to the graph smoothness assumption on the low-rank matrix, and 4) convexity of the resulting optimization problem. Extensive experiments on 8 benchmark, 3 video and 2 artificial datasets with corruptions clearly reveal that our model outperforms 10 other state-of-the-art models in its clustering and low-rank recovery tasks.