 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Duality for Sparse Support Vector Machines
Jan 28, 2026Due to the rise of cardinality minimization in optimization, sparse support vector machines (SSVMs) have attracted much attention lately and show certain empirical advantages over convex SVMs. A common way to derive an SSVM is to add a cardinality function such as $\ell_0$-norm to the dual problem of a convex SVM. However, this process lacks theoretical justification. This paper fills the gap by developing a local duality theory for such an SSVM formulation and exploring its relationship with the hinge-loss SVM (hSVM) and the ramp-loss SVM (rSVM). In particular, we prove that the derived SSVM is exactly the dual problem of the 0/1-loss SVM, and the linear representer theorem holds for their local solutions. The local solution of SSVM also provides guidelines on selecting hyperparameters of hSVM and rSVM. {Under specific conditions, we show that a sequence of global solutions of hSVM converges to a local solution of 0/1-loss SVM. Moreover, a local minimizer of 0/1-loss SVM is a local minimizer of rSVM.} This explains why a local solution induced by SSVM outperforms hSVM and rSVM in the prior empirical study. We further conduct numerical tests on real datasets and demonstrate potential advantages of SSVM by working with locally nice solutions proposed in this paper.
0/1 Deep Neural Networks via Block Coordinate Descent
Jun 19, 2022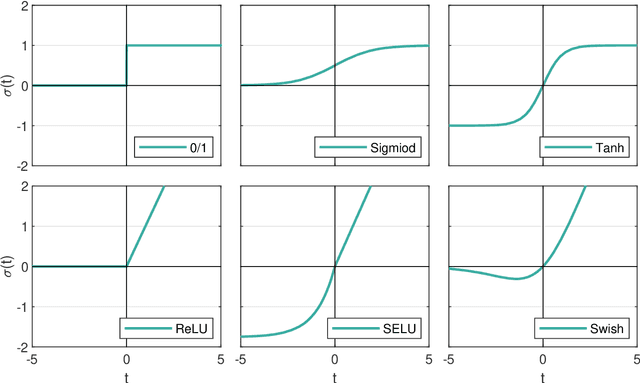
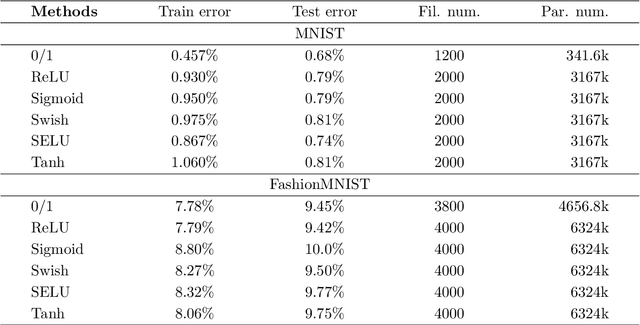
The step function is one of the simplest and most natural activation functions for deep neural networks (DNNs). As it counts 1 for positive variables and 0 for others, its intrinsic characteristics (e.g., discontinuity and no viable information of subgradients) impede its development for several decades. Even if there is an impressive body of work on designing DNNs with continuous activation functions that can be deemed as surrogates of the step function, it is still in the possession of some advantageous properties, such as complete robustness to outliers and being capable of attaining the best learning-theoretic guarantee of predictive accuracy. Hence, in this paper, we aim to train DNNs with the step function used as an activation function (dubbed as 0/1 DNNs). We first reformulate 0/1 DNNs as an unconstrained optimization problem and then solve it by a block coordinate descend (BCD) method. Moreover, we acquire closed-form solutions for sub-problems of BCD as well as its convergence properties. Furthermore, we also integrate $\ell_{2,0}$-regularization into 0/1 DNN to accelerate the training process and compress the network scale. As a result, the proposed algorithm has a high performance on classifying MNIST and Fashion-MNIST datasets.
Support Vector Machine Classifier via $L_{0/1}$ Soft-Margin Loss
Dec 16, 2019
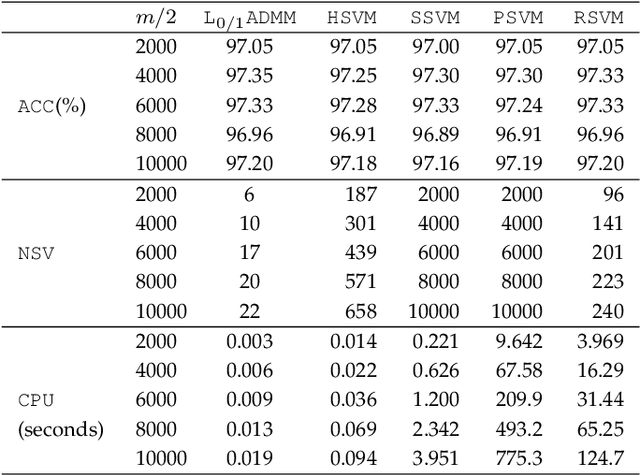
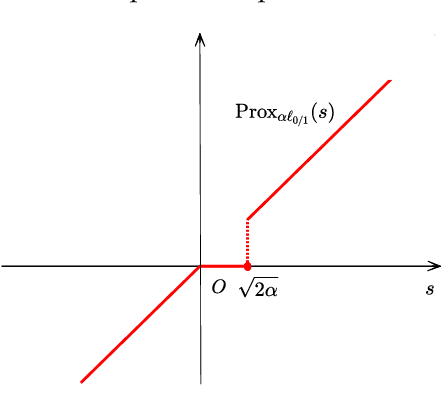
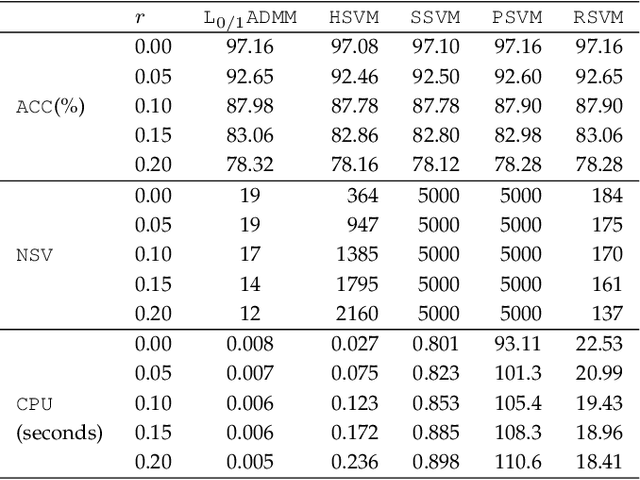
Support vector machine (SVM) has attracted great attentions for the last two decades due to its extensive applications, and thus numerous optimization models have been proposed. To distinguish all of them, in this paper, we introduce a new model equipped with an $L_{0/1}$ soft-margin loss (dubbed as $L_{0/1}$-SVM) which well captures the nature of the binary classification. Many of the existing convex/non-convex soft-margin losses can be viewed as a surrogate of the $L_{0/1}$ soft-margin loss. Despite the discrete nature of $L_{0/1}$, we manage to establish the existence of global minimizer of the new model as well as revealing the relationship among its minimizers and KKT/P-stationary points. These theoretical properties allow us to take advantage of the alternating direction method of multipliers. In addition, the $L_{0/1}$-support vector operator is introduced as a filter to prevent outliers from being support vectors during the training process. Hence, the method is expected to be relatively robust. Finally, numerical experiments demonstrate that our proposed method generates better performance in terms of much shorter computational time with much fewer number of support vectors when against with some other leading methods in areas of SVM. When the data size gets bigger, its advantage becomes more evident.
Single Versus Union: Non-parallel Support Vector Machine Frameworks
Oct 22, 2019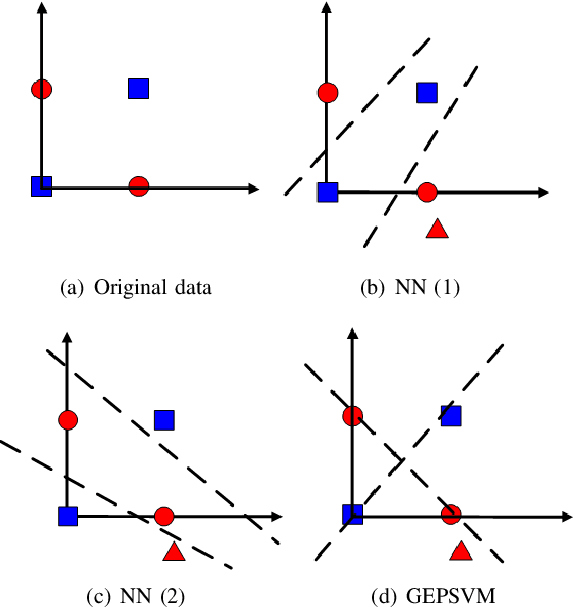
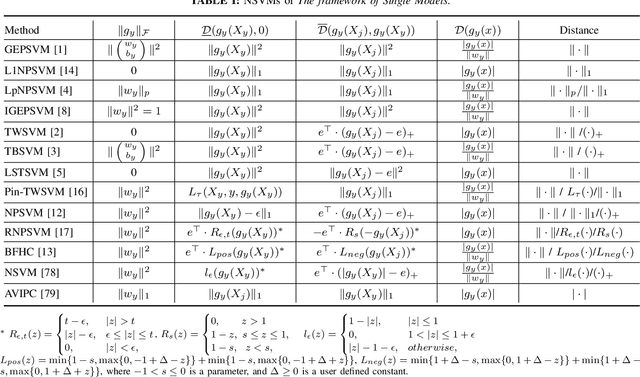

Considering the classification problem, we summarize the nonparallel support vector machines with the nonparallel hyperplanes to two types of frameworks. The first type constructs the hyperplanes separately. It solves a series of small optimization problems to obtain a series of hyperplanes, but is hard to measure the loss of each sample. The other type constructs all the hyperplanes simultaneously, and it solves one big optimization problem with the ascertained loss of each sample. We give the characteristics of each framework and compare them carefully. In addition, based on the second framework, we construct a max-min distance-based nonparallel support vector machine for multiclass classification problem, called NSVM. It constructs hyperplanes with large distance margin by solving an optimization problem. Experimental results on benchmark data sets and human face databases show the advantages of our NSVM.
Sparse and Low-Rank Covariance Matrices Estimation
Aug 07, 2014


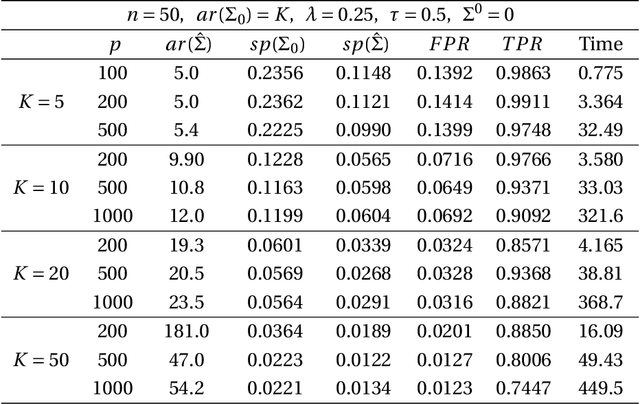
This paper aims at achieving a simultaneously sparse and low-rank estimator from the semidefinite population covariance matrices. We first benefit from a convex optimization which develops $l_1$-norm penalty to encourage the sparsity and nuclear norm to favor the low-rank property. For the proposed estimator, we then prove that with large probability, the Frobenious norm of the estimation rate can be of order $O(\sqrt{s(\log{r})/n})$ under a mild case, where $s$ and $r$ denote the number of sparse entries and the rank of the population covariance respectively, $n$ notes the sample capacity. Finally an efficient alternating direction method of multipliers with global convergence is proposed to tackle this problem, and meantime merits of the approach are also illustrated by practicing numerical simulations.