 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering in Dynamic Environments: A Framework for Benchmark Dataset Generation With Heterogeneous Changes
Feb 24, 2024



Clustering in dynamic environments is of increasing importance, with broad applications ranging from real-time data analysis and online unsupervised learning to dynamic facility location problems. While meta-heuristics have shown promising effectiveness in static clustering tasks, their application for tracking optimal clustering solutions or robust clustering over time in dynamic environments remains largely underexplored. This is partly due to a lack of dynamic datasets with diverse, controllable, and realistic dynamic characteristics, hindering systematic performance evaluations of clustering algorithms in various dynamic scenarios. This deficiency leads to a gap in our understanding and capability to effectively design algorithms for clustering in dynamic environments. To bridge this gap, this paper introduces the Dynamic Dataset Generator (DDG). DDG features multiple dynamic Gaussian components integrated with a range of heterogeneous, local, and global changes. These changes vary in spatial and temporal severity, patterns, and domain of influence, providing a comprehensive tool for simulating a wide range of dynamic scenarios.
Semantic-Preserving Feature Partitioning for Multi-View Ensemble Learning
Jan 11, 2024In machine learning, the exponential growth of data and the associated ``curse of dimensionality'' pose significant challenges, particularly with expansive yet sparse datasets. Addressing these challenges, multi-view ensemble learning (MEL) has emerged as a transformative approach, with feature partitioning (FP) playing a pivotal role in constructing artificial views for MEL. Our study introduces the Semantic-Preserving Feature Partitioning (SPFP) algorithm, a novel method grounded in information theory. The SPFP algorithm effectively partitions datasets into multiple semantically consistent views, enhancing the MEL process. Through extensive experiments on eight real-world datasets, ranging from high-dimensional with limited instances to low-dimensional with high instances, our method demonstrates notable efficacy. It maintains model accuracy while significantly improving uncertainty measures in scenarios where high generalization performance is achievable. Conversely, it retains uncertainty metrics while enhancing accuracy where high generalization accuracy is less attainable. An effect size analysis further reveals that the SPFP algorithm outperforms benchmark models by large effect size and reduces computational demands through effective dimensionality reduction. The substantial effect sizes observed in most experiments underscore the algorithm's significant improvements in model performance.
Noise-Augmented Boruta: The Neural Network Perturbation Infusion with Boruta Feature Selection
Sep 18, 2023

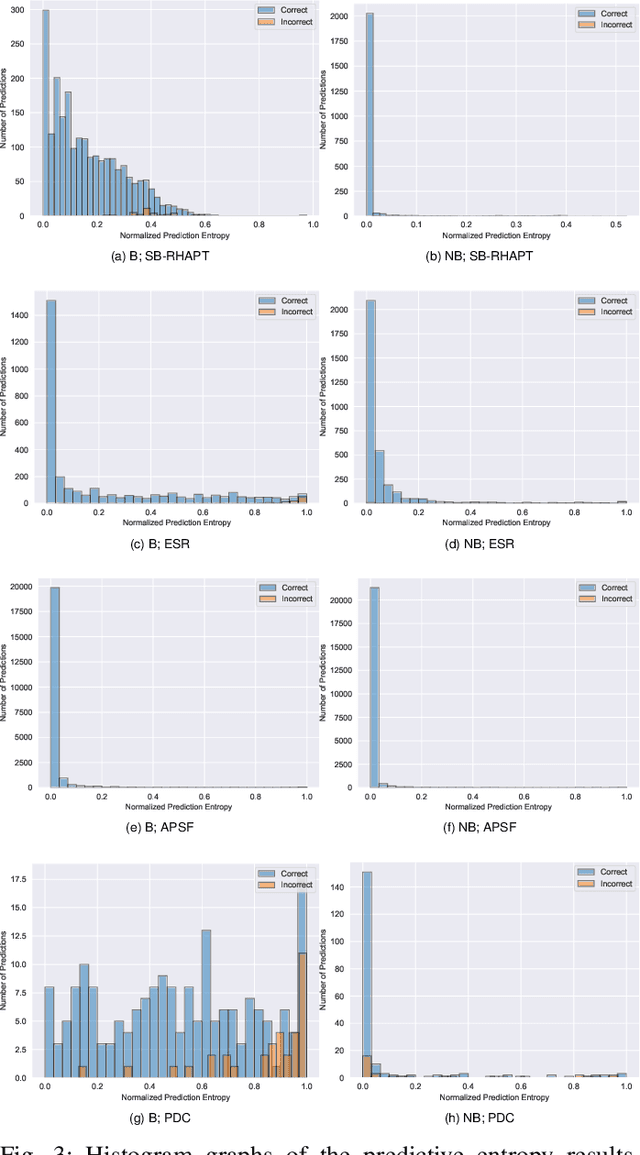
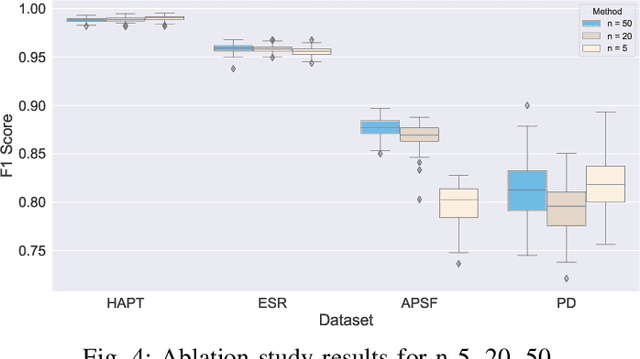
With the surge in data generation, both vertically (i.e., volume of data) and horizontally (i.e., dimensionality), the burden of the curse of dimensionality has become increasingly palpable. Feature selection, a key facet of dimensionality reduction techniques, has advanced considerably to address this challenge. One such advancement is the Boruta feature selection algorithm, which successfully discerns meaningful features by contrasting them to their permutated counterparts known as shadow features. However, the significance of a feature is shaped more by the data's overall traits than by its intrinsic value, a sentiment echoed in the conventional Boruta algorithm where shadow features closely mimic the characteristics of the original ones. Building on this premise, this paper introduces an innovative approach to the Boruta feature selection algorithm by incorporating noise into the shadow variables. Drawing parallels from the perturbation analysis framework of artificial neural networks, this evolved version of the Boruta method is presented. Rigorous testing on four publicly available benchmark datasets revealed that this proposed technique outperforms the classic Boruta algorithm, underscoring its potential for enhanced, accurate feature selection.