 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Augmented Boruta: The Neural Network Perturbation Infusion with Boruta Feature Selection
Paper and Code
Sep 18, 2023

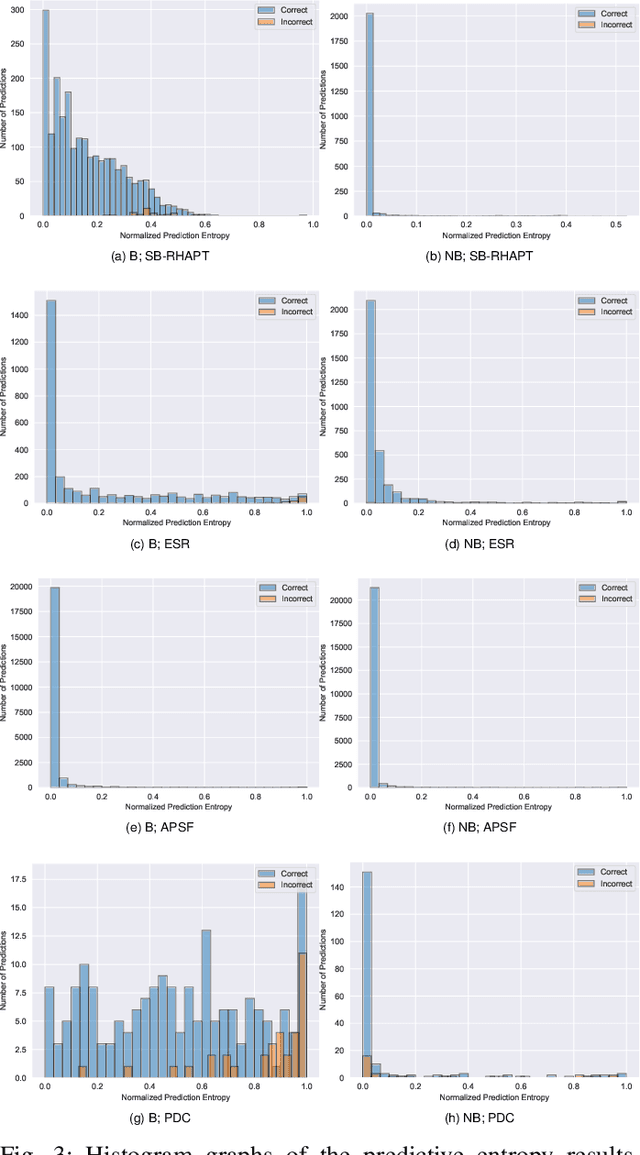
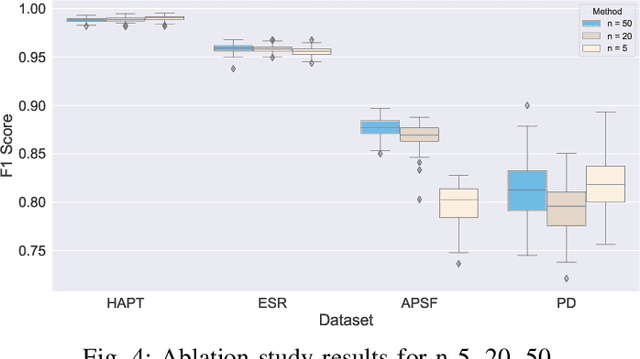
With the surge in data generation, both vertically (i.e., volume of data) and horizontally (i.e., dimensionality), the burden of the curse of dimensionality has become increasingly palpable. Feature selection, a key facet of dimensionality reduction techniques, has advanced considerably to address this challenge. One such advancement is the Boruta feature selection algorithm, which successfully discerns meaningful features by contrasting them to their permutated counterparts known as shadow features. However, the significance of a feature is shaped more by the data's overall traits than by its intrinsic value, a sentiment echoed in the conventional Boruta algorithm where shadow features closely mimic the characteristics of the original ones. Building on this premise, this paper introduces an innovative approach to the Boruta feature selection algorithm by incorporating noise into the shadow variables. Drawing parallels from the perturbation analysis framework of artificial neural networks, this evolved version of the Boruta method is presented. Rigorous testing on four publicly available benchmark datasets revealed that this proposed technique outperforms the classic Boruta algorithm, underscoring its potential for enhanced, accurate feature selection.