 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Preserving Feature Partitioning for Multi-View Ensemble Learning
Jan 11, 2024In machine learning, the exponential growth of data and the associated ``curse of dimensionality'' pose significant challenges, particularly with expansive yet sparse datasets. Addressing these challenges, multi-view ensemble learning (MEL) has emerged as a transformative approach, with feature partitioning (FP) playing a pivotal role in constructing artificial views for MEL. Our study introduces the Semantic-Preserving Feature Partitioning (SPFP) algorithm, a novel method grounded in information theory. The SPFP algorithm effectively partitions datasets into multiple semantically consistent views, enhancing the MEL process. Through extensive experiments on eight real-world datasets, ranging from high-dimensional with limited instances to low-dimensional with high instances, our method demonstrates notable efficacy. It maintains model accuracy while significantly improving uncertainty measures in scenarios where high generalization performance is achievable. Conversely, it retains uncertainty metrics while enhancing accuracy where high generalization accuracy is less attainable. An effect size analysis further reveals that the SPFP algorithm outperforms benchmark models by large effect size and reduces computational demands through effective dimensionality reduction. The substantial effect sizes observed in most experiments underscore the algorithm's significant improvements in model performance.
Noise-Augmented Boruta: The Neural Network Perturbation Infusion with Boruta Feature Selection
Sep 18, 2023

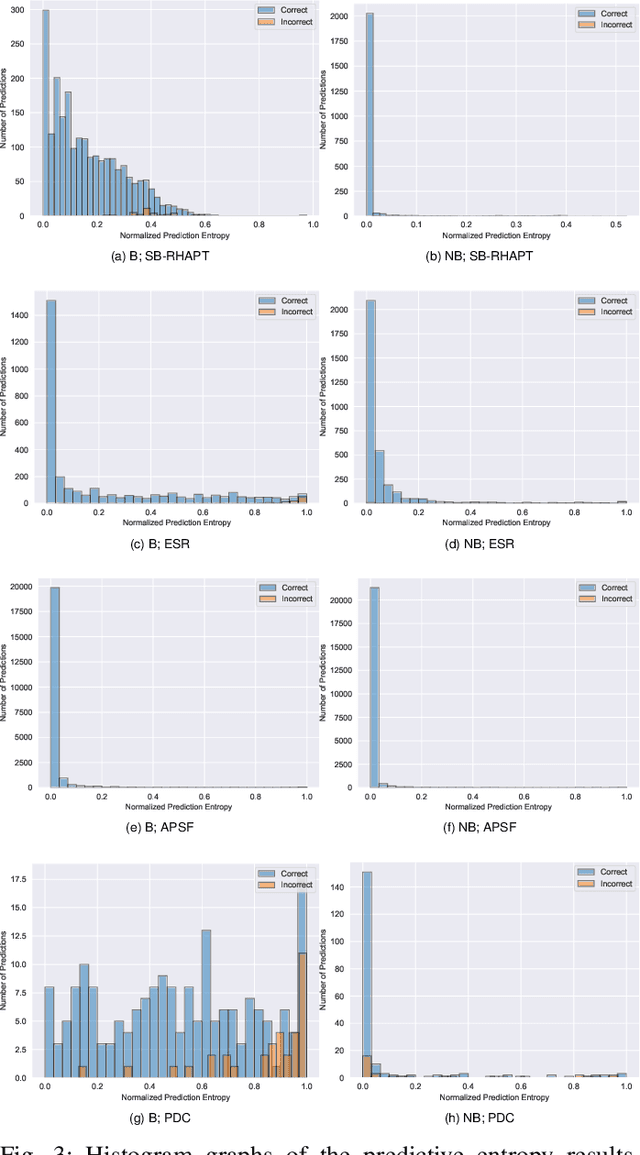
With the surge in data generation, both vertically (i.e., volume of data) and horizontally (i.e., dimensionality), the burden of the curse of dimensionality has become increasingly palpable. Feature selection, a key facet of dimensionality reduction techniques, has advanced considerably to address this challenge. One such advancement is the Boruta feature selection algorithm, which successfully discerns meaningful features by contrasting them to their permutated counterparts known as shadow features. However, the significance of a feature is shaped more by the data's overall traits than by its intrinsic value, a sentiment echoed in the conventional Boruta algorithm where shadow features closely mimic the characteristics of the original ones. Building on this premise, this paper introduces an innovative approach to the Boruta feature selection algorithm by incorporating noise into the shadow variables. Drawing parallels from the perturbation analysis framework of artificial neural networks, this evolved version of the Boruta method is presented. Rigorous testing on four publicly available benchmark datasets revealed that this proposed technique outperforms the classic Boruta algorithm, underscoring its potential for enhanced, accurate feature selection.
Meta-learning approaches for few-shot learning: A survey of recent advances
Mar 13, 2023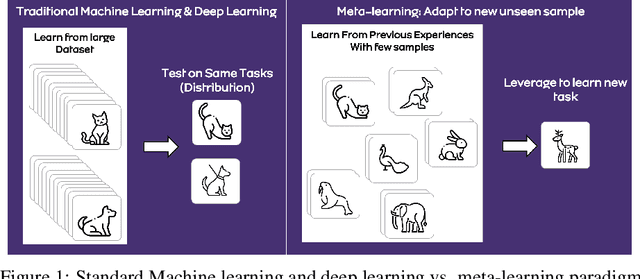

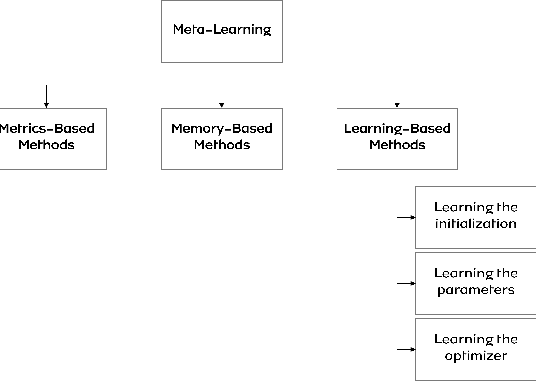
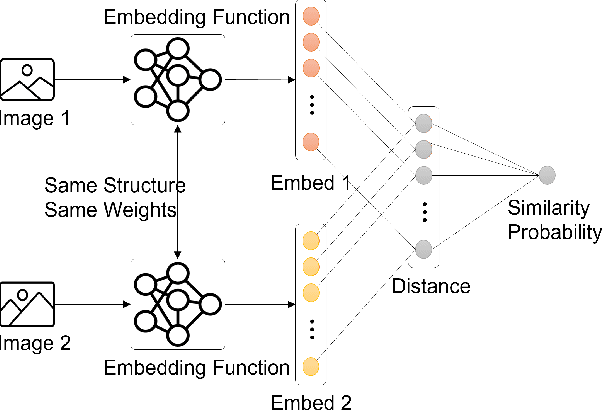
Despite its astounding success in learning deeper multi-dimensional data, the performance of deep learning declines on new unseen tasks mainly due to its focus on same-distribution prediction. Moreover, deep learning is notorious for poor generalization from few samples. Meta-learning is a promising approach that addresses these issues by adapting to new tasks with few-shot datasets. This survey first briefly introduces meta-learning and then investigates state-of-the-art meta-learning methods and recent advances in: (I) metric-based, (II) memory-based, (III), and learning-based methods. Finally, current challenges and insights for future researches are discussed.
Uncertainty-Aware Credit Card Fraud Detection Using Deep Learning
Jul 28, 2021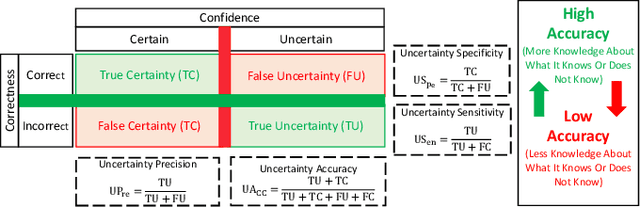
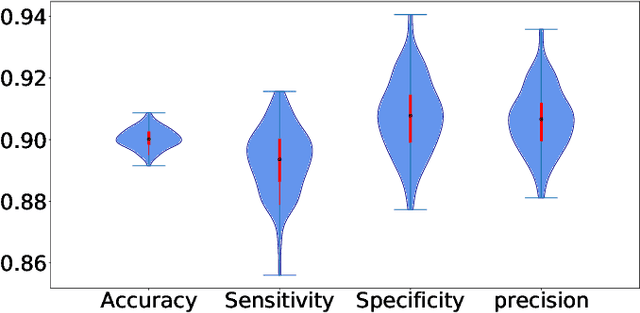
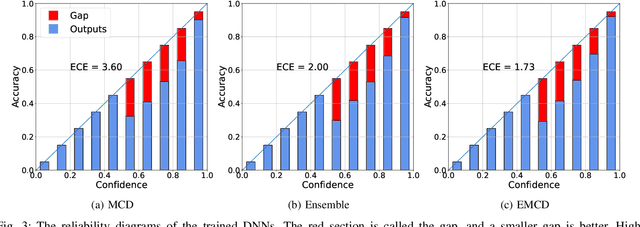
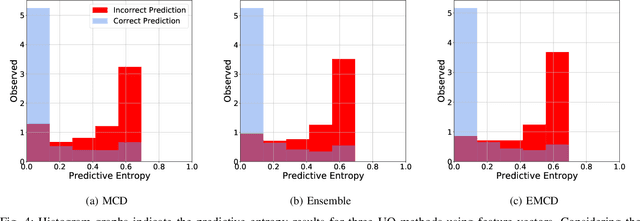
Countless research works of deep neural networks (DNNs) in the task of credit card fraud detection have focused on improving the accuracy of point predictions and mitigating unwanted biases by building different network architectures or learning models. Quantifying uncertainty accompanied by point estimation is essential because it mitigates model unfairness and permits practitioners to develop trustworthy systems which abstain from suboptimal decisions due to low confidence. Explicitly, assessing uncertainties associated with DNNs predictions is critical in real-world card fraud detection settings for characteristic reasons, including (a) fraudsters constantly change their strategies, and accordingly, DNNs encounter observations that are not generated by the same process as the training distribution, (b) owing to the time-consuming process, very few transactions are timely checked by professional experts to update DNNs. Therefore, this study proposes three uncertainty quantification (UQ) techniques named Monte Carlo dropout, ensemble, and ensemble Monte Carlo dropout for card fraud detection applied on transaction data. Moreover, to evaluate the predictive uncertainty estimates, UQ confusion matrix and several performance metrics are utilized. Through experimental results, we show that the ensemble is more effective in capturing uncertainty corresponding to generated predictions. Additionally, we demonstrate that the proposed UQ methods provide extra insight to the point predictions, leading to elevate the fraud prevention process.
An Uncertainty-Aware Deep Learning Framework for Defect Detection in Casting Products
Jul 24, 2021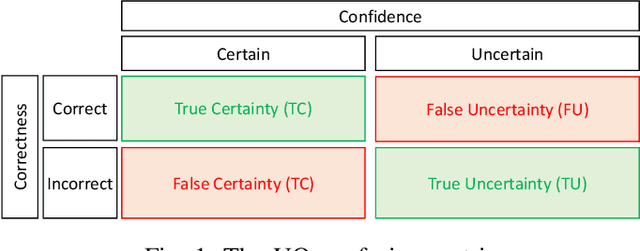
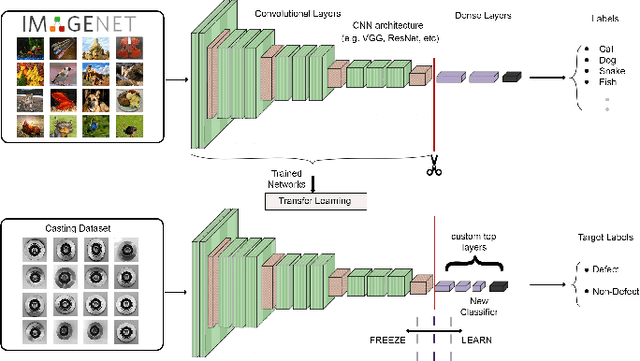
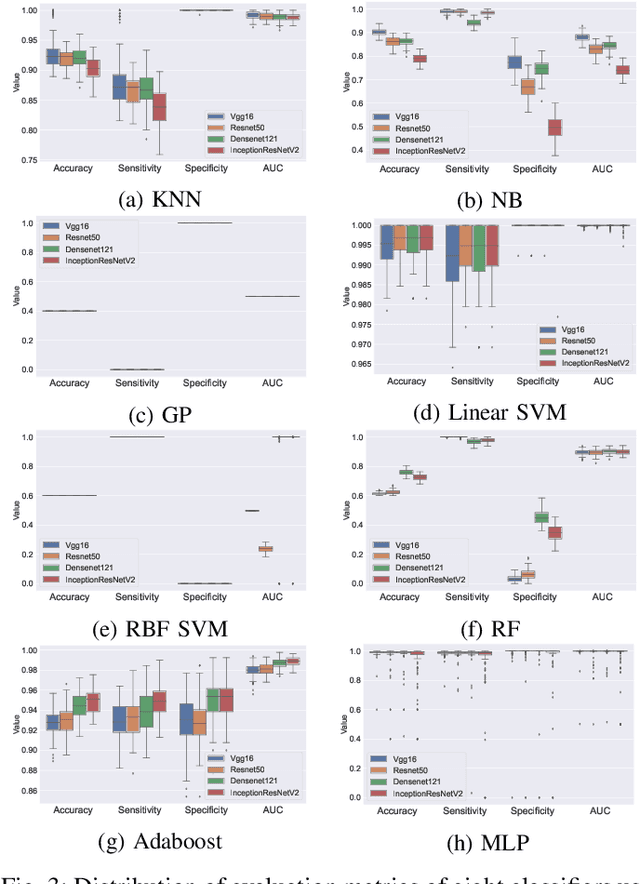
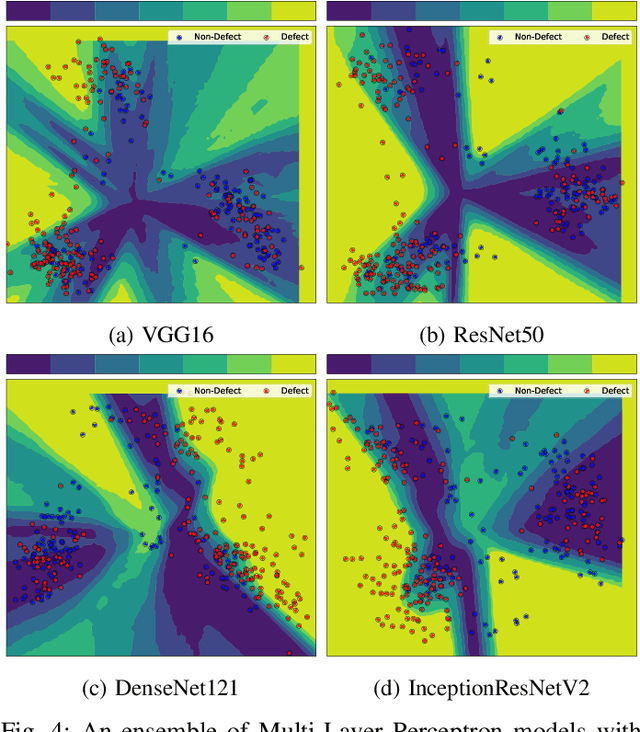
Defects are unavoidable in casting production owing to the complexity of the casting process. While conventional human-visual inspection of casting products is slow and unproductive in mass productions, an automatic and reliable defect detection not just enhances the quality control process but positively improves productivity. However, casting defect detection is a challenging task due to diversity and variation in defects' appearance. Convolutional neural networks (CNNs) have been widely applied in both image classification and defect detection tasks. Howbeit, CNNs with frequentist inference require a massive amount of data to train on and still fall short in reporting beneficial estimates of their predictive uncertainty. Accordingly, leveraging the transfer learning paradigm, we first apply four powerful CNN-based models (VGG16, ResNet50, DenseNet121, and InceptionResNetV2) on a small dataset to extract meaningful features. Extracted features are then processed by various machine learning algorithms to perform the classification task. Simulation results demonstrate that linear support vector machine (SVM) and multi-layer perceptron (MLP) show the finest performance in defect detection of casting images. Secondly, to achieve a reliable classification and to measure epistemic uncertainty, we employ an uncertainty quantification (UQ) technique (ensemble of MLP models) using features extracted from four pre-trained CNNs. UQ confusion matrix and uncertainty accuracy metric are also utilized to evaluate the predictive uncertainty estimates. Comprehensive comparisons reveal that UQ method based on VGG16 outperforms others to fetch uncertainty. We believe an uncertainty-aware automatic defect detection solution will reinforce casting productions quality assurance.