 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatteReview: A Multi-Agent Framework for Systematic Review Automation Using Large Language Models
Jan 05, 2025

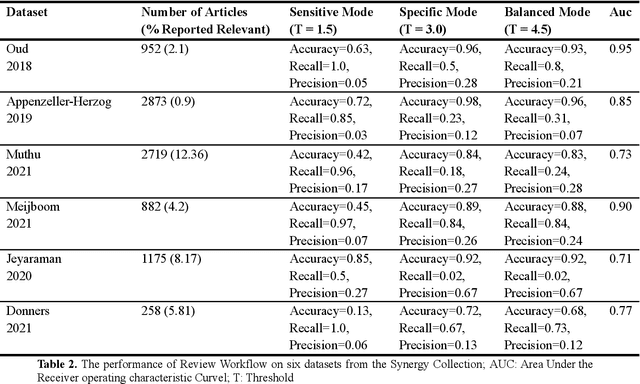
Systematic literature reviews and meta-analyses are essential for synthesizing research insights, but they remain time-intensive and labor-intensive due to the iterative processes of screening, evaluation, and data extraction. This paper introduces and evaluates LatteReview, a Python-based framework that leverages large language models (LLMs) and multi-agent systems to automate key elements of the systematic review process. Designed to streamline workflows while maintaining rigor, LatteReview utilizes modular agents for tasks such as title and abstract screening, relevance scoring, and structured data extraction. These agents operate within orchestrated workflows, supporting sequential and parallel review rounds, dynamic decision-making, and iterative refinement based on user feedback. LatteReview's architecture integrates LLM providers, enabling compatibility with both cloud-based and locally hosted models. The framework supports features such as Retrieval-Augmented Generation (RAG) for incorporating external context, multimodal reviews, Pydantic-based validation for structured inputs and outputs, and asynchronous programming for handling large-scale datasets. The framework is available on the GitHub repository, with detailed documentation and an installable package.
CONFLARE: CONFormal LArge language model REtrieval
Apr 04, 2024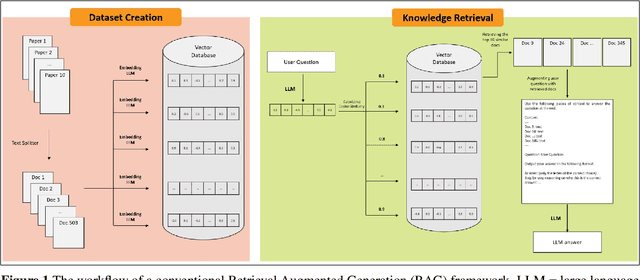
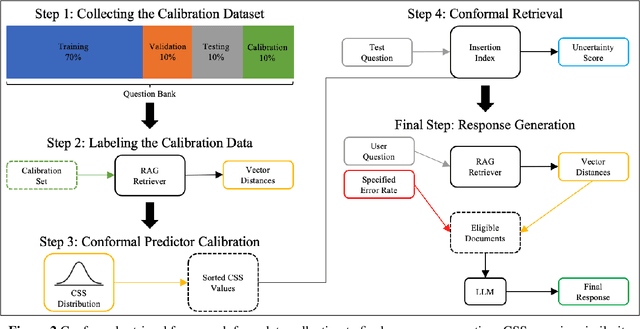


Retrieval-augmented generation (RAG) frameworks enable large language models (LLMs) to retrieve relevant information from a knowledge base and incorporate it into the context for generating responses. This mitigates hallucinations and allows for the updating of knowledge without retraining the LLM. However, RAG does not guarantee valid responses if retrieval fails to identify the necessary information as the context for response generation. Also, if there is contradictory content, the RAG response will likely reflect only one of the two possible responses. Therefore, quantifying uncertainty in the retrieval process is crucial for ensuring RAG trustworthiness. In this report, we introduce a four-step framework for applying conformal prediction to quantify retrieval uncertainty in RAG frameworks. First, a calibration set of questions answerable from the knowledge base is constructed. Each question's embedding is compared against document embeddings to identify the most relevant document chunks containing the answer and record their similarity scores. Given a user-specified error rate ({\alpha}), these similarity scores are then analyzed to determine a similarity score cutoff threshold. During inference, all chunks with similarity exceeding this threshold are retrieved to provide context to the LLM, ensuring the true answer is captured in the context with a (1-{\alpha}) confidence level. We provide a Python package that enables users to implement the entire workflow proposed in our work, only using LLMs and without human intervention.
TransDeepLab: Convolution-Free Transformer-based DeepLab v3+ for Medical Image Segmentation
Aug 01, 2022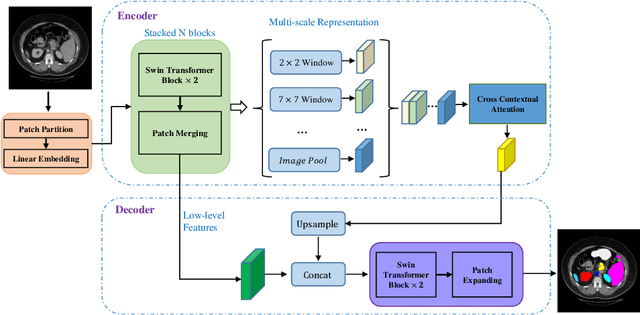
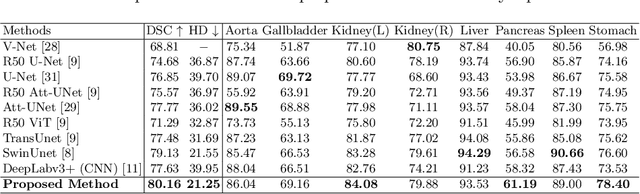
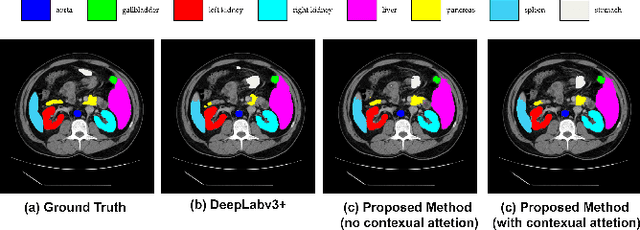
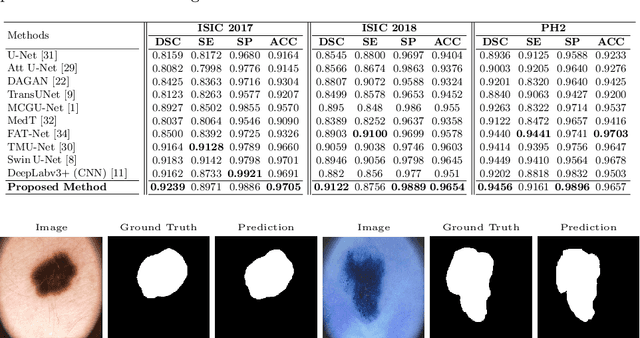
Convolutional neural networks (CNNs) have been the de facto standard in a diverse set of computer vision tasks for many years. Especially, deep neural networks based on seminal architectures such as U-shaped models with skip-connections or atrous convolution with pyramid pooling have been tailored to a wide range of medical image analysis tasks. The main advantage of such architectures is that they are prone to detaining versatile local features. However, as a general consensus, CNNs fail to capture long-range dependencies and spatial correlations due to the intrinsic property of confined receptive field size of convolution operations. Alternatively, Transformer, profiting from global information modelling that stems from the self-attention mechanism, has recently attained remarkable performance in natural language processing and computer vision. Nevertheless, previous studies prove that both local and global features are critical for a deep model in dense prediction, such as segmenting complicated structures with disparate shapes and configurations. To this end, this paper proposes TransDeepLab, a novel DeepLab-like pure Transformer for medical image segmentation. Specifically, we exploit hierarchical Swin-Transformer with shifted windows to extend the DeepLabv3 and model the Atrous Spatial Pyramid Pooling (ASPP) module. A thorough search of the relevant literature yielded that we are the first to model the seminal DeepLab model with a pure Transformer-based model. Extensive experiments on various medical image segmentation tasks verify that our approach performs superior or on par with most contemporary works on an amalgamation of Vision Transformer and CNN-based methods, along with a significant reduction of model complexity. The codes and trained models are publicly available at https://github.com/rezazad68/transdeeplab