 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDeepLab: Convolution-Free Transformer-based DeepLab v3+ for Medical Image Segmentation
Paper and Code
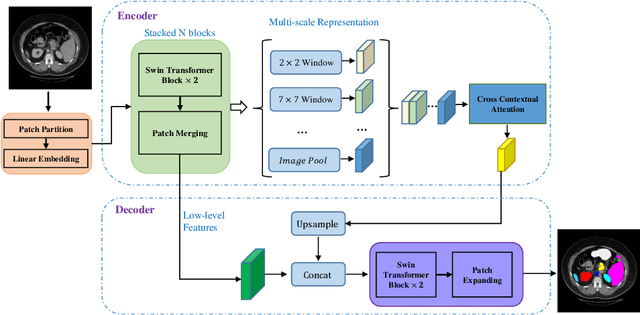
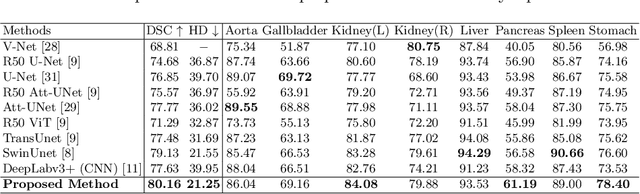
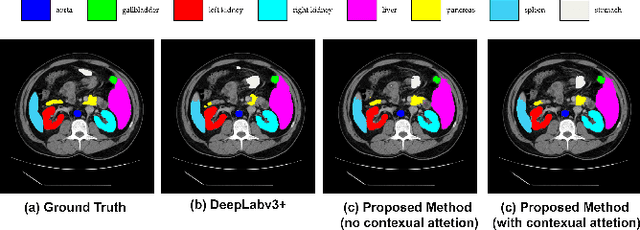
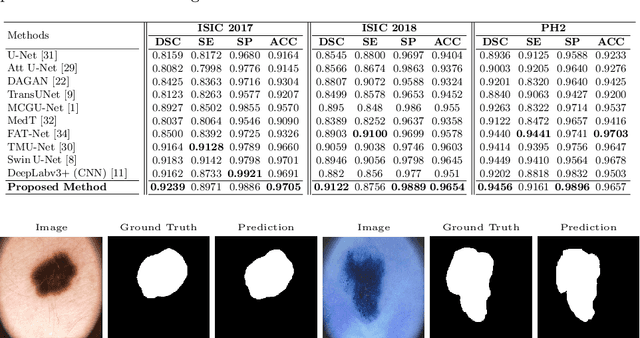
Convolutional neural networks (CNNs) have been the de facto standard in a diverse set of computer vision tasks for many years. Especially, deep neural networks based on seminal architectures such as U-shaped models with skip-connections or atrous convolution with pyramid pooling have been tailored to a wide range of medical image analysis tasks. The main advantage of such architectures is that they are prone to detaining versatile local features. However, as a general consensus, CNNs fail to capture long-range dependencies and spatial correlations due to the intrinsic property of confined receptive field size of convolution operations. Alternatively, Transformer, profiting from global information modelling that stems from the self-attention mechanism, has recently attained remarkable performance in natural language processing and computer vision. Nevertheless, previous studies prove that both local and global features are critical for a deep model in dense prediction, such as segmenting complicated structures with disparate shapes and configurations. To this end, this paper proposes TransDeepLab, a novel DeepLab-like pure Transformer for medical image segmentation. Specifically, we exploit hierarchical Swin-Transformer with shifted windows to extend the DeepLabv3 and model the Atrous Spatial Pyramid Pooling (ASPP) module. A thorough search of the relevant literature yielded that we are the first to model the seminal DeepLab model with a pure Transformer-based model. Extensive experiments on various medical image segmentation tasks verify that our approach performs superior or on par with most contemporary works on an amalgamation of Vision Transformer and CNN-based methods, along with a significant reduction of model complexity. The codes and trained models are publicly available at https://github.com/rezazad68/transdeeplab