 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInversion-Free Natural Gradient Descent on Riemannian Manifolds
Apr 03, 2026The natural gradient method is widely used in statistical optimization, but its standard formulation assumes a Euclidean parameter space. This paper proposes an inversion-free stochastic natural gradient method for probability distributions whose parameters lie on a Riemannian manifold. The manifold setting offers several advantages: one can implicitly enforce parameter constraints such as positive definiteness and orthogonality, ensure parameters are identifiable, or guarantee regularity properties of the objective like geodesic convexity. Building on an intrinsic formulation of the Fisher information matrix (FIM) on a manifold, our method maintains an online approximation of the inverse FIM, which is efficiently updated at quadratic cost using score vectors sampled at successive iterates. In the Riemannian setting, these score vectors belong to different tangent spaces and must be combined using transport operations. We prove almost-sure convergence rates of $O(\log{s}/s^α)$ for the squared distance to the minimizer when the step size exponent $α>2/3$. We also establish almost-sure rates for the approximate FIM, which now accumulates transport-based errors. A limited-memory variant of the algorithm with sub-quadratic storage complexity is proposed. Finally, we demonstrate the effectiveness of our method relative to its Euclidean counterparts on variational Bayes with Gaussian approximations and normalizing flows.
Bures-Wasserstein Importance-Weighted Evidence Lower Bound: Exposition and Applications
Feb 04, 2026The Importance-Weighted Evidence Lower Bound (IW-ELBO) has emerged as an effective objective for variational inference (VI), tightening the standard ELBO and mitigating the mode-seeking behaviour. However, optimizing the IW-ELBO in Euclidean space is often inefficient, as its gradient estimators suffer from a vanishing signal-to-noise ratio (SNR). This paper formulates the optimisation of the IW-ELBO in Bures-Wasserstein space, a manifold of Gaussian distributions equipped with the 2-Wasserstein metric. We derive the Wasserstein gradient of the IW-ELBO and project it onto the Bures-Wasserstein space to yield a tractable algorithm for Gaussian VI. A pivotal contribution of our analysis concerns the stability of the gradient estimator. While the SNR of the standard Euclidean gradient estimator is known to vanish as the number of importance samples $K$ increases, we prove that the SNR of the Wasserstein gradient scales favourably as $Ω(\sqrt{K})$, ensuring optimisation efficiency even for large $K$. We further extend this geometric analysis to the Variational Rényi Importance-Weighted Autoencoder bound, establishing analogous stability guarantees. Experiments demonstrate that the proposed framework achieves superior approximation performance compared to other baselines.
Importance Weighted Variational Inference without the Reparameterization Trick
Feb 01, 2026Importance weighted variational inference (VI) approximates densities known up to a normalizing constant by optimizing bounds that tighten with the number of Monte Carlo samples $N$. Standard optimization relies on reparameterized gradient estimators, which are well-studied theoretically yet restrict both the choice of the data-generating process and the variational approximation. While REINFORCE gradient estimators do not suffer from such restrictions, they lack rigorous theoretical justification. In this paper, we provide the first comprehensive analysis of REINFORCE gradient estimators in importance weighted VI, leveraging this theoretical foundation to diagnose and resolve fundamental deficiencies in current state-of-the-art estimators. Specifically, we introduce and examine a generalized family of variational inference for Monte Carlo objectives (VIMCO) gradient estimators. We prove that state-of-the-art VIMCO gradient estimators exhibit a vanishing signal-to-noise ratio (SNR) as $N$ increases, which prevents effective optimization. To overcome this issue, we propose the novel VIMCO-$\star$ gradient estimator and show that it averts the SNR collapse of existing VIMCO gradient estimators by achieving a $\sqrt{N}$ SNR scaling instead. We demonstrate its superior empirical performance compared to current VIMCO implementations in challenging settings where reparameterized gradients are typically unavailable.
Loss-based Bayesian Sequential Prediction of Value at Risk with a Long-Memory and Non-linear Realized Volatility Model
Aug 24, 2024



A long memory and non-linear realized volatility model class is proposed for direct Value at Risk (VaR) forecasting. This model, referred to as RNN-HAR, extends the heterogeneous autoregressive (HAR) model, a framework known for efficiently capturing long memory in realized measures, by integrating a Recurrent Neural Network (RNN) to handle non-linear dynamics. Loss-based generalized Bayesian inference with Sequential Monte Carlo is employed for model estimation and sequential prediction in RNN HAR. The empirical analysis is conducted using daily closing prices and realized measures from 2000 to 2022 across 31 market indices. The proposed models one step ahead VaR forecasting performance is compared against a basic HAR model and its extensions. The results demonstrate that the proposed RNN-HAR model consistently outperforms all other models considered in the study.
DeepVol: A Deep Transfer Learning Approach for Universal Asset Volatility Modeling
Sep 05, 2023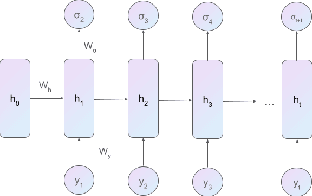
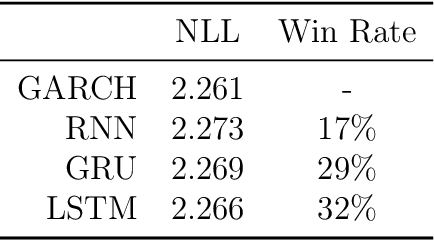
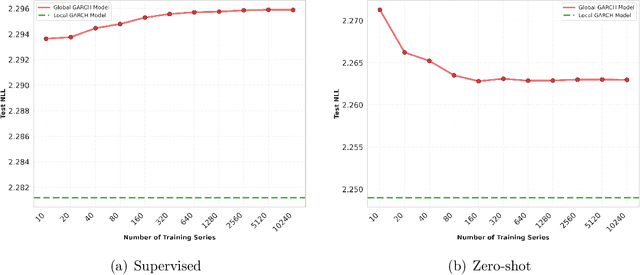
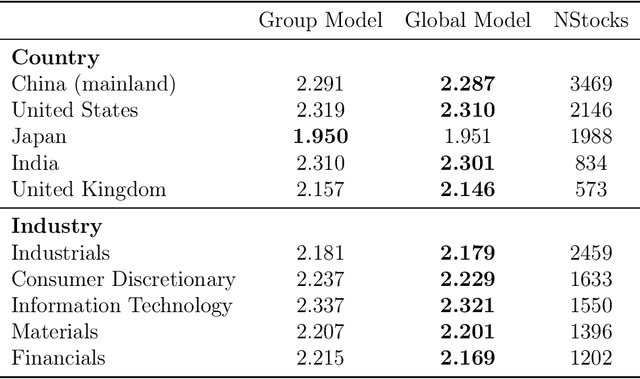
This paper introduces DeepVol, a promising new deep learning volatility model that outperforms traditional econometric models in terms of model generality. DeepVol leverages the power of transfer learning to effectively capture and model the volatility dynamics of all financial assets, including previously unseen ones, using a single universal model. This contrasts to the prevailing practice in econometrics literature, which necessitates training separate models for individual datasets. The introduction of DeepVol opens up new avenues for volatility modeling and forecasting in the finance industry, potentially transforming the way volatility is understood and predicted.
Wasserstein Gaussianization and Efficient Variational Bayes for Robust Bayesian Synthetic Likelihood
May 24, 2023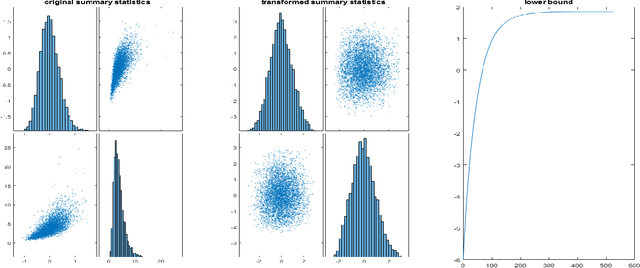


The Bayesian Synthetic Likelihood (BSL) method is a widely-used tool for likelihood-free Bayesian inference. This method assumes that some summary statistics are normally distributed, which can be incorrect in many applications. We propose a transformation, called the Wasserstein Gaussianization transformation, that uses a Wasserstein gradient flow to approximately transform the distribution of the summary statistics into a Gaussian distribution. BSL also implicitly requires compatibility between simulated summary statistics under the working model and the observed summary statistics. A robust BSL variant which achieves this has been developed in the recent literature. We combine the Wasserstein Gaussianization transformation with robust BSL, and an efficient Variational Bayes procedure for posterior approximation, to develop a highly efficient and reliable approximate Bayesian inference method for likelihood-free problems.
Particle Mean Field Variational Bayes
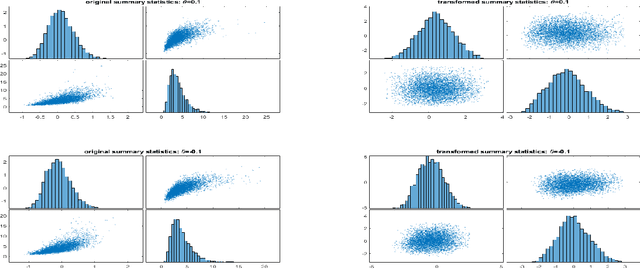
Mar 24, 2023
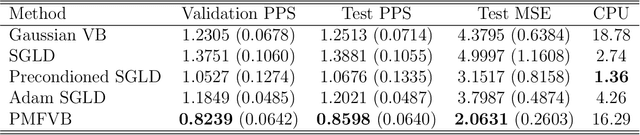
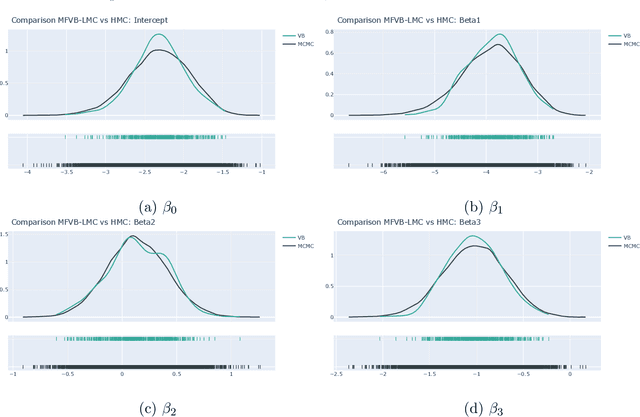
The Mean Field Variational Bayes (MFVB) method is one of the most computationally efficient techniques for Bayesian inference. However, its use has been restricted to models with conjugate priors or those that require analytical calculations. This paper proposes a novel particle-based MFVB approach that greatly expands the applicability of the MFVB method. We establish the theoretical basis of the new method by leveraging the connection between Wasserstein gradient flows and Langevin diffusion dynamics, and demonstrate the effectiveness of this approach using Bayesian logistic regression, stochastic volatility, and deep neural networks.
Realized recurrent conditional heteroskedasticity model for volatility modelling
Feb 16, 2023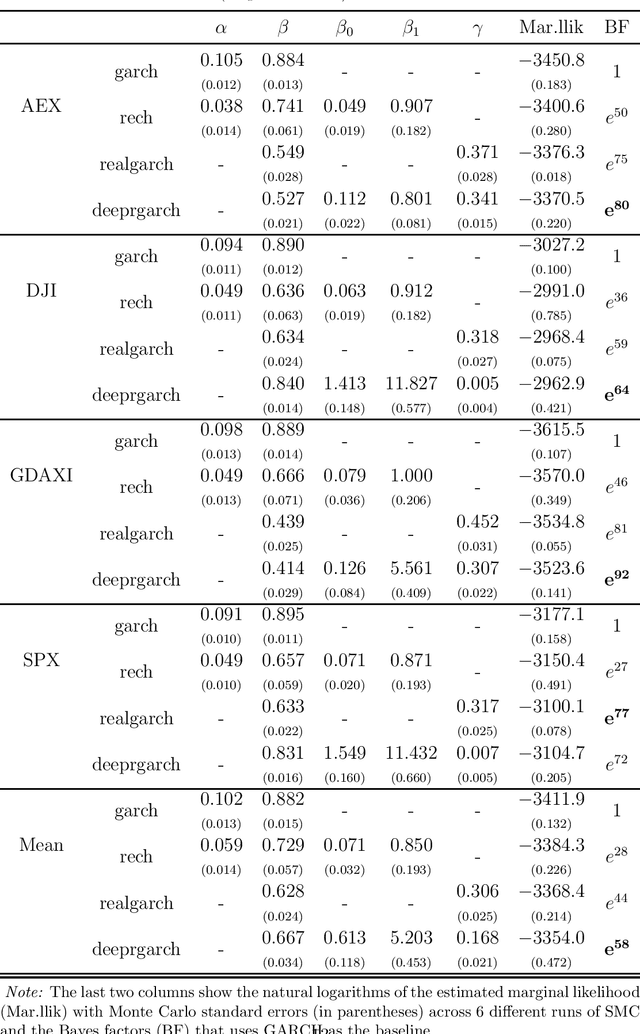
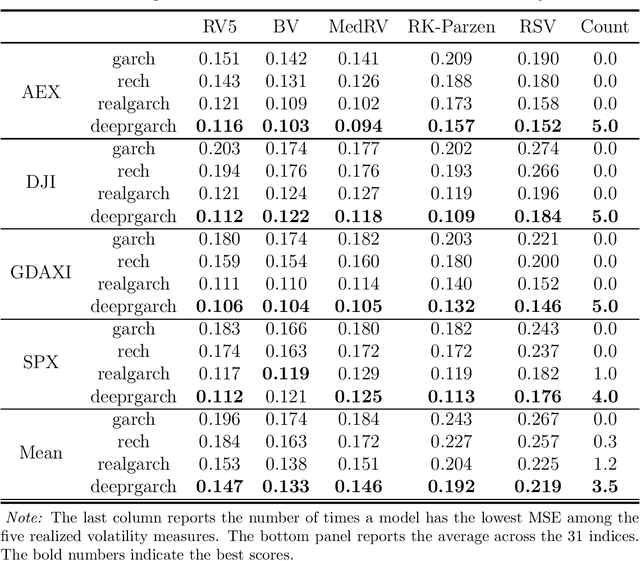
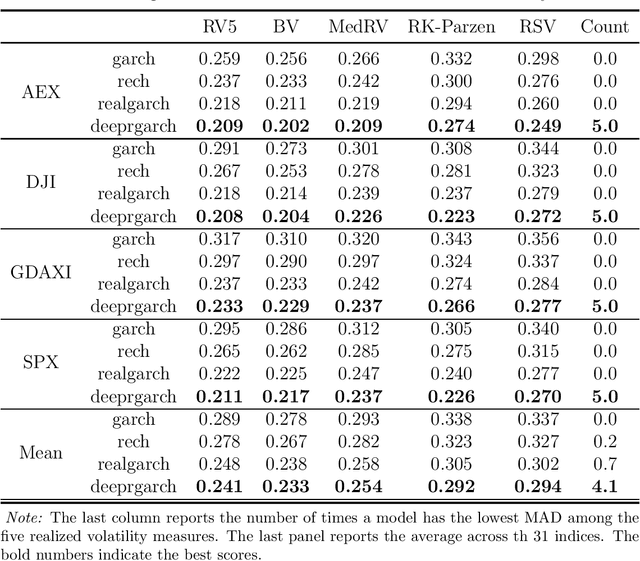
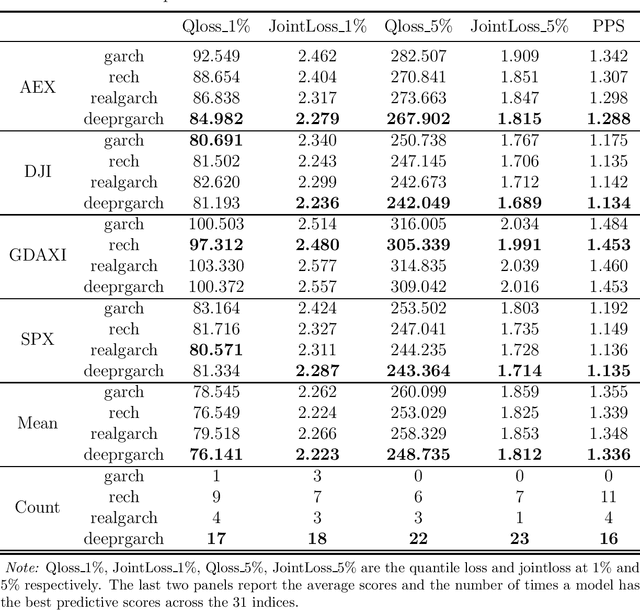
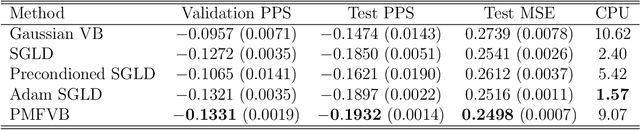
We propose a new approach to volatility modelling by combining deep learning (LSTM) and realized volatility measures. This LSTM-enhanced realized GARCH framework incorporates and distills modeling advances from financial econometrics, high frequency trading data and deep learning. Bayesian inference via the Sequential Monte Carlo method is employed for statistical inference and forecasting. The new framework can jointly model the returns and realized volatility measures, has an excellent in-sample fit and superior predictive performance compared to several benchmark models, while being able to adapt well to the stylized facts in volatility. The performance of the new framework is tested using a wide range of metrics, from marginal likelihood, volatility forecasting, to tail risk forecasting and option pricing. We report on a comprehensive empirical study using 31 widely traded stock indices over a time period that includes COVID-19 pandemic.
An Introduction to Quantum Computing for Statisticians
Dec 13, 2021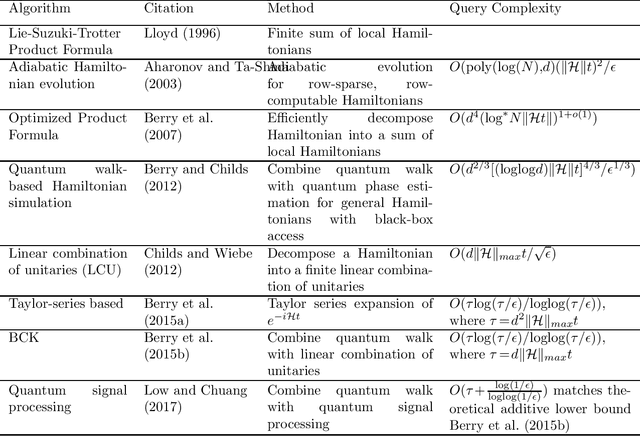
Quantum computing has the potential to revolutionise and change the way we live and understand the world. This review aims to provide an accessible introduction to quantum computing with a focus on applications in statistics and data analysis. We start with an introduction to the basic concepts necessary to understand quantum computing and the differences between quantum and classical computing. We describe the core quantum subroutines that serve as the building blocks of quantum algorithms. We then review a range of quantum algorithms expected to deliver a computational advantage in statistics and machine learning. We highlight the challenges and opportunities in applying quantum computing to problems in statistics and discuss potential future research directions.
Quantum Natural Gradient for Variational Bayes
Jul 08, 2021
Variational Bayes (VB) is a critical method in machine learning and statistics, underpinning the recent success of Bayesian deep learning. The natural gradient is an essential component of efficient VB estimation, but it is prohibitively computationally expensive in high dimensions. We propose a hybrid quantum-classical algorithm to improve the scaling properties of natural gradient computation and make VB a truly computationally efficient method for Bayesian inference in highdimensional settings. The algorithm leverages matrix inversion from the linear systems algorithm by Harrow, Hassidim, and Lloyd [Phys. Rev. Lett. 103, 15 (2009)] (HHL). We demonstrate that the matrix to be inverted is sparse and the classical-quantum-classical handoffs are sufficiently economical to preserve computational efficiency, making the problem of natural gradient for VB an ideal application of HHL. We prove that, under standard conditions, the VB algorithm with quantum natural gradient is guaranteed to converge. Our regression-based natural gradient formulation is also highly useful for classical VB.