 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability-Aware Early-Stage Research Idea Evaluation
Jan 18, 2026Predicting the outcomes of research ideas at their conceptual stage (i.e. before significant resources are committed) holds great potential for optimizing scientific resource allocation and research planning. While existing methods rely heavily on finished manuscripts or peer reviews, we propose a novel capability-aware framework that predicts paper acceptance and ratings using only author information and research ideas, without requiring full text or experimental results. Our approach integrates author information, (inferred) capability presentation, and research ideas through a three-way transformer architecture with flexible fusion mechanisms. We also introduce a two-stage architecture for learning the capability representation given the author information and idea. Experiments show that our method significantly outperform the single-way models by finetuning bert-base and bert-large, and the capability predicting significantly increase the predictive accuracy of the final model. The proposed method can be applied in both early-stage research outcome prediction and scientific resource allocation.
Unsupervised Extractive Summarization with Learnable Length Control Strategies
Dec 18, 2023
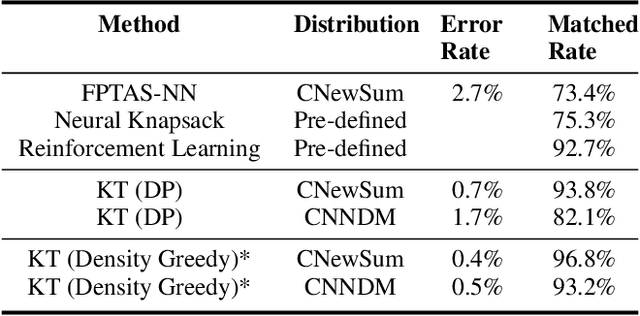

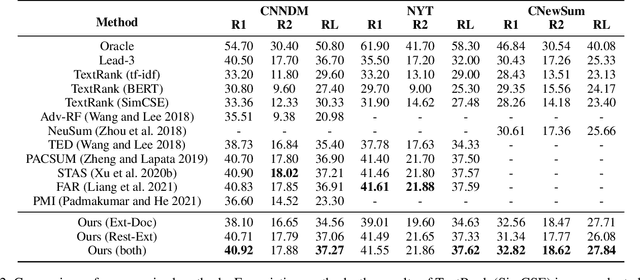
Unsupervised extractive summarization is an important technique in information extraction and retrieval. Compared with supervised method, it does not require high-quality human-labelled summaries for training and thus can be easily applied for documents with different types, domains or languages. Most of existing unsupervised methods including TextRank and PACSUM rely on graph-based ranking on sentence centrality. However, this scorer can not be directly applied in end-to-end training, and the positional-related prior assumption is often needed for achieving good summaries. In addition, less attention is paid to length-controllable extractor, where users can decide to summarize texts under particular length constraint. This paper introduces an unsupervised extractive summarization model based on a siamese network, for which we develop a trainable bidirectional prediction objective between the selected summary and the original document. Different from the centrality-based ranking methods, our extractive scorer can be trained in an end-to-end manner, with no other requirement of positional assumption. In addition, we introduce a differentiable length control module by approximating 0-1 knapsack solver for end-to-end length-controllable extracting. Experiments show that our unsupervised method largely outperforms the centrality-based baseline using a same sentence encoder. In terms of length control ability, via our trainable knapsack module, the performance consistently outperforms the strong baseline without utilizing end-to-end training. Human evaluation further evidences that our method performs the best among baselines in terms of relevance and consistency.
Prompt-Based Length Controlled Generation with Reinforcement Learning
Aug 23, 2023Recently, large language models (LLMs) like ChatGPT and GPT-4 have attracted great attention given their surprising improvement and performance. Length controlled generation of LLMs emerges as an important topic, which also enables users to fully leverage the capability of LLMs in more real-world scenarios like generating a proper answer or essay of a desired length. In addition, the autoregressive generation in LLMs is extremely time-consuming, while the ability of controlling this generated length can arbitrarily reduce the inference cost by limiting the length, and thus satisfy different needs. Therefore, we aim to propose a prompt-based length control method to achieve this length controlled generation, which can also be widely applied in GPT-style LLMs. In particular, we adopt reinforcement learning with the reward signal given by either trainable or rule-based reward model, which further affects the generation of LLMs via rewarding a pre-defined target length. Experiments show that our method significantly improves the accuracy of prompt-based length control for summarization task on popular datasets like CNNDM and NYT. We believe this length-controllable ability can provide more potentials towards the era of LLMs.
Enhancing Coherence of Extractive Summarization with Multitask Learning
May 22, 2023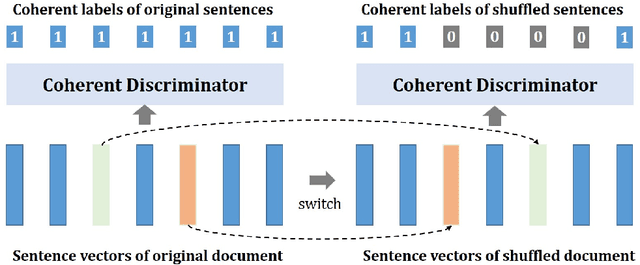

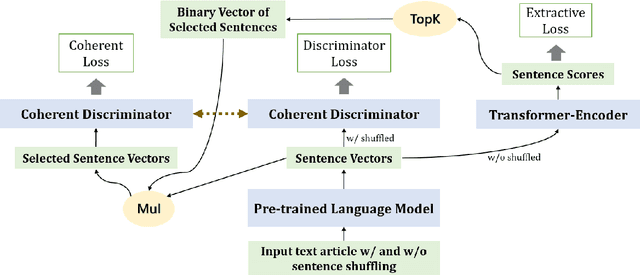
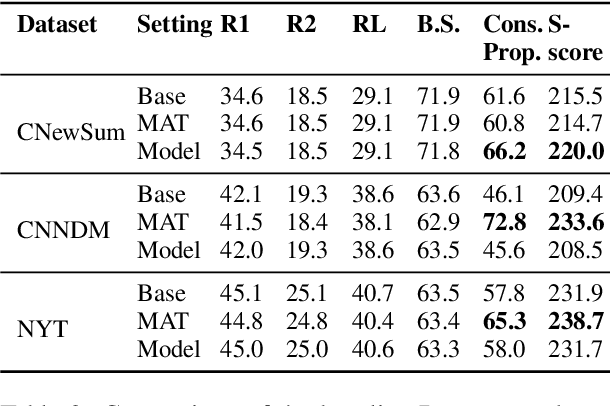
This study proposes a multitask learning architecture for extractive summarization with coherence boosting. The architecture contains an extractive summarizer and coherent discriminator module. The coherent discriminator is trained online on the sentence vectors of the augmented textual input, thus improving its general ability of judging whether the input sentences are coherent. Meanwhile, we maximize the coherent scores from the coherent discriminator by updating the parameters of the summarizer. To make the extractive sentences trainable in a differentiable manner, we introduce two strategies, including pre-trained converting model (model-based) and converting matrix (MAT-based) that merge sentence representations. Experiments show that our proposed method significantly improves the proportion of consecutive sentences in the extracted summaries based on their positions in the original article (i.e., automatic sentence-level coherence metric), while the goodness in terms of other automatic metrics (i.e., Rouge scores and BertScores) are preserved. Human evaluation also evidences the improvement of coherence and consistency of the extracted summaries given by our method.
Differentiable Neural Architecture Search with Morphism-based Transformable Backbone Architectures
Jun 14, 2021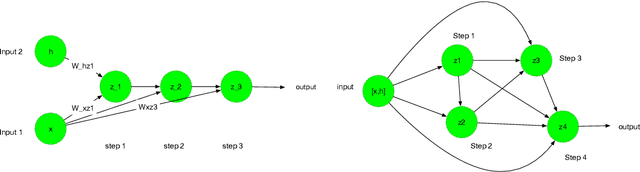



This study aims at making the architecture search process more adaptive for one-shot or online training. It is extended from the existing study on differentiable neural architecture search, and we made the backbone architecture transformable rather than fixed during the training process. As is known, differentiable neural architecture search (DARTS) requires a pre-defined over-parameterized backbone architecture, while its size is to be determined manually. Also, in DARTS backbone, Hadamard product of two elements is not introduced, which exists in both LSTM and GRU cells for recurrent nets. This study introduces a growing mechanism for differentiable neural architecture search based on network morphism. It enables growing of the cell structures from small size towards large size ones with one-shot training. Two modes can be applied in integrating the growing and original pruning process. We also implement a recently proposed two-input backbone architecture for recurrent neural networks. Initial experimental results indicate that our approach and the two-input backbone structure can be quite effective compared with other baseline architectures including LSTM, in a variety of learning tasks including multi-variate time series forecasting and language modeling. On the other hand, we find that dynamic network transformation is promising in improving the efficiency of differentiable architecture search.
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Aug 19, 2020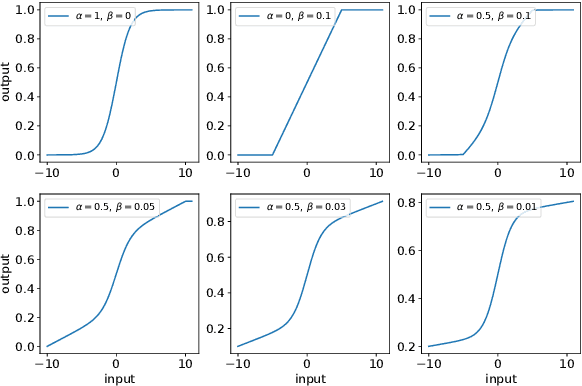
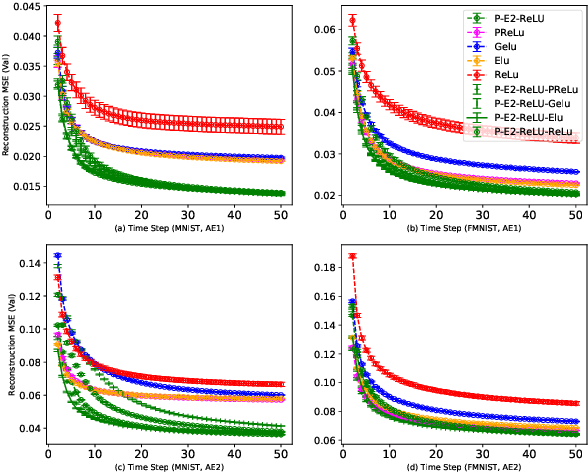
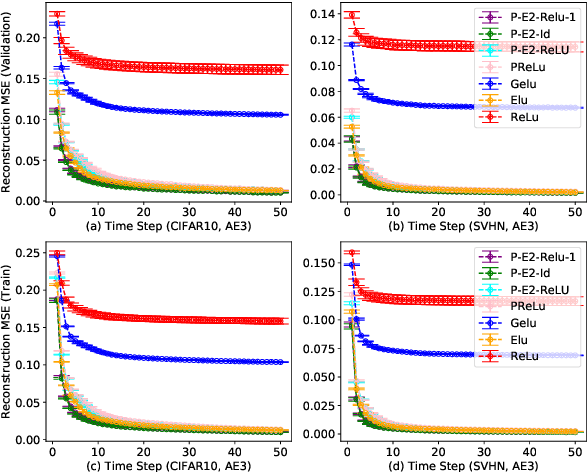
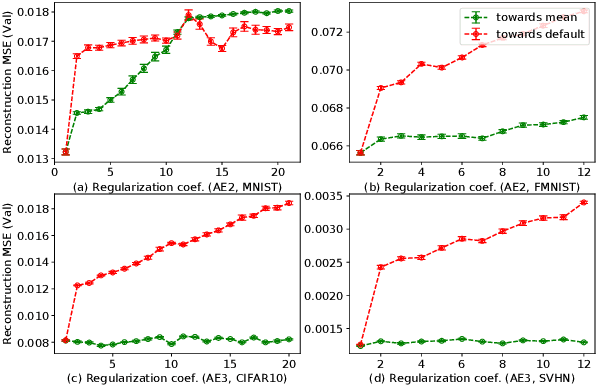
Activation in deep neural networks is fundamental to achieving non-linear mappings. Traditional studies mainly focus on finding fixed activations for a particular set of learning tasks or model architectures. The research on flexible activation is quite limited in both designing philosophy and application scenarios. In this study, three principles of choosing flexible activation components are proposed and a general combined form of flexible activation functions is implemented. Based on this, a novel family of flexible activation functions that can replace sigmoid or tanh in LSTM cells are implemented, as well as a new family by combining ReLU and ELUs. Also, two new regularisation terms based on assumptions as prior knowledge are introduced. It has been shown that LSTM models with proposed flexible activations P-Sig-Ramp provide significant improvements in time series forecasting, while the proposed P-E2-ReLU achieves better and more stable performance on lossy image compression tasks with convolutional auto-encoders. In addition, the proposed regularization terms improve the convergence, performance and stability of the models with flexible activation functions.
Adaptive Multi-level Hyper-gradient Descent
Aug 19, 2020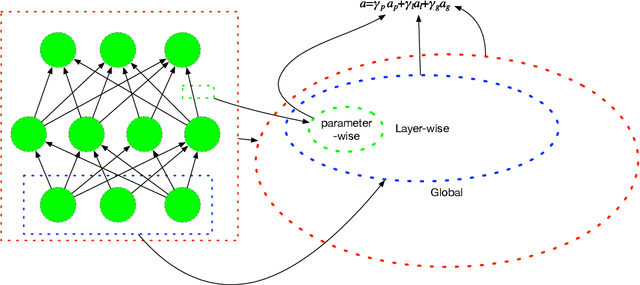
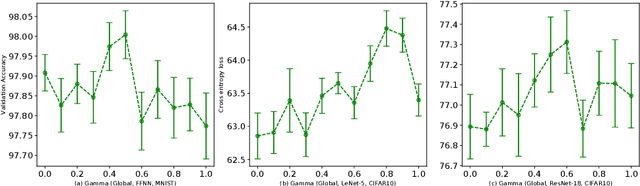
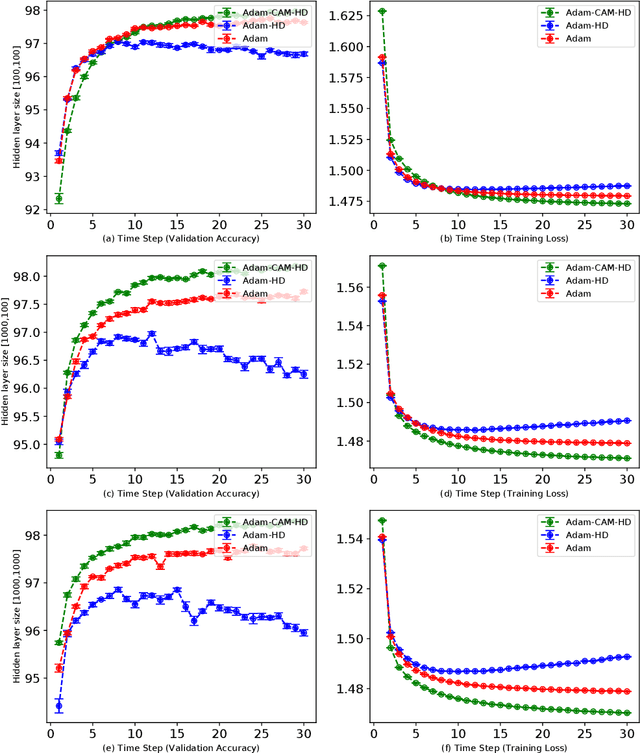
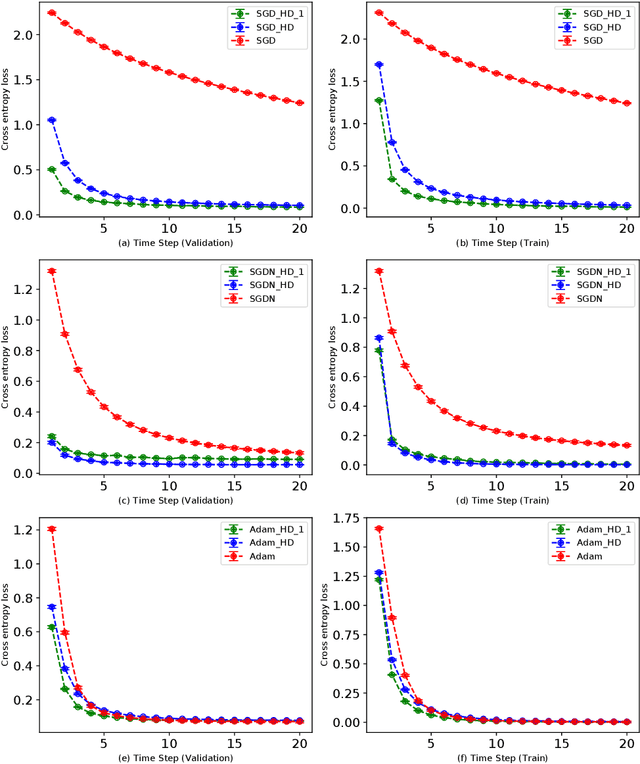
Adaptive learning rates can lead to faster convergence and better final performance for deep learning models. There are several widely known human-designed adaptive optimizers such as Adam and RMSProp, gradient based adaptive methods such as hyper-descent and L4, and meta learning approaches including learning to learn. However, the issue of balancing adaptiveness and over-parameterization is still a topic to be addressed. In this study, we investigate different levels of learning rate adaptation based on the framework of hyper-gradient descent, and further propose a method that adaptively learns the model parameters for combining different levels of adaptations. Meanwhile, we show the relationship between adding regularization on over-parameterized learning rates and building combinations of different levels of adaptive learning rates. The experiments on several network architectures including feed-forward networks, LeNet-5 and ResNet-34 show that the proposed multi-level adaptive approach can outperform baseline adaptive methods in a variety circumstances with statistical significance.