 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Extractive Summarization with Learnable Length Control Strategies
Paper and Code
Dec 18, 2023
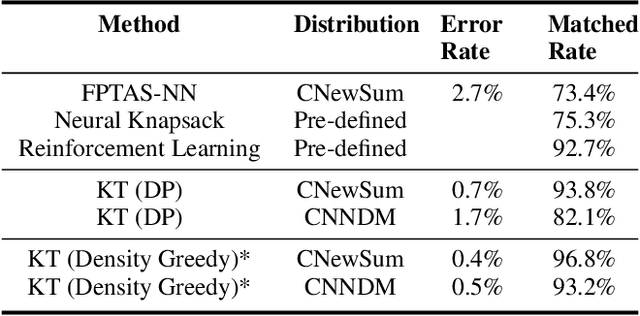

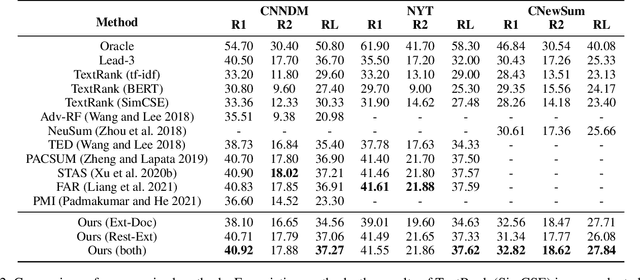
Unsupervised extractive summarization is an important technique in information extraction and retrieval. Compared with supervised method, it does not require high-quality human-labelled summaries for training and thus can be easily applied for documents with different types, domains or languages. Most of existing unsupervised methods including TextRank and PACSUM rely on graph-based ranking on sentence centrality. However, this scorer can not be directly applied in end-to-end training, and the positional-related prior assumption is often needed for achieving good summaries. In addition, less attention is paid to length-controllable extractor, where users can decide to summarize texts under particular length constraint. This paper introduces an unsupervised extractive summarization model based on a siamese network, for which we develop a trainable bidirectional prediction objective between the selected summary and the original document. Different from the centrality-based ranking methods, our extractive scorer can be trained in an end-to-end manner, with no other requirement of positional assumption. In addition, we introduce a differentiable length control module by approximating 0-1 knapsack solver for end-to-end length-controllable extracting. Experiments show that our unsupervised method largely outperforms the centrality-based baseline using a same sentence encoder. In terms of length control ability, via our trainable knapsack module, the performance consistently outperforms the strong baseline without utilizing end-to-end training. Human evaluation further evidences that our method performs the best among baselines in terms of relevance and consistency.