 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Neural Architecture Search with Morphism-based Transformable Backbone Architectures
Paper and Code
Jun 14, 2021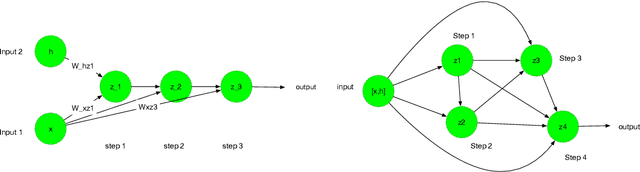



This study aims at making the architecture search process more adaptive for one-shot or online training. It is extended from the existing study on differentiable neural architecture search, and we made the backbone architecture transformable rather than fixed during the training process. As is known, differentiable neural architecture search (DARTS) requires a pre-defined over-parameterized backbone architecture, while its size is to be determined manually. Also, in DARTS backbone, Hadamard product of two elements is not introduced, which exists in both LSTM and GRU cells for recurrent nets. This study introduces a growing mechanism for differentiable neural architecture search based on network morphism. It enables growing of the cell structures from small size towards large size ones with one-shot training. Two modes can be applied in integrating the growing and original pruning process. We also implement a recently proposed two-input backbone architecture for recurrent neural networks. Initial experimental results indicate that our approach and the two-input backbone structure can be quite effective compared with other baseline architectures including LSTM, in a variety of learning tasks including multi-variate time series forecasting and language modeling. On the other hand, we find that dynamic network transformation is promising in improving the efficiency of differentiable architecture search.