 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Choral Music Separation through Expressive Synthesized Data from Sampled Instruments
Sep 07, 2022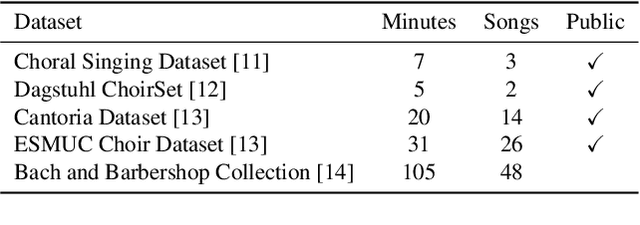
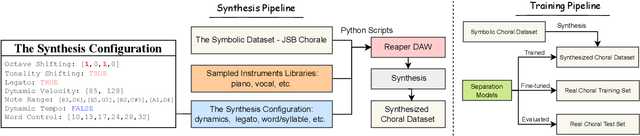

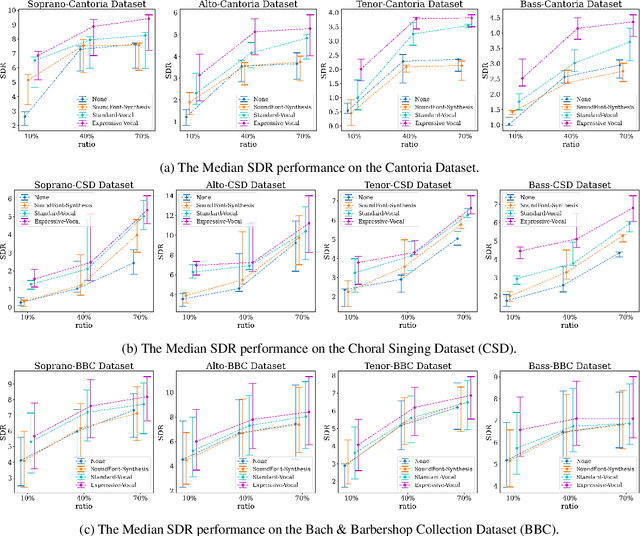
Choral music separation refers to the task of extracting tracks of voice parts (e.g., soprano, alto, tenor, and bass) from mixed audio. The lack of datasets has impeded research on this topic as previous work has only been able to train and evaluate models on a few minutes of choral music data due to copyright issues and dataset collection difficulties. In this paper, we investigate the use of synthesized training data for the source separation task on real choral music. We make three contributions: first, we provide an automated pipeline for synthesizing choral music data from sampled instrument plugins within controllable options for instrument expressiveness. This produces an 8.2-hour-long choral music dataset from the JSB Chorales Dataset and one can easily synthesize additional data. Second, we conduct an experiment to evaluate multiple separation models on available choral music separation datasets from previous work. To the best of our knowledge, this is the first experiment to comprehensively evaluate choral music separation. Third, experiments demonstrate that the synthesized choral data is of sufficient quality to improve the model's performance on real choral music datasets. This provides additional experimental statistics and data support for the choral music separation study.
* Camera Ready for Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022
Expediting TTS Synthesis with Adversarial Vocoding
Apr 16, 2019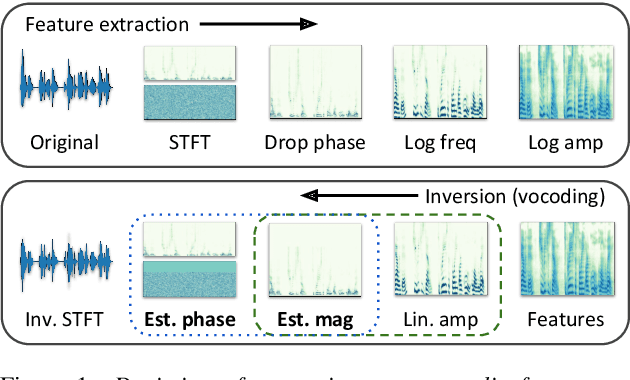

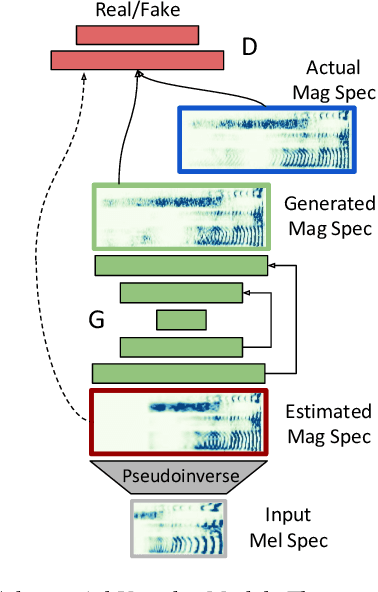
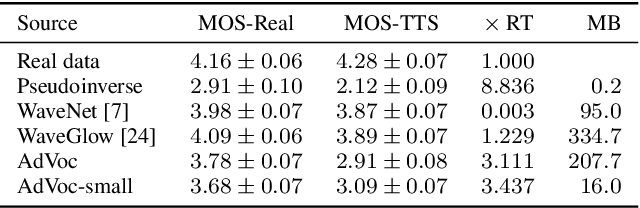
Recent approaches in text-to-speech (TTS) synthesis employ neural network strategies to vocode perceptually-informed spectrogram representations directly into listenable waveforms. Such vocoding procedures create a computational bottleneck in modern TTS pipelines. We propose an alternative approach which utilizes generative adversarial networks (GANs) to learn mappings from perceptually-informed spectrograms to simple magnitude spectrograms which can be heuristically vocoded. Through a user study, we show that our approach significantly outperforms na\"ive vocoding strategies while being hundreds of times faster than neural network vocoders used in state-of-the-art TTS systems. We also show that our method can be used to achieve state-of-the-art results in unsupervised synthesis of individual words of speech.
Adversarial Audio Synthesis
Sep 27, 2018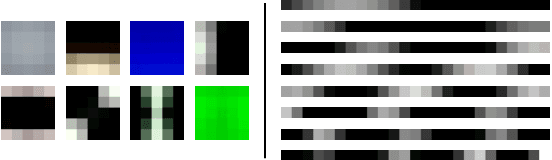
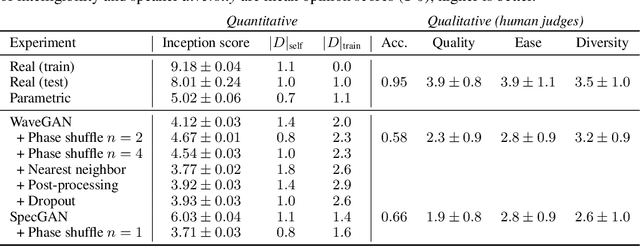


While Generative Adversarial Networks (GANs) have seen wide success at the problem of synthesizing realistic images, they have seen little application to audio generation. Unlike for images, a barrier to success is that the best discriminative representations for audio tend to be non-invertible, and thus cannot be used to synthesize listenable outputs. In this paper we introduce WaveGAN, a first attempt at applying GANs to unsupervised synthesis of raw-waveform audio. Our experiments demonstrate that WaveGAN can produce intelligible words from a small vocabulary of speech, and can also synthesize audio from other domains such as drums, bird vocalizations, and piano. Qualitatively, we find that human judges prefer the sound quality of generated examples from WaveGAN over those from a method which na\"ively apply GANs on image-like audio feature representations.