 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpediting TTS Synthesis with Adversarial Vocoding
Paper and Code
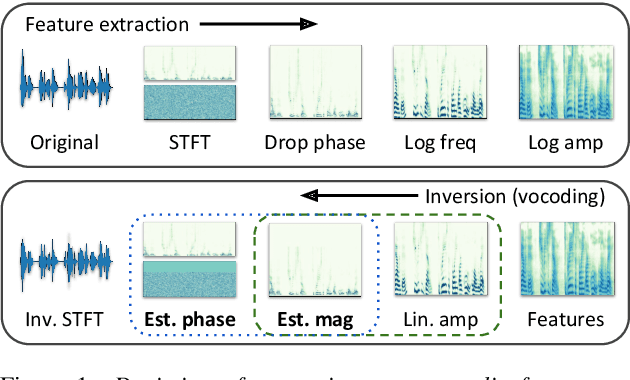

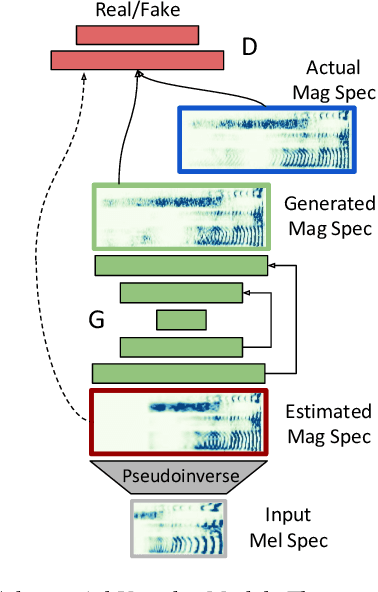
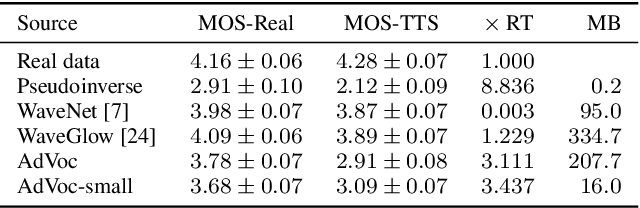
Recent approaches in text-to-speech (TTS) synthesis employ neural network strategies to vocode perceptually-informed spectrogram representations directly into listenable waveforms. Such vocoding procedures create a computational bottleneck in modern TTS pipelines. We propose an alternative approach which utilizes generative adversarial networks (GANs) to learn mappings from perceptually-informed spectrograms to simple magnitude spectrograms which can be heuristically vocoded. Through a user study, we show that our approach significantly outperforms na\"ive vocoding strategies while being hundreds of times faster than neural network vocoders used in state-of-the-art TTS systems. We also show that our method can be used to achieve state-of-the-art results in unsupervised synthesis of individual words of speech.