 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Feasible Vehicle Trajectory Prediction
Apr 29, 2021
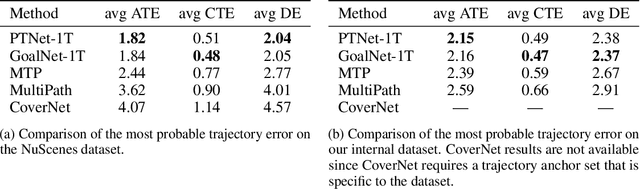
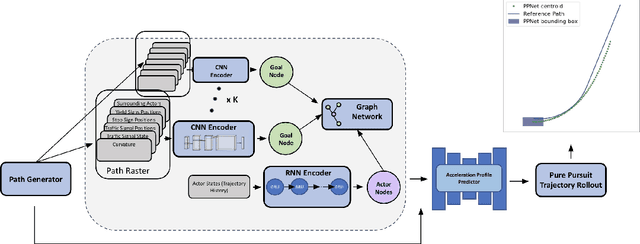
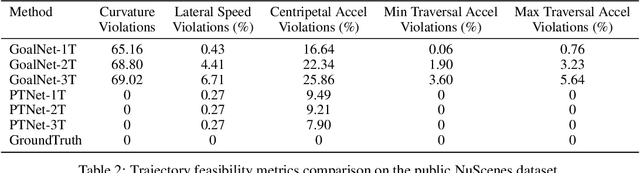
Predicting the future motion of actors in a traffic scene is a crucial part of any autonomous driving system. Recent research in this area has focused on trajectory prediction approaches that optimize standard trajectory error metrics. In this work, we describe three important properties -- physical realism guarantees, system maintainability, and sample efficiency -- which we believe are equally important for developing a self-driving system that can operate safely and practically in the real world. Furthermore, we introduce PTNet (PathTrackingNet), a novel approach for vehicle trajectory prediction that is a hybrid of the classical pure pursuit path tracking algorithm and modern graph-based neural networks. By combining a structured robotics technique with a flexible learning approach, we are able to produce a system that not only achieves the same level of performance as other state-of-the-art methods on traditional trajectory error metrics, but also provides strong guarantees about the physical realism of the predicted trajectories while requiring half the amount of data. We believe focusing on this new class of hybrid approaches is an useful direction for developing and maintaining a safety-critical autonomous driving system.
Interaction-Based Trajectory Prediction Over a Hybrid Traffic Graph
Sep 27, 2020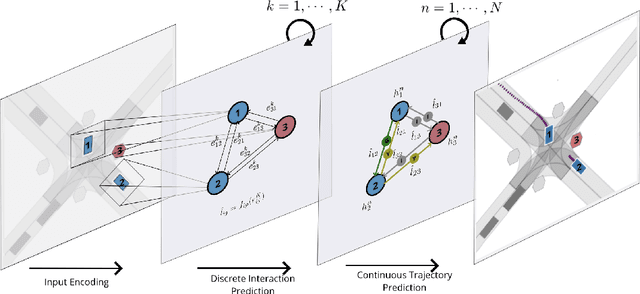
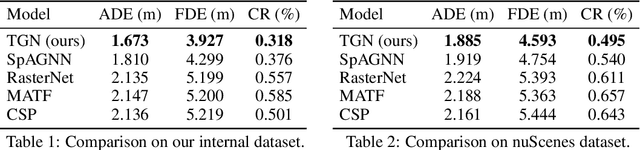
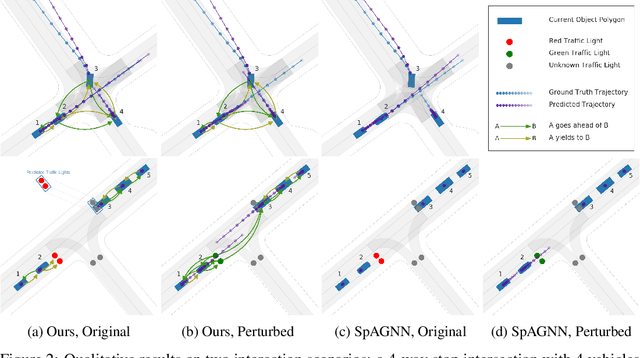

Behavior prediction of traffic actors is an essential component of any real-world self-driving system. Actors' long-term behaviors tend to be governed by their interactions with other actors or traffic elements (traffic lights, stop signs) in the scene. To capture this highly complex structure of interactions, we propose to use a hybrid graph whose nodes represent both the traffic actors as well as the static and dynamic traffic elements present in the scene. The different modes of temporal interaction (e.g., stopping and going) among actors and traffic elements are explicitly modeled by graph edges. This explicit reasoning about discrete interaction types not only helps in predicting future motion, but also enhances the interpretability of the model, which is important for safety-critical applications such as autonomous driving. We predict actors' trajectories and interaction types using a graph neural network, which is trained in a semi-supervised manner. We show that our proposed model, TrafficGraphNet, achieves state-of-the-art trajectory prediction accuracy while maintaining a high level of interpretability.
Map-Adaptive Goal-Based Trajectory Prediction
Sep 09, 2020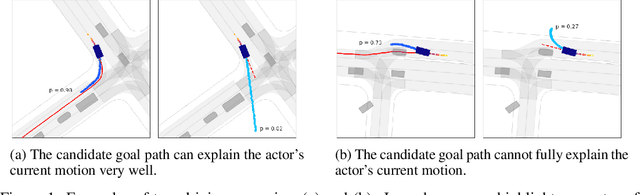

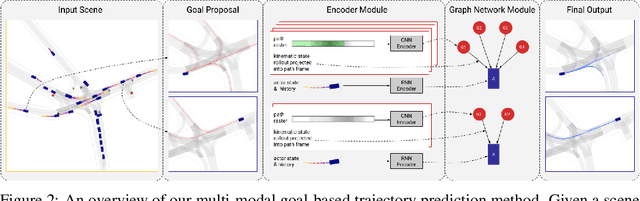
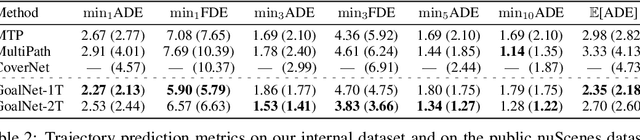
We present a new method for multi-modal, long-term vehicle trajectory prediction. Our approach relies on using lane centerlines captured in rich maps of the environment to generate a set of proposed goal paths for each vehicle. Using these paths -- which are generated at run time and therefore dynamically adapt to the scene -- as spatial anchors, we predict a set of goal-based trajectories along with a categorical distribution over the goals. This approach allows us to directly model the goal-directed behavior of traffic actors, which unlocks the potential for more accurate long-term prediction. Our experimental results on both a large-scale internal driving dataset and on the public nuScenes dataset show that our model outperforms state-of-the-art approaches for vehicle trajectory prediction over a 6-second horizon. We also empirically demonstrate that our model is better able to generalize to road scenes from a completely new city than existing methods.
Goal-Directed Occupancy Prediction for Lane-Following Actors
Sep 06, 2020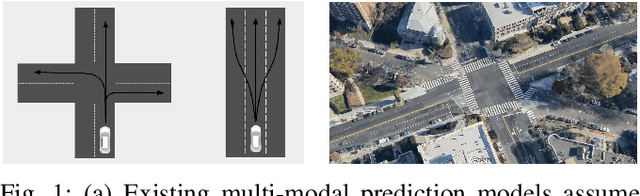
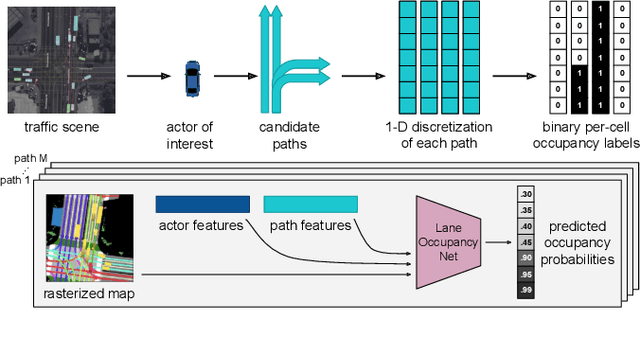

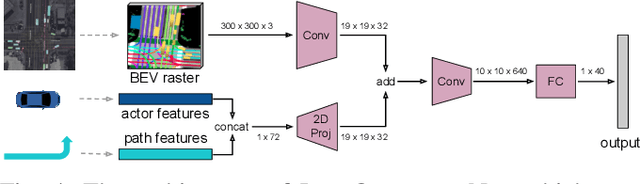
Predicting the possible future behaviors of vehicles that drive on shared roads is a crucial task for safe autonomous driving. Many existing approaches to this problem strive to distill all possible vehicle behaviors into a simplified set of high-level actions. However, these action categories do not suffice to describe the full range of maneuvers possible in the complex road networks we encounter in the real world. To combat this deficiency, we propose a new method that leverages the mapped road topology to reason over possible goals and predict the future spatial occupancy of dynamic road actors. We show that our approach is able to accurately predict future occupancy that remains consistent with the mapped lane geometry and naturally captures multi-modality based on the local scene context while also not suffering from the mode collapse problem observed in prior work.
Joint Interaction and Trajectory Prediction for Autonomous Driving using Graph Neural Networks
Dec 17, 2019
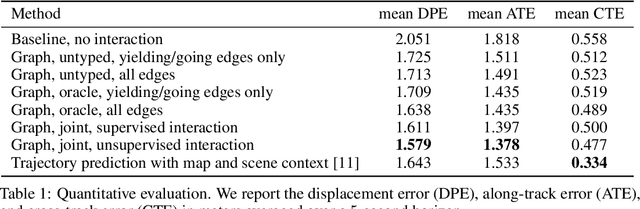
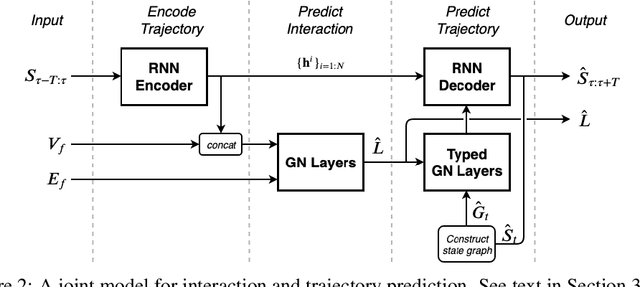
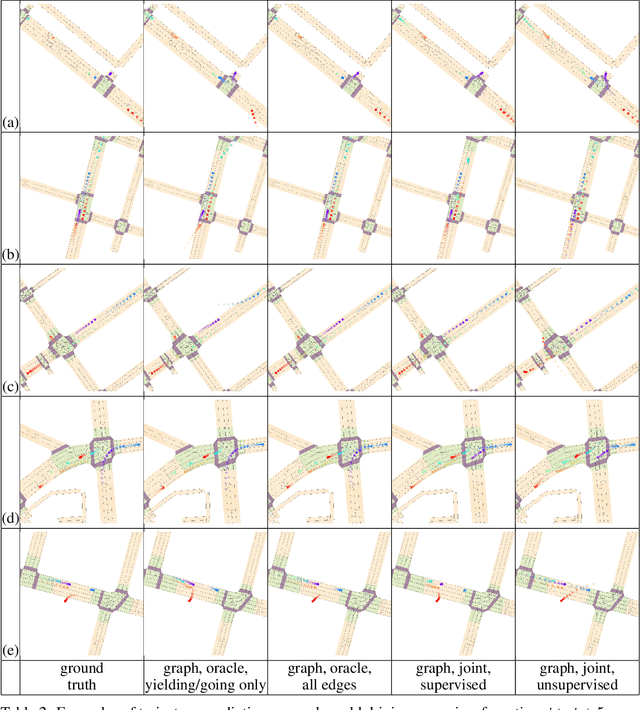
In this work, we aim to predict the future motion of vehicles in a traffic scene by explicitly modeling their pairwise interactions. Specifically, we propose a graph neural network that jointly predicts the discrete interaction modes and 5-second future trajectories for all agents in the scene. Our model infers an interaction graph whose nodes are agents and whose edges capture the long-term interaction intents among the agents. In order to train the model to recognize known modes of interaction, we introduce an auto-labeling function to generate ground truth interaction labels. Using a large-scale real-world driving dataset, we demonstrate that jointly predicting the trajectories along with the explicit interaction types leads to significantly lower trajectory error than baseline methods. Finally, we show through simulation studies that the learned interaction modes are semantically meaningful.
Hybrid Subspace Learning for High-Dimensional Data
Aug 05, 2018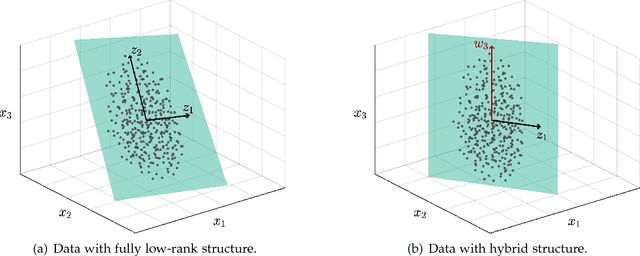
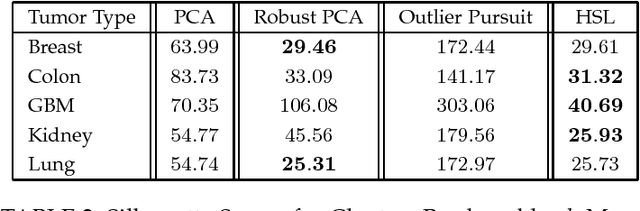
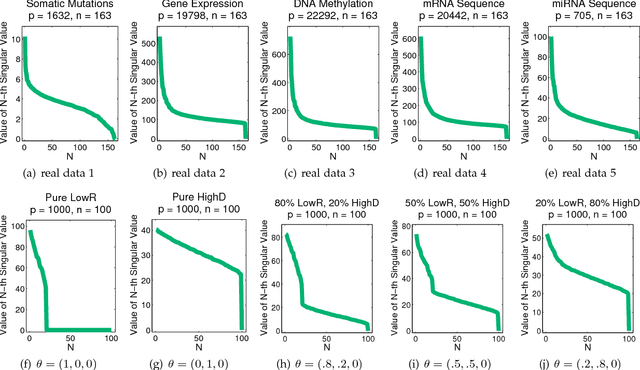
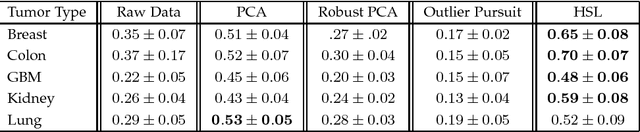
The high-dimensional data setting, in which p >> n, is a challenging statistical paradigm that appears in many real-world problems. In this setting, learning a compact, low-dimensional representation of the data can substantially help distinguish signal from noise. One way to achieve this goal is to perform subspace learning to estimate a small set of latent features that capture the majority of the variance in the original data. Most existing subspace learning models, such as PCA, assume that the data can be fully represented by its embedding in one or more latent subspaces. However, in this work, we argue that this assumption is not suitable for many high-dimensional datasets; often only some variables can easily be projected to a low-dimensional space. We propose a hybrid dimensionality reduction technique in which some features are mapped to a low-dimensional subspace while others remain in the original space. Our model leads to more accurate estimation of the latent space and lower reconstruction error. We present a simple optimization procedure for the resulting biconvex problem and show synthetic data results that demonstrate the advantages of our approach over existing methods. Finally, we demonstrate the effectiveness of this method for extracting meaningful features from both gene expression and video background subtraction datasets.