 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Interaction-Based Trajectory Prediction Over a Hybrid Traffic Graph
Sep 27, 2020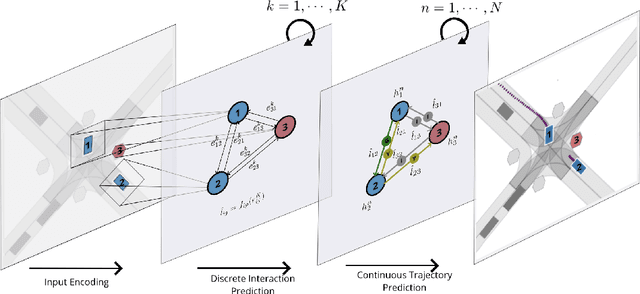
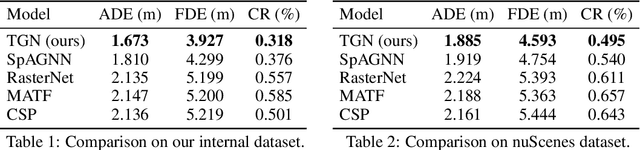
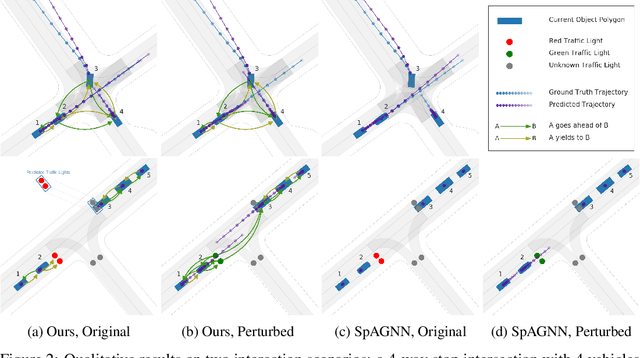

Behavior prediction of traffic actors is an essential component of any real-world self-driving system. Actors' long-term behaviors tend to be governed by their interactions with other actors or traffic elements (traffic lights, stop signs) in the scene. To capture this highly complex structure of interactions, we propose to use a hybrid graph whose nodes represent both the traffic actors as well as the static and dynamic traffic elements present in the scene. The different modes of temporal interaction (e.g., stopping and going) among actors and traffic elements are explicitly modeled by graph edges. This explicit reasoning about discrete interaction types not only helps in predicting future motion, but also enhances the interpretability of the model, which is important for safety-critical applications such as autonomous driving. We predict actors' trajectories and interaction types using a graph neural network, which is trained in a semi-supervised manner. We show that our proposed model, TrafficGraphNet, achieves state-of-the-art trajectory prediction accuracy while maintaining a high level of interpretability.
Joint Interaction and Trajectory Prediction for Autonomous Driving using Graph Neural Networks
Dec 17, 2019
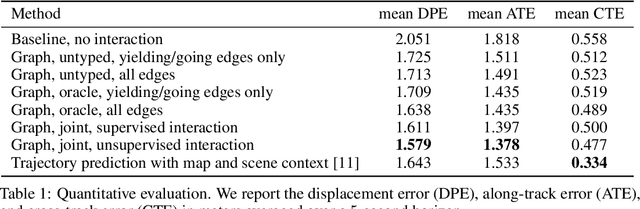
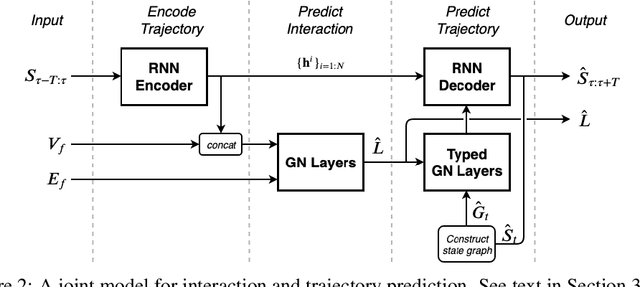
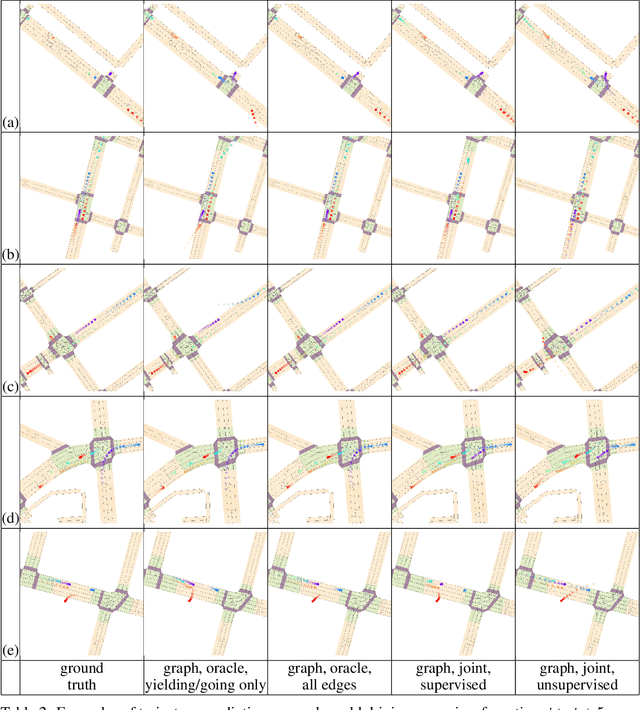
In this work, we aim to predict the future motion of vehicles in a traffic scene by explicitly modeling their pairwise interactions. Specifically, we propose a graph neural network that jointly predicts the discrete interaction modes and 5-second future trajectories for all agents in the scene. Our model infers an interaction graph whose nodes are agents and whose edges capture the long-term interaction intents among the agents. In order to train the model to recognize known modes of interaction, we introduce an auto-labeling function to generate ground truth interaction labels. Using a large-scale real-world driving dataset, we demonstrate that jointly predicting the trajectories along with the explicit interaction types leads to significantly lower trajectory error than baseline methods. Finally, we show through simulation studies that the learned interaction modes are semantically meaningful.