 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Domain Self-Supervised Learning for Accelerated Non-Cartesian MRI Reconstruction
Feb 18, 2023



While enabling accelerated acquisition and improved reconstruction accuracy, current deep MRI reconstruction networks are typically supervised, require fully sampled data, and are limited to Cartesian sampling patterns. These factors limit their practical adoption as fully-sampled MRI is prohibitively time-consuming to acquire clinically. Further, non-Cartesian sampling patterns are particularly desirable as they are more amenable to acceleration and show improved motion robustness. To this end, we present a fully self-supervised approach for accelerated non-Cartesian MRI reconstruction which leverages self-supervision in both k-space and image domains. In training, the undersampled data are split into disjoint k-space domain partitions. For the k-space self-supervision, we train a network to reconstruct the input undersampled data from both the disjoint partitions and from itself. For the image-level self-supervision, we enforce appearance consistency obtained from the original undersampled data and the two partitions. Experimental results on our simulated multi-coil non-Cartesian MRI dataset demonstrate that DDSS can generate high-quality reconstruction that approaches the accuracy of the fully supervised reconstruction, outperforming previous baseline methods. Finally, DDSS is shown to scale to highly challenging real-world clinical MRI reconstruction acquired on a portable low-field (0.064 T) MRI scanner with no data available for supervised training while demonstrating improved image quality as compared to traditional reconstruction, as determined by a radiologist study.
ContraReg: Contrastive Learning of Multi-modality Unsupervised Deformable Image Registration
Jun 27, 2022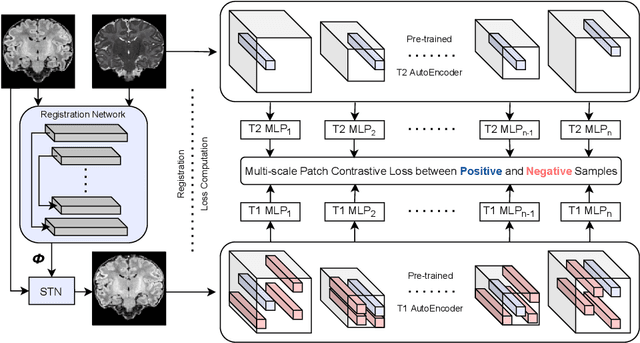
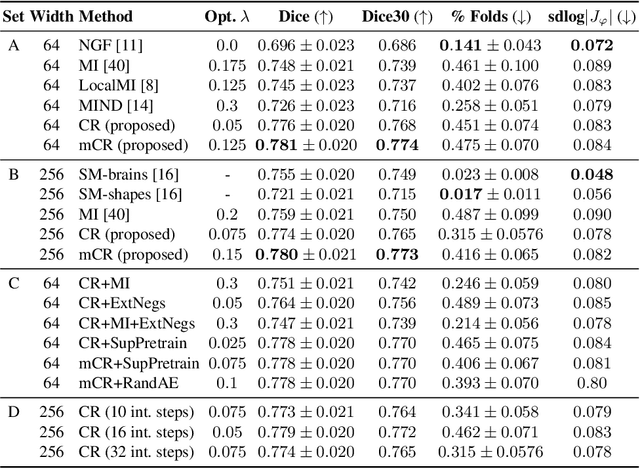
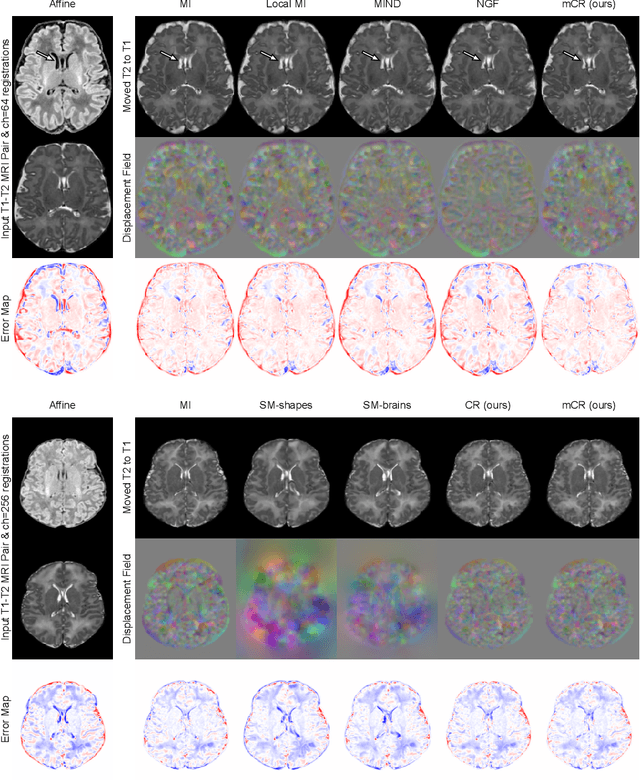
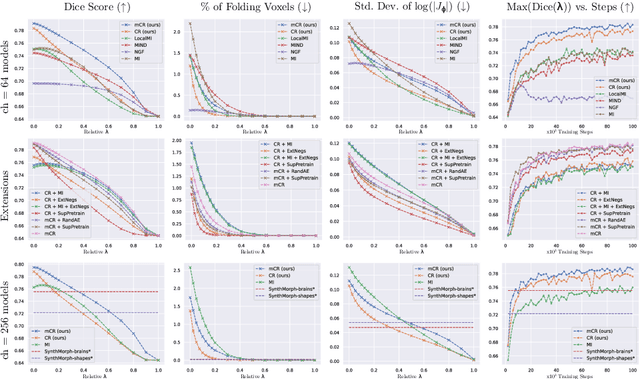
Establishing voxelwise semantic correspondence across distinct imaging modalities is a foundational yet formidable computer vision task. Current multi-modality registration techniques maximize hand-crafted inter-domain similarity functions, are limited in modeling nonlinear intensity-relationships and deformations, and may require significant re-engineering or underperform on new tasks, datasets, and domain pairs. This work presents ContraReg, an unsupervised contrastive representation learning approach to multi-modality deformable registration. By projecting learned multi-scale local patch features onto a jointly learned inter-domain embedding space, ContraReg obtains representations useful for non-rigid multi-modality alignment. Experimentally, ContraReg achieves accurate and robust results with smooth and invertible deformations across a series of baselines and ablations on a neonatal T1-T2 brain MRI registration task with all methods validated over a wide range of deformation regularization strengths.
DSFormer: A Dual-domain Self-supervised Transformer for Accelerated Multi-contrast MRI Reconstruction
Jan 26, 2022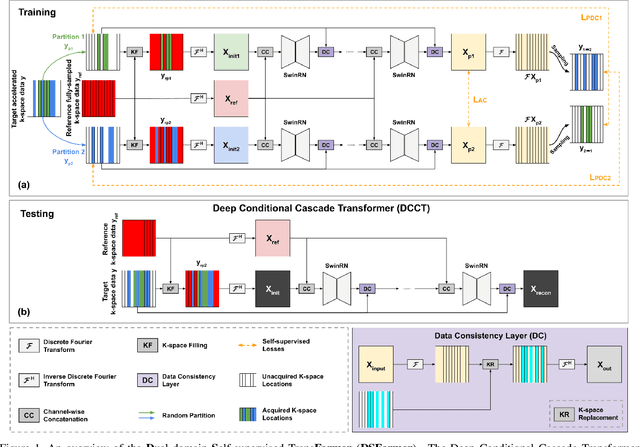
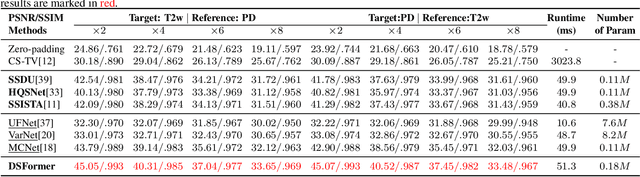
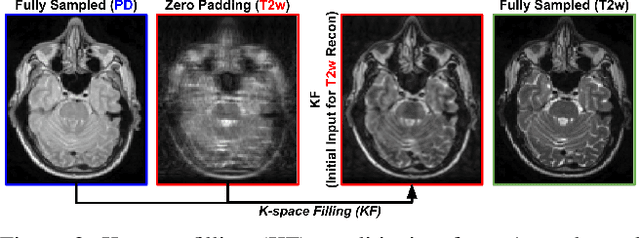
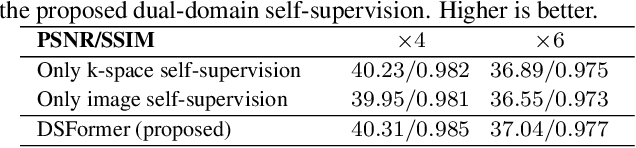
Multi-contrast MRI (MC-MRI) captures multiple complementary imaging modalities to aid in radiological decision-making. Given the need for lowering the time cost of multiple acquisitions, current deep accelerated MRI reconstruction networks focus on exploiting the redundancy between multiple contrasts. However, existing works are largely supervised with paired data and/or prohibitively expensive fully-sampled MRI sequences. Further, reconstruction networks typically rely on convolutional architectures which are limited in their capacity to model long-range interactions and may lead to suboptimal recovery of fine anatomical detail. To these ends, we present a dual-domain self-supervised transformer (DSFormer) for accelerated MC-MRI reconstruction. DSFormer develops a deep conditional cascade transformer (DCCT) consisting of several cascaded Swin transformer reconstruction networks (SwinRN) trained under two deep conditioning strategies to enable MC-MRI information sharing. We further present a dual-domain (image and k-space) self-supervised learning strategy for DCCT to alleviate the costs of acquiring fully sampled training data. DSFormer generates high-fidelity reconstructions which experimentally outperform current fully-supervised baselines. Moreover, we find that DSFormer achieves nearly the same performance when trained either with full supervision or with our proposed dual-domain self-supervision.
Straight to the point: reinforcement learning for user guidance in ultrasound
Mar 02, 2019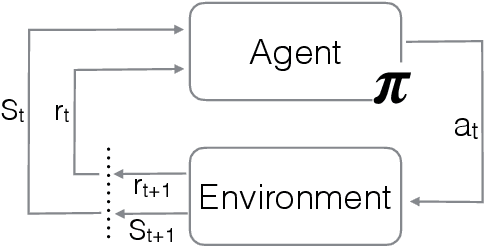
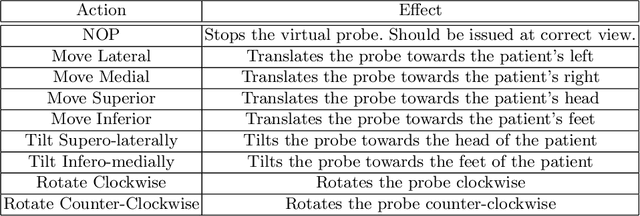
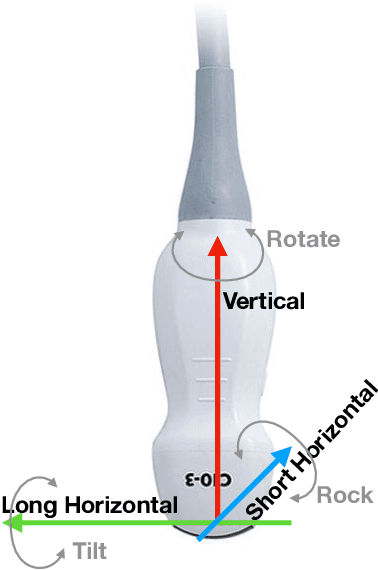
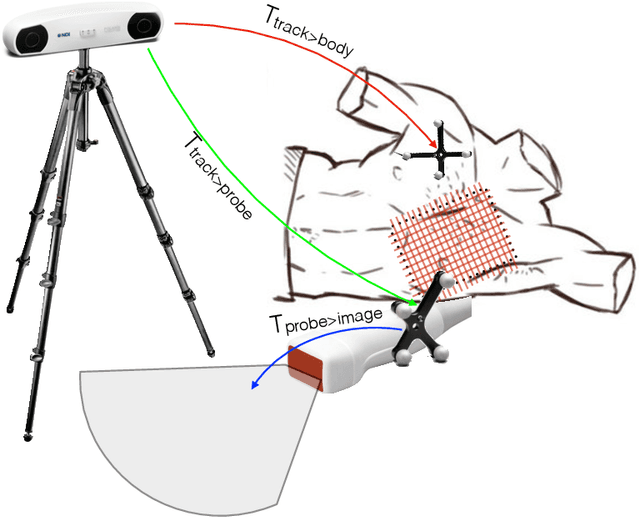
Point of care ultrasound (POCUS) consists in the use of ultrasound imaging in critical or emergency situations to support clinical decisions by healthcare professionals and first responders. In this setting it is essential to be able to provide means to obtain diagnostic data to potentially inexperienced users who did not receive an extensive medical training. Interpretation and acquisition of ultrasound images is not trivial. First, the user needs to find a suitable sound window which can be used to get a clear image, and then he needs to correctly interpret it to perform a diagnosis. Although many recent approaches focus on developing smart ultrasound devices that add interpretation capabilities to existing systems, our goal in this paper is to present a reinforcement learning (RL) strategy which is capable to guide novice users to the correct sonic window and enable them to obtain clinically relevant pictures of the anatomy of interest. We apply our approach to cardiac images acquired from the parasternal long axis (PLAx) view of the left ventricle of the heart.
Learning detectors of malicious web requests for intrusion detection in network traffic
Feb 08, 2017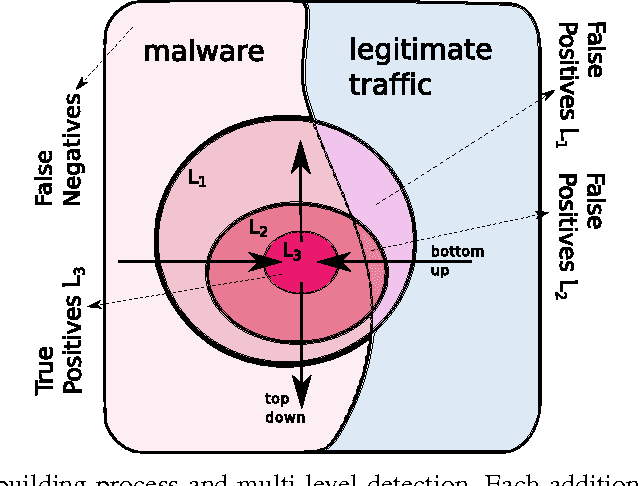
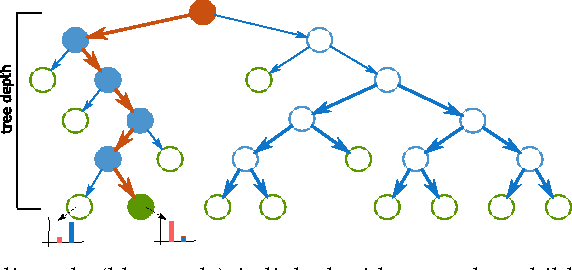
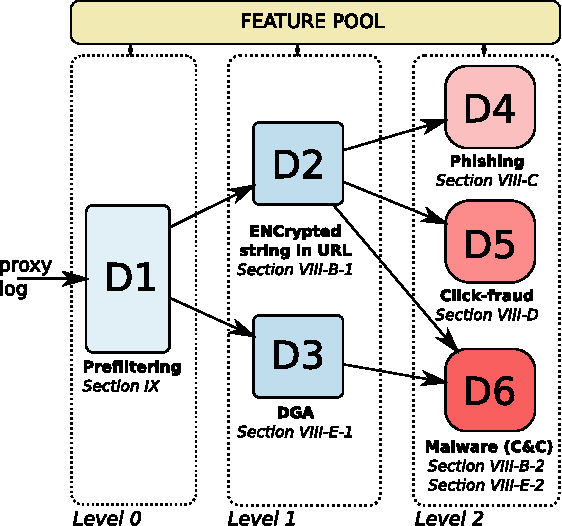
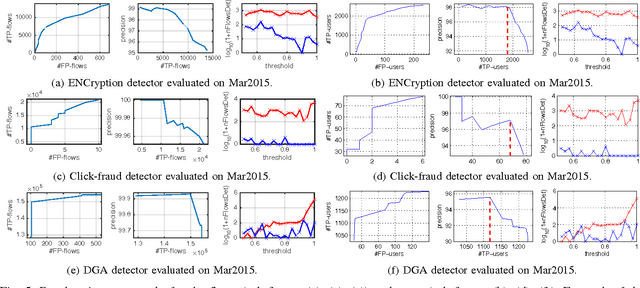
This paper proposes a generic classification system designed to detect security threats based on the behavior of malware samples. The system relies on statistical features computed from proxy log fields to train detectors using a database of malware samples. The behavior detectors serve as basic reusable building blocks of the multi-level detection architecture. The detectors identify malicious communication exploiting encrypted URL strings and domains generated by a Domain Generation Algorithm (DGA) which are frequently used in Command and Control (C&C), phishing, and click fraud. Surprisingly, very precise detectors can be built given only a limited amount of information extracted from a single proxy log. This way, the computational requirements of the detectors are kept low which allows for deployment on a wide range of security devices and without depending on traffic context such as DNS logs, Whois records, webpage content, etc. Results on several weeks of live traffic from 100+ companies having 350k+ hosts show correct detection with a precision exceeding 95% of malicious flows, 95% of malicious URLs and 90% of infected hosts. In addition, a comparison with a signature and rule-based solution shows that our system is able to detect significant amount of new threats.