 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
MFTIQ: Multi-Flow Tracker with Independent Matching Quality Estimation
Nov 14, 2024



In this work, we present MFTIQ, a novel dense long-term tracking model that advances the Multi-Flow Tracker (MFT) framework to address challenges in point-level visual tracking in video sequences. MFTIQ builds upon the flow-chaining concepts of MFT, integrating an Independent Quality (IQ) module that separates correspondence quality estimation from optical flow computations. This decoupling significantly enhances the accuracy and flexibility of the tracking process, allowing MFTIQ to maintain reliable trajectory predictions even in scenarios of prolonged occlusions and complex dynamics. Designed to be "plug-and-play", MFTIQ can be employed with any off-the-shelf optical flow method without the need for fine-tuning or architectural modifications. Experimental validations on the TAP-Vid Davis dataset show that MFTIQ with RoMa optical flow not only surpasses MFT but also performs comparably to state-of-the-art trackers while having substantially faster processing speed. Code and models available at https://github.com/serycjon/MFTIQ .
MFT: Long-Term Tracking of Every Pixel
May 22, 2023



We propose MFT -- Multi-Flow dense Tracker -- a novel method for dense, pixel-level, long-term tracking. The approach exploits optical flows estimated not only between consecutive frames, but also for pairs of frames at logarithmically spaced intervals. It then selects the most reliable sequence of flows on the basis of estimates of its geometric accuracy and the probability of occlusion, both provided by a pre-trained CNN. We show that MFT achieves state-of-the-art results on the TAP-Vid-DAVIS benchmark, outperforming the baselines, their combination, and published methods by a significant margin, achieving an average position accuracy of 70.8%, average Jaccard of 56.1% and average occlusion accuracy of 86.9%. The method is insensitive to medium-length occlusions and it is robustified by estimating flow with respect to the reference frame, which reduces drift.
Continual Occlusions and Optical Flow Estimation
Nov 05, 2018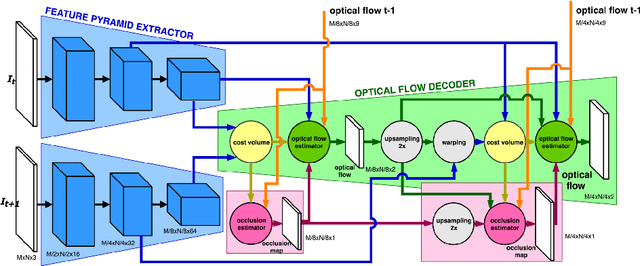
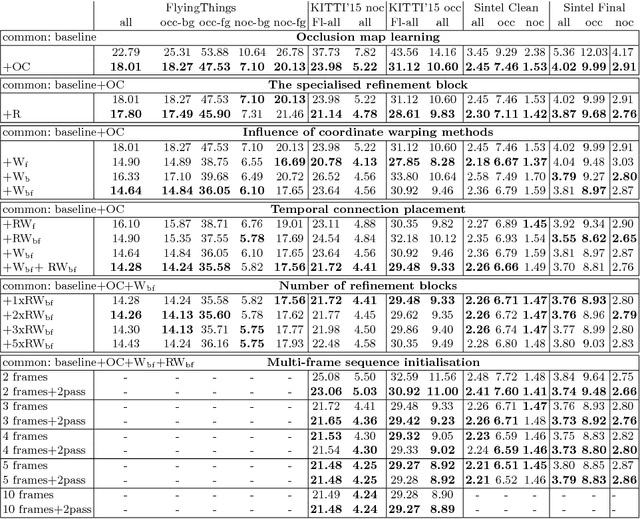
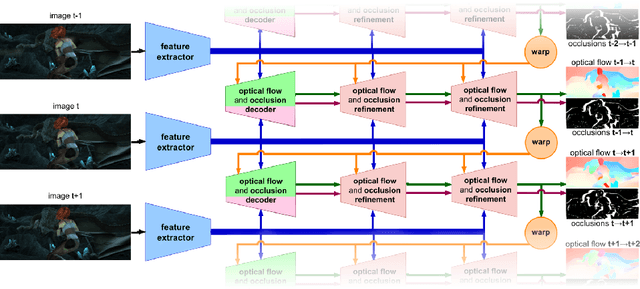

Two optical flow estimation problems are addressed: i) occlusion estimation and handling, and ii) estimation from image sequences longer than two frames. The proposed ContinualFlow method estimates occlusions before flow, avoiding the use of flow corrupted by occlusions for their estimation. We show that providing occlusion masks as an additional input to flow estimation improves the standard performance metric by more than 25\% on both KITTI and Sintel. As a second contribution, a novel method for incorporating information from past frames into flow estimation is introduced. The previous frame flow serves as an input to occlusion estimation and as a prior in occluded regions, i.e. those without visual correspondences. By continually using the previous frame flow, ContinualFlow performance improves further by 18\% on KITTI and 7\% on Sintel, achieving top performance on KITTI and Sintel.