 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Factor Adaptation for User Embedding via Multitask Learning
Feb 22, 2021

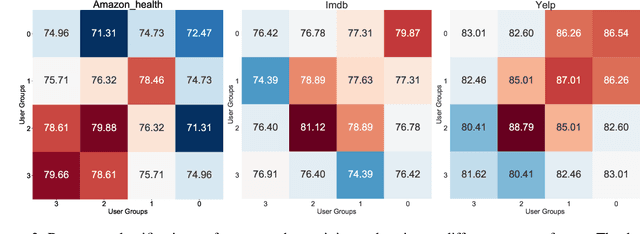

Language varies across users and their interested fields in social media data: words authored by a user across his/her interests may have different meanings (e.g., cool) or sentiments (e.g., fast). However, most of the existing methods to train user embeddings ignore the variations across user interests, such as product and movie categories (e.g., drama vs. action). In this study, we treat the user interest as domains and empirically examine how the user language can vary across the user factor in three English social media datasets. We then propose a user embedding model to account for the language variability of user interests via a multitask learning framework. The model learns user language and its variations without human supervision. While existing work mainly evaluated the user embedding by extrinsic tasks, we propose an intrinsic evaluation via clustering and evaluate user embeddings by an extrinsic task, text classification. The experiments on the three English-language social media datasets show that our proposed approach can generally outperform baselines via adapting the user factor.
Why Overfitting Isn't Always Bad: Retrofitting Cross-Lingual Word Embeddings to Dictionaries
May 01, 2020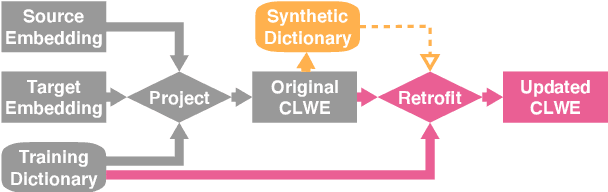
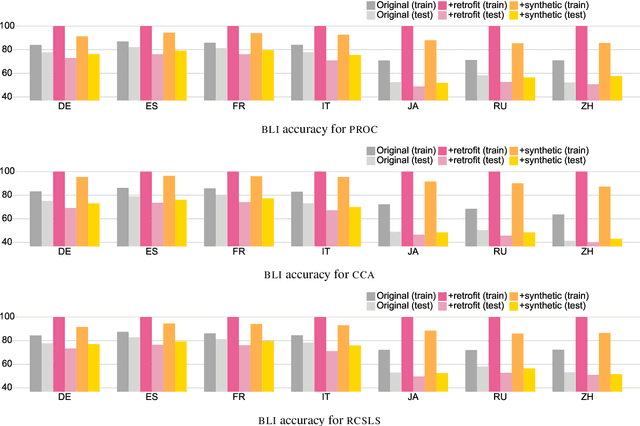

Cross-lingual word embeddings (CLWE) are often evaluated on bilingual lexicon induction (BLI). Recent CLWE methods use linear projections, which underfit the training dictionary, to generalize on BLI. However, underfitting can hinder generalization to other downstream tasks that rely on words from the training dictionary. We address this limitation by retrofitting CLWE to the training dictionary, which pulls training translation pairs closer in the embedding space and overfits the training dictionary. This simple post-processing step often improves accuracy on two downstream tasks, despite lowering BLI test accuracy. We also retrofit to both the training dictionary and a synthetic dictionary induced from CLWE, which sometimes generalizes even better on downstream tasks. Our results confirm the importance of fully exploiting training dictionary in downstream tasks and explains why BLI is a flawed CLWE evaluation.
Multilingual Twitter Corpus and Baselines for Evaluating Demographic Bias in Hate Speech Recognition
Mar 03, 2020

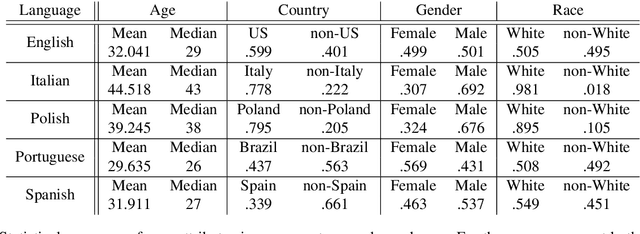

Existing research on fairness evaluation of document classification models mainly uses synthetic monolingual data without ground truth for author demographic attributes. In this work, we assemble and publish a multilingual Twitter corpus for the task of hate speech detection with inferred four author demographic factors: age, country, gender and race/ethnicity. The corpus covers five languages: English, Italian, Polish, Portuguese and Spanish. We evaluate the inferred demographic labels with a crowdsourcing platform, Figure Eight. To examine factors that can cause biases, we take an empirical analysis of demographic predictability on the English corpus. We measure the performance of four popular document classifiers and evaluate the fairness and bias of the baseline classifiers on the author-level demographic attributes.
Evaluating Topic Quality with Posterior Variability
Sep 15, 2019

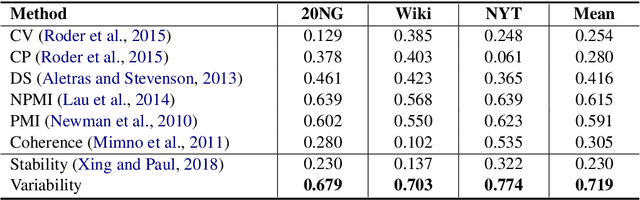

Probabilistic topic models such as latent Dirichlet allocation (LDA) are popularly used with Bayesian inference methods such as Gibbs sampling to learn posterior distributions over topic model parameters. We derive a novel measure of LDA topic quality using the variability of the posterior distributions. Compared to several existing baselines for automatic topic evaluation, the proposed metric achieves state-of-the-art correlations with human judgments of topic quality in experiments on three corpora. We additionally demonstrate that topic quality estimation can be further improved using a supervised estimator that combines multiple metrics.
A Resource-Free Evaluation Metric for Cross-Lingual Word Embeddings Based on Graph Modularity
Jun 05, 2019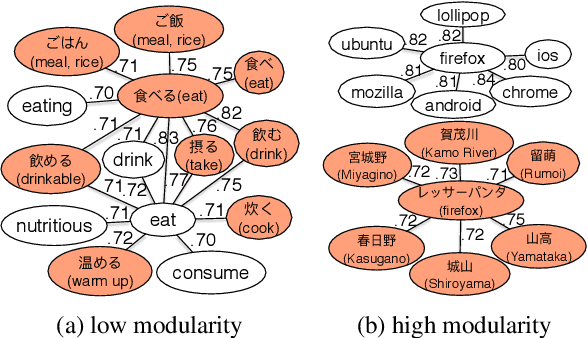

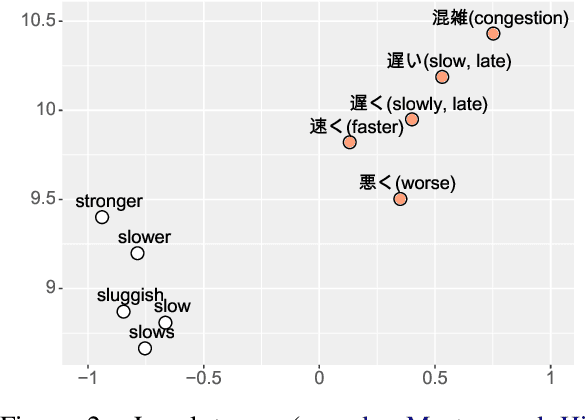
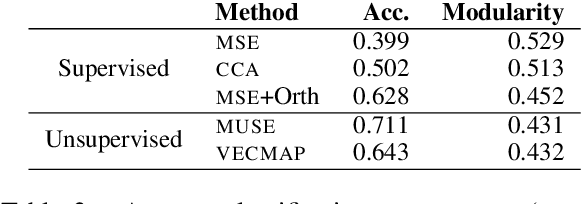
Cross-lingual word embeddings encode the meaning of words from different languages into a shared low-dimensional space. An important requirement for many downstream tasks is that word similarity should be independent of language - i.e., word vectors within one language should not be more similar to each other than to words in another language. We measure this characteristic using modularity, a network measurement that measures the strength of clusters in a graph. Modularity has a moderate to strong correlation with three downstream tasks, even though modularity is based only on the structure of embeddings and does not require any external resources. We show through experiments that modularity can serve as an intrinsic validation metric to improve unsupervised cross-lingual word embeddings, particularly on distant language pairs in low-resource settings.
Understanding Crosslingual Transfer Mechanisms in Probabilistic Topic Modeling
Oct 13, 2018


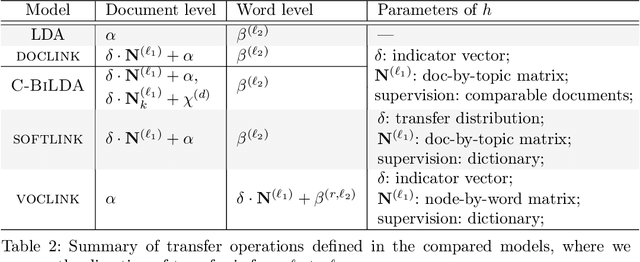
Probabilistic topic modeling is a popular choice as the first step of crosslingual tasks to enable knowledge transfer and extract multilingual features. While many multilingual topic models have been developed, their assumptions on the training corpus are quite varied, and it is not clear how well the models can be applied under various training conditions. In this paper, we systematically study the knowledge transfer mechanisms behind different multilingual topic models, and through a broad set of experiments with four models on ten languages, we provide empirical insights that can inform the selection and future development of multilingual topic models.
Learning Multilingual Topics from Incomparable Corpus
Jun 11, 2018



Multilingual topic models enable crosslingual tasks by extracting consistent topics from multilingual corpora. Most models require parallel or comparable training corpora, which limits their ability to generalize. In this paper, we first demystify the knowledge transfer mechanism behind multilingual topic models by defining an alternative but equivalent formulation. Based on this analysis, we then relax the assumption of training data required by most existing models, creating a model that only requires a dictionary for training. Experiments show that our new method effectively learns coherent multilingual topics from partially and fully incomparable corpora with limited amounts of dictionary resources.
Lessons from the Bible on Modern Topics: Low-Resource Multilingual Topic Model Evaluation
Apr 26, 2018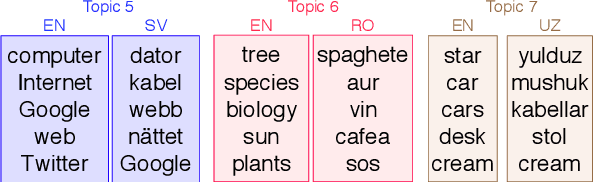

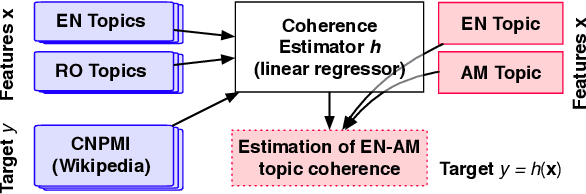
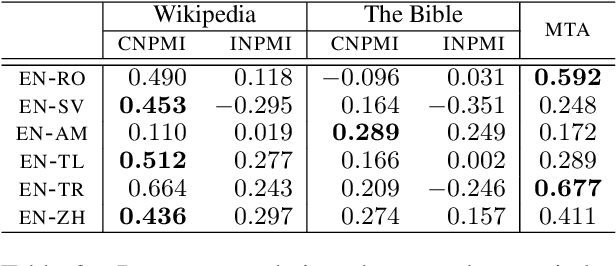
Multilingual topic models enable document analysis across languages through coherent multilingual summaries of the data. However, there is no standard and effective metric to evaluate the quality of multilingual topics. We introduce a new intrinsic evaluation of multilingual topic models that correlates well with human judgments of multilingual topic coherence as well as performance in downstream applications. Importantly, we also study evaluation for low-resource languages. Because standard metrics fail to accurately measure topic quality when robust external resources are unavailable, we propose an adaptation model that improves the accuracy and reliability of these metrics in low-resource settings.