Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Crosslingual Transfer Mechanisms in Probabilistic Topic Modeling
Paper and Code



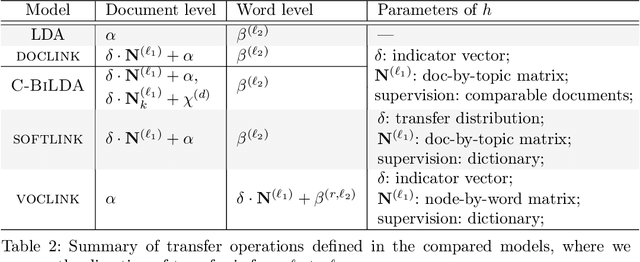
Probabilistic topic modeling is a popular choice as the first step of crosslingual tasks to enable knowledge transfer and extract multilingual features. While many multilingual topic models have been developed, their assumptions on the training corpus are quite varied, and it is not clear how well the models can be applied under various training conditions. In this paper, we systematically study the knowledge transfer mechanisms behind different multilingual topic models, and through a broad set of experiments with four models on ten languages, we provide empirical insights that can inform the selection and future development of multilingual topic models.
View paper on