 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 6D Object Pose Estimation of metallic Household and Industry Objects
Mar 05, 2025


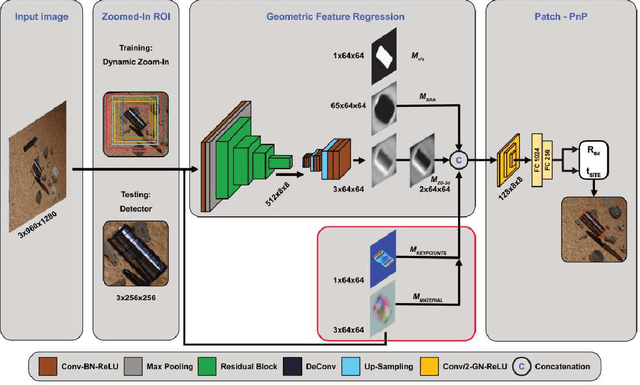
6D object pose estimation suffers from reduced accuracy when applied to metallic objects. We set out to improve the state-of-the-art by addressing challenges such as reflections and specular highlights in industrial applications. Our novel BOP-compatible dataset, featuring a diverse set of metallic objects (cans, household, and industrial items) under various lighting and background conditions, provides additional geometric and visual cues. We demonstrate that these cues can be effectively leveraged to enhance overall performance. To illustrate the usefulness of the additional features, we improve upon the GDRNPP algorithm by introducing an additional keypoint prediction and material estimator head in order to improve spatial scene understanding. Evaluations on the new dataset show improved accuracy for metallic objects, supporting the hypothesis that additional geometric and visual cues can improve learning.
UniMorph 4.0: Universal Morphology
May 10, 2022

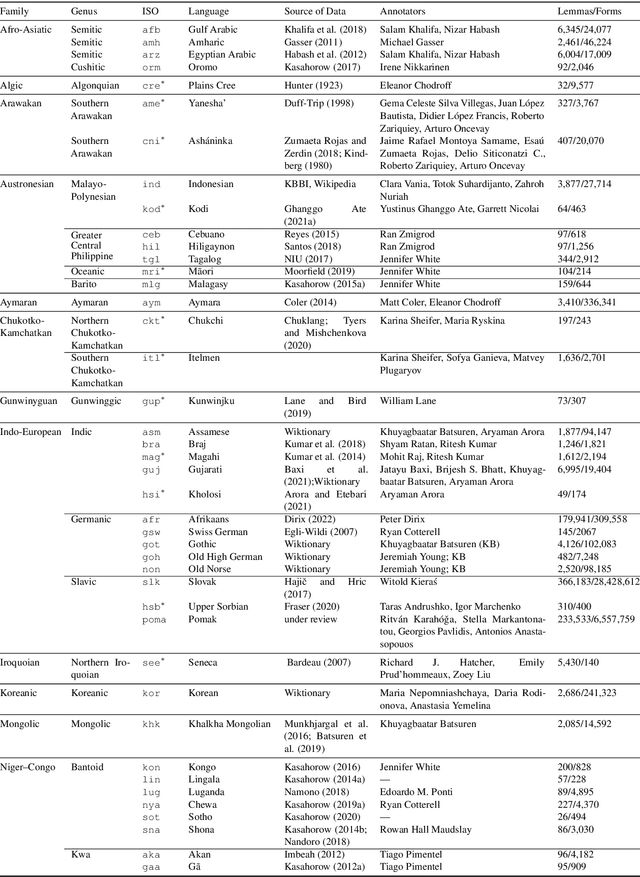
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Contemporary Amharic Corpus: Automatically Morpho-Syntactically Tagged Amharic Corpus
Jun 14, 2021


We introduced the contemporary Amharic corpus, which is automatically tagged for morpho-syntactic information. Texts are collected from 25,199 documents from different domains and about 24 million orthographic words are tokenized. Since it is partly a web corpus, we made some automatic spelling error correction. We have also modified the existing morphological analyzer, HornMorpho, to use it for the automatic tagging.
* Published in Proceedings of the First Workshop on Linguistic Resources for Natural Language Processing at COLING 2018
Mainumby: un Ayudante para la Traducción Castellano-Guaraní
Oct 19, 2018A wide range of applications play an important role in the daily work of the modern human translator. However, the computational tools designed to aid in the process of translation only benefit translation from or to a small minority of the 7,000 languages of the world, those that we may call "privileged languages". As for those translators who work with the remaining languages, the marginalized languages in the digital world, they cannot benefit from the tools that are speeding up the production of translation in the privileged languages. We may ask whether it is possible to bridge the gap between what is available for these languages and for the marginalized ones. This paper proposes a framework for computer-assisted translation into marginalized languages and its implementation in a web application for Spanish-Guarani translation. The proposed system is based on a new theory for phrase-level translation in contexts where adequate bilingual corpora are not available: Translation by Generalized Segments (referred to as Minimal Dependency Translation in previous work).
Minimal Dependency Translation: a Framework for Computer-Assisted Translation for Under-Resourced Languages
Oct 02, 2017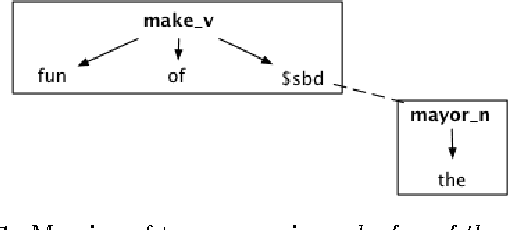
This paper introduces Minimal Dependency Translation (MDT), an ongoing project to develop a rule-based framework for the creation of rudimentary bilingual lexicon-grammars for machine translation and computer-assisted translation into and out of under-resourced languages as well as initial steps towards an implementation of MDT for English-to-Amharic translation. The basic units in MDT, called groups, are headed multi-item sequences. In addition to wordforms, groups may contain lexemes, syntactic-semantic categories, and grammatical features. Each group is associated with one or more translations, each of which is a group in a target language. During translation, constraint satisfaction is used to select a set of source-language groups for the input sentence and to sequence the words in the associated target-language groups.
A Dynamic Approach to Rhythm in Language: Toward a Temporal Phonology
Aug 13, 1995


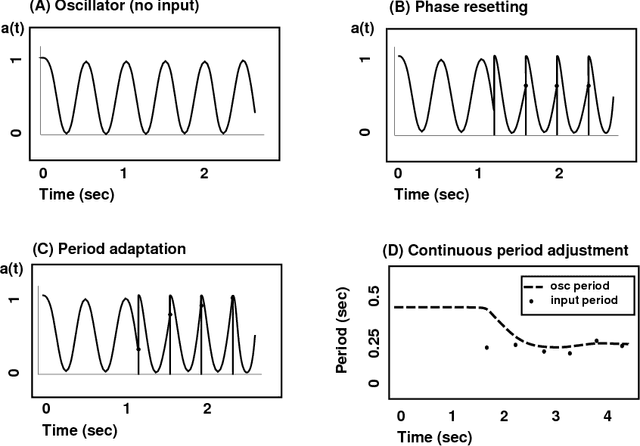
It is proposed that the theory of dynamical systems offers appropriate tools to model many phonological aspects of both speech production and perception. A dynamic account of speech rhythm is shown to be useful for description of both Japanese mora timing and English timing in a phrase repetition task. This orientation contrasts fundamentally with the more familiar symbolic approach to phonology, in which time is modeled only with sequentially arrayed symbols. It is proposed that an adaptive oscillator offers a useful model for perceptual entrainment (or `locking in') to the temporal patterns of speech production. This helps to explain why speech is often perceived to be more regular than experimental measurements seem to justify. Because dynamic models deal with real time, they also help us understand how languages can differ in their temporal detail---contributing to foreign accents, for example. The fact that languages differ greatly in their temporal detail suggests that these effects are not mere motor universals, but that dynamical models are intrinsic components of the phonological characterization of language.
Transfer in a Connectionist Model of the Acquisition of Morphology
Jul 20, 1995The morphological systems of natural languages are replete with examples of the same devices used for multiple purposes: (1) the same type of morphological process (for example, suffixation for both noun case and verb tense) and (2) identical morphemes (for example, the same suffix for English noun plural and possessive). These sorts of similarity would be expected to convey advantages on language learners in the form of transfer from one morphological category to another. Connectionist models of morphology acquisition have been faulted for their supposed inability to represent phonological similarity across morphological categories and hence to facilitate transfer. This paper describes a connectionist model of the acquisition of morphology which is shown to exhibit transfer of this type. The model treats the morphology acquisition problem as one of learning to map forms onto meanings and vice versa. As the network learns these mappings, it makes phonological generalizations which are embedded in connection weights. Since these weights are shared by different morphological categories, transfer is enabled. In a set of experiments with artificial stimuli, networks were trained first on one morphological task (e.g., tense) and then on a second (e.g., number). It is shown that in the context of suffixation, prefixation, and template rules, the second task is facilitated when the second category either makes use of the same forms or the same general process type (e.g., prefixation) as the first.
Modularity in a Connectionist Model of Morphology Acquisition
May 30, 1994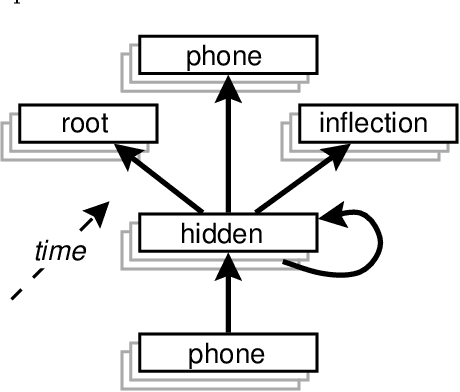
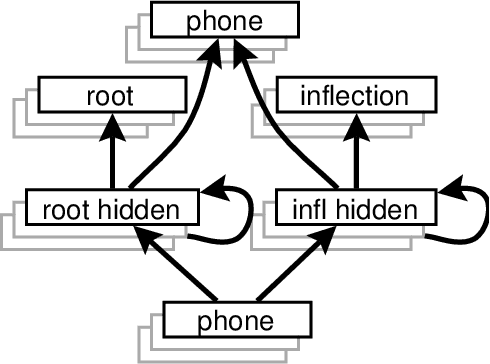
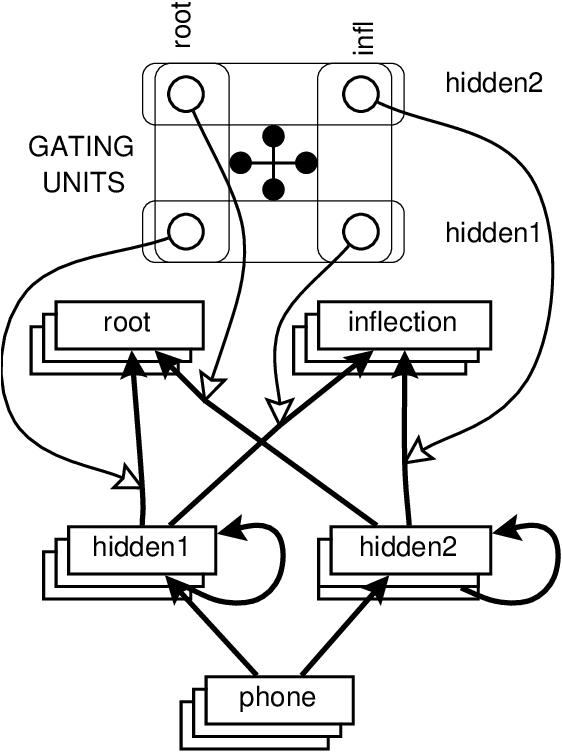
This paper describes a modular connectionist model of the acquisition of receptive inflectional morphology. The model takes inputs in the form of phones one at a time and outputs the associated roots and inflections. In its simplest version, the network consists of separate simple recurrent subnetworks for root and inflection identification; both networks take the phone sequence as inputs. It is shown that the performance of the two separate modular networks is superior to a single network responsible for both root and inflection identification. In a more elaborate version of the model, the network learns to use separate hidden-layer modules to solve the separate tasks of root and inflection identification.
* 7 pages, uuencoded compressed Postscript file
Acquiring Receptive Morphology: A Connectionist Model
May 27, 1994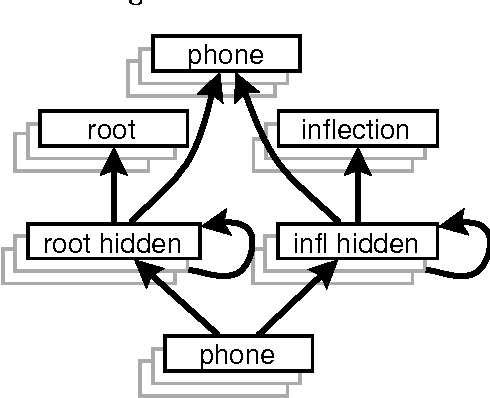
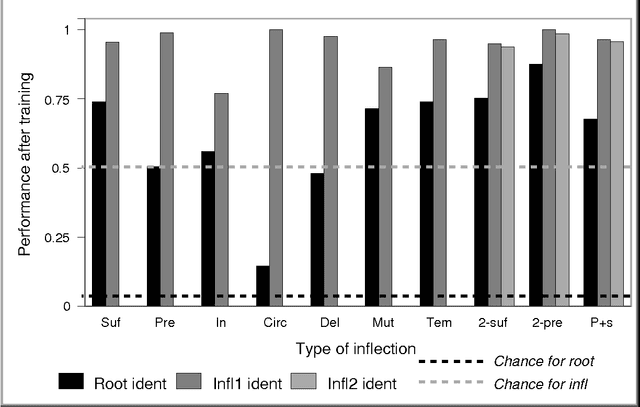
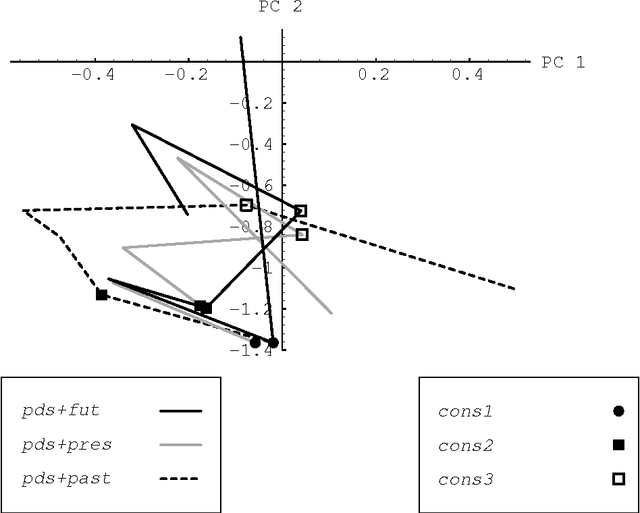
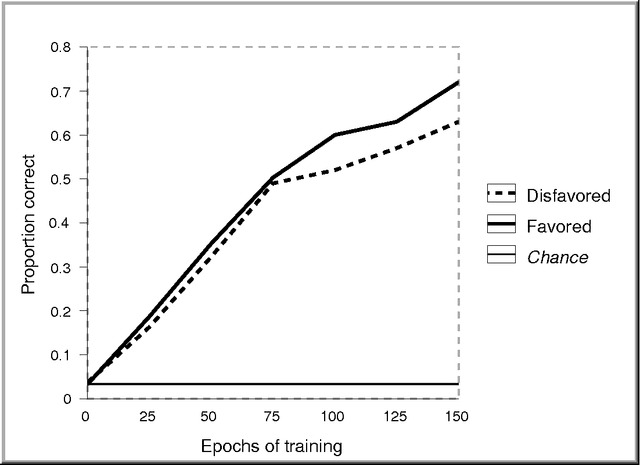
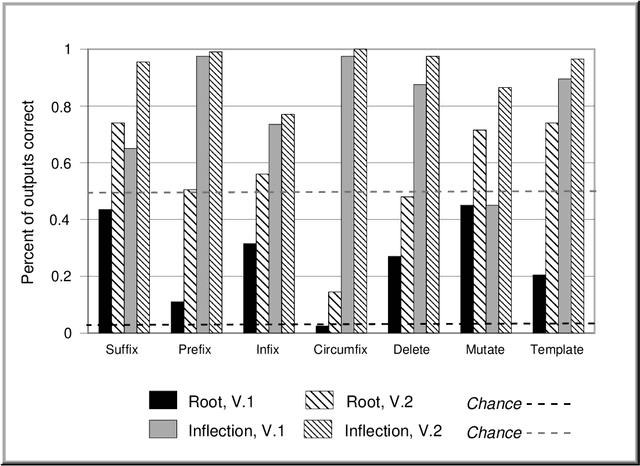
This paper describes a modular connectionist model of the acquisition of receptive inflectional morphology. The model takes inputs in the form of phones one at a time and outputs the associated roots and inflections. Simulations using artificial language stimuli demonstrate the capacity of the model to learn suffixation, prefixation, infixation, circumfixation, mutation, template, and deletion rules. Separate network modules responsible for syllables enable to the network to learn simple reduplication rules as well. The model also embodies constraints against association-line crossing.
* 8 pages, Postscript file; extract with Unix uudecode and uncompress