 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Transparent and Opaque Drinking Glasses with the Help of Zero-shot Learning
Mar 19, 2025

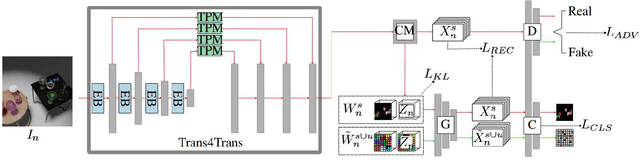
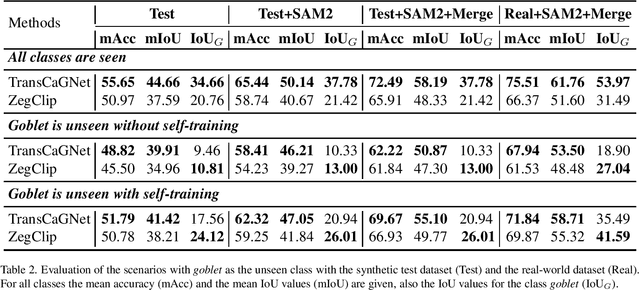
Segmenting transparent structures in images is challenging since they are difficult to distinguish from the background. Common examples are drinking glasses, which are a ubiquitous part of our lives and appear in many different shapes and sizes. In this work we propose TransCaGNet, a modified version of the zero-shot model CaGNet. We exchange the segmentation backbone with the architecture of Trans4Trans to be capable of segmenting transparent objects. Since some glasses are rarely captured, we use zeroshot learning to be able to create semantic segmentations of glass categories not given during training. We propose a novel synthetic dataset covering a diverse set of different environmental conditions. Additionally we capture a real-world evaluation dataset since most applications take place in the real world. Comparing our model with Zeg-Clip we are able to show that TransCaGNet produces better mean IoU and accuracy values while ZegClip outperforms it mostly for unseen classes. To improve the segmentation results, we combine the semantic segmentation of the models with the segmentation results of SAM 2. Our evaluation emphasizes that distinguishing between different classes is challenging for the models due to similarity, points of view, or coverings. Taking this behavior into account, we assign glasses multiple possible categories. The modification leads to an improvement up to 13.68% for the mean IoU and up to 17.88% for the mean accuracy values on the synthetic dataset. Using our difficult synthetic dataset for training, the models produce even better results on the real-world dataset. The mean IoU is improved up to 5.55% and the mean accuracy up to 5.72% on the real-world dataset.
Improving 6D Object Pose Estimation of metallic Household and Industry Objects
Mar 05, 2025


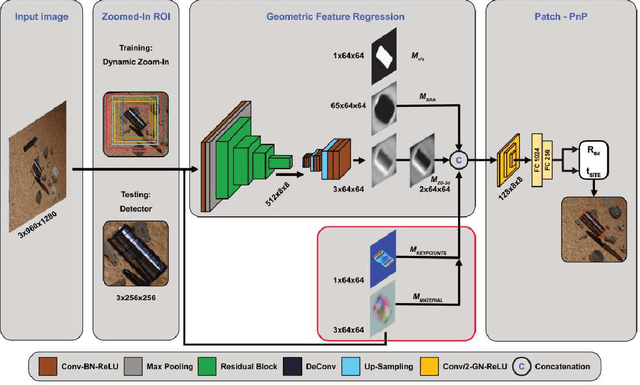
6D object pose estimation suffers from reduced accuracy when applied to metallic objects. We set out to improve the state-of-the-art by addressing challenges such as reflections and specular highlights in industrial applications. Our novel BOP-compatible dataset, featuring a diverse set of metallic objects (cans, household, and industrial items) under various lighting and background conditions, provides additional geometric and visual cues. We demonstrate that these cues can be effectively leveraged to enhance overall performance. To illustrate the usefulness of the additional features, we improve upon the GDRNPP algorithm by introducing an additional keypoint prediction and material estimator head in order to improve spatial scene understanding. Evaluations on the new dataset show improved accuracy for metallic objects, supporting the hypothesis that additional geometric and visual cues can improve learning.
EfficientPose 6D: Scalable and Efficient 6D Object Pose Estimation
Feb 19, 2025In industrial applications requiring real-time feedback, such as quality control and robotic manipulation, the demand for high-speed and accurate pose estimation remains critical. Despite advances improving speed and accuracy in pose estimation, finding a balance between computational efficiency and accuracy poses significant challenges in dynamic environments. Most current algorithms lack scalability in estimation time, especially for diverse datasets, and the state-of-the-art (SOTA) methods are often too slow. This study focuses on developing a fast and scalable set of pose estimators based on GDRNPP to meet or exceed current benchmarks in accuracy and robustness, particularly addressing the efficiency-accuracy trade-off essential in real-time scenarios. We propose the AMIS algorithm to tailor the utilized model according to an application-specific trade-off between inference time and accuracy. We further show the effectiveness of the AMIS-based model choice on four prominent benchmark datasets (LM-O, YCB-V, T-LESS, and ITODD).
Influence of Water Droplet Contamination for Transparency Segmentation
May 21, 2024Computer vision techniques are on the rise for industrial applications, like process supervision and autonomous agents, e.g., in the healthcare domain and dangerous environments. While the general usability of these techniques is high, there are still challenging real-world use-cases. Especially transparent structures, which can appear in the form of glass doors, protective casings or everyday objects like glasses, pose a challenge for computer vision methods. This paper evaluates the combination of transparent objects in conjunction with (naturally occurring) contamination through environmental effects like hazing. We introduce a novel publicly available dataset containing 489 images incorporating three grades of water droplet contamination on transparent structures and examine the resulting influence on transparency handling. Our findings show, that contaminated transparent objects are easier to segment and that we are able to distinguish between different severity levels of contamination with a current state-of-the art machine-learning model. This in turn opens up the possibility to enhance computer vision systems regarding resilience against, e.g., datashifts through contaminated protection casings or implement an automated cleaning alert.
Transparency Distortion Robustness for SOTA Image Segmentation Tasks
May 21, 2024



Semantic Image Segmentation facilitates a multitude of real-world applications ranging from autonomous driving over industrial process supervision to vision aids for human beings. These models are usually trained in a supervised fashion using example inputs. Distribution Shifts between these examples and the inputs in operation may cause erroneous segmentations. The robustness of semantic segmentation models against distribution shifts caused by differing camera or lighting setups, lens distortions, adversarial inputs and image corruptions has been topic of recent research. However, robustness against spatially varying radial distortion effects that can be caused by uneven glass structures (e.g. windows) or the chaotic refraction in heated air has not been addressed by the research community yet. We propose a method to synthetically augment existing datasets with spatially varying distortions. Our experiments show, that these distortion effects degrade the performance of state-of-the-art segmentation models. Pretraining and enlarged model capacities proof to be suitable strategies for mitigating performance degradation to some degree, while fine-tuning on distorted images only leads to marginal performance improvements.
An Empirical Study of Uncertainty Estimation Techniques for Detecting Drift in Data Streams
Nov 22, 2023In safety-critical domains such as autonomous driving and medical diagnosis, the reliability of machine learning models is crucial. One significant challenge to reliability is concept drift, which can cause model deterioration over time. Traditionally, drift detectors rely on true labels, which are often scarce and costly. This study conducts a comprehensive empirical evaluation of using uncertainty values as substitutes for error rates in detecting drifts, aiming to alleviate the reliance on labeled post-deployment data. We examine five uncertainty estimation methods in conjunction with the ADWIN detector across seven real-world datasets. Our results reveal that while the SWAG method exhibits superior calibration, the overall accuracy in detecting drifts is not notably impacted by the choice of uncertainty estimation method, with even the most basic method demonstrating competitive performance. These findings offer valuable insights into the practical applicability of uncertainty-based drift detection in real-world, safety-critical applications.