 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIVD: Adaptive Edge-Cloud Collaboration for Accurate and Efficient Industrial Visual Detection
Jan 08, 2026Multimodal large language models (MLLMs) demonstrate exceptional capabilities in semantic understanding and visual reasoning, yet they still face challenges in precise object localization and resource-constrained edge-cloud deployment. To address this, this paper proposes the AIVD framework, which achieves unified precise localization and high-quality semantic generation through the collaboration between lightweight edge detectors and cloud-based MLLMs. To enhance the cloud MLLM's robustness against edge cropped-box noise and scenario variations, we design an efficient fine-tuning strategy with visual-semantic collaborative augmentation, significantly improving classification accuracy and semantic consistency. Furthermore, to maintain high throughput and low latency across heterogeneous edge devices and dynamic network conditions, we propose a heterogeneous resource-aware dynamic scheduling algorithm. Experimental results demonstrate that AIVD substantially reduces resource consumption while improving MLLM classification performance and semantic generation quality. The proposed scheduling strategy also achieves higher throughput and lower latency across diverse scenarios.
UPETrack: Unidirectional Position Estimation for Tracking Occluded Deformable Linear Objects
Dec 10, 2025Real-time state tracking of Deformable Linear Objects (DLOs) is critical for enabling robotic manipulation of DLOs in industrial assembly, medical procedures, and daily-life applications. However, the high-dimensional configuration space, nonlinear dynamics, and frequent partial occlusions present fundamental barriers to robust real-time DLO tracking. To address these limitations, this study introduces UPETrack, a geometry-driven framework based on Unidirectional Position Estimation (UPE), which facilitates tracking without the requirement for physical modeling, virtual simulation, or visual markers. The framework operates in two phases: (1) visible segment tracking is based on a Gaussian Mixture Model (GMM) fitted via the Expectation Maximization (EM) algorithm, and (2) occlusion region prediction employing UPE algorithm we proposed. UPE leverages the geometric continuity inherent in DLO shapes and their temporal evolution patterns to derive a closed-form positional estimator through three principal mechanisms: (i) local linear combination displacement term, (ii) proximal linear constraint term, and (iii) historical curvature term. This analytical formulation allows efficient and stable estimation of occluded nodes through explicit linear combinations of geometric components, eliminating the need for additional iterative optimization. Experimental results demonstrate that UPETrack surpasses two state-of-the-art tracking algorithms, including TrackDLO and CDCPD2, in both positioning accuracy and computational efficiency.
Learning Smooth and Expressive Interatomic Potentials for Physical Property Prediction
Feb 17, 2025



Machine learning interatomic potentials (MLIPs) have become increasingly effective at approximating quantum mechanical calculations at a fraction of the computational cost. However, lower errors on held out test sets do not always translate to improved results on downstream physical property prediction tasks. In this paper, we propose testing MLIPs on their practical ability to conserve energy during molecular dynamic simulations. If passed, improved correlations are found between test errors and their performance on physical property prediction tasks. We identify choices which may lead to models failing this test, and use these observations to improve upon highly-expressive models. The resulting model, eSEN, provides state-of-the-art results on a range of physical property prediction tasks, including materials stability prediction, thermal conductivity prediction, and phonon calculations.
Open Materials 2024 (OMat24) Inorganic Materials Dataset and Models
Oct 16, 2024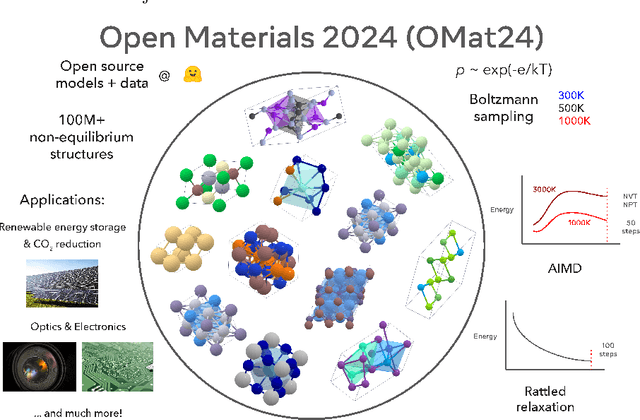
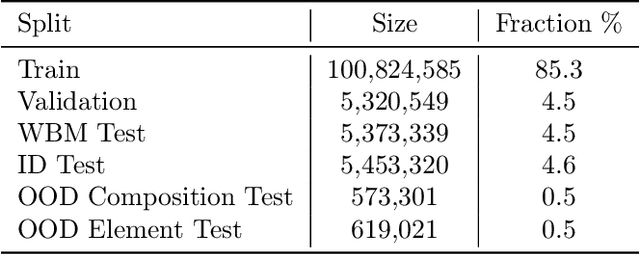
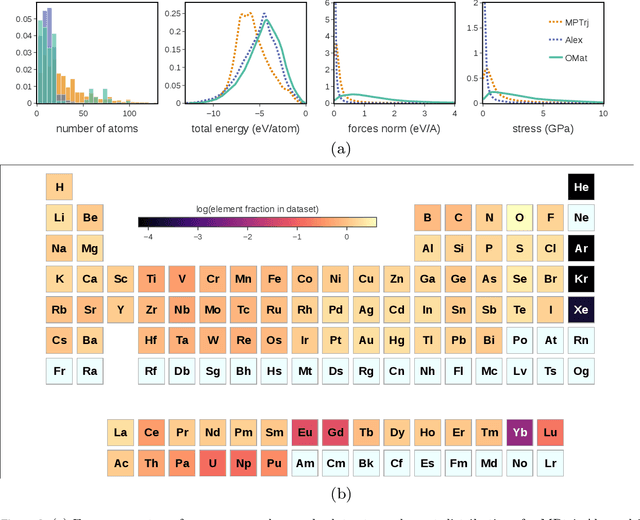
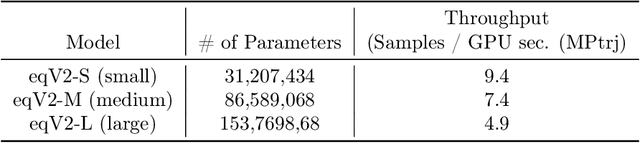
The ability to discover new materials with desirable properties is critical for numerous applications from helping mitigate climate change to advances in next generation computing hardware. AI has the potential to accelerate materials discovery and design by more effectively exploring the chemical space compared to other computational methods or by trial-and-error. While substantial progress has been made on AI for materials data, benchmarks, and models, a barrier that has emerged is the lack of publicly available training data and open pre-trained models. To address this, we present a Meta FAIR release of the Open Materials 2024 (OMat24) large-scale open dataset and an accompanying set of pre-trained models. OMat24 contains over 110 million density functional theory (DFT) calculations focused on structural and compositional diversity. Our EquiformerV2 models achieve state-of-the-art performance on the Matbench Discovery leaderboard and are capable of predicting ground-state stability and formation energies to an F1 score above 0.9 and an accuracy of 20 meV/atom, respectively. We explore the impact of model size, auxiliary denoising objectives, and fine-tuning on performance across a range of datasets including OMat24, MPtraj, and Alexandria. The open release of the OMat24 dataset and models enables the research community to build upon our efforts and drive further advancements in AI-assisted materials science.
Caching Content Placement and Beamforming Co-design for IRS-Aided MIMO Systems with Imperfect CSI
Oct 14, 2024When offloading links encounter deep fading and obstruction, edge caching cannot fully enhance wireless network performance and improve the QoS of edge nodes, as it fails to effectively reduce backhaul burden. The emerging technology of intelligent reflecting surfaces (IRS) compensates for this disadvantage by creating a smart and reconfigurable wireless environment. Subsequently, we jointly design content placement and active/passive beamforming to minimize network costs under imperfect channel state information (CSI) in the IRS-oriented edge caching system. This minimization problem is decomposed into two subproblems. The content placement subproblem is addressed by applying KKT optimality conditions. We then develop the alternating optimization method to resolve precoder and reflection beamforming. Specifically, we reduce transmission power by first fixing the phase shift, reducing the problem to a convex one relative to the precoder, which is solved through convex optimization. Next, we fix the precoder and resolve the resulting reflection beamforming problem using the penalty convex-concave procedure (CCP) method. Results demonstrate that our proposed method outperforms uniform caching and random phase approaches in reducing transmission power and saving network costs. Eventually, the proposed approach offers potential improvements in the caching optimization and transmission robustness of wireless communication with imperfect CSI.
Long-lead forecasts of wintertime air stagnation index in southern China using oceanic memory effects
May 16, 2023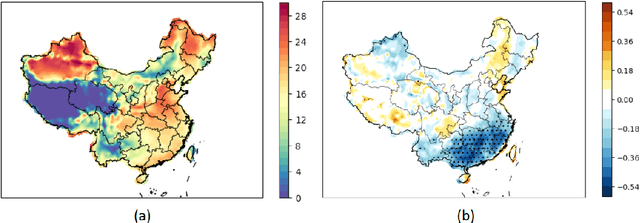
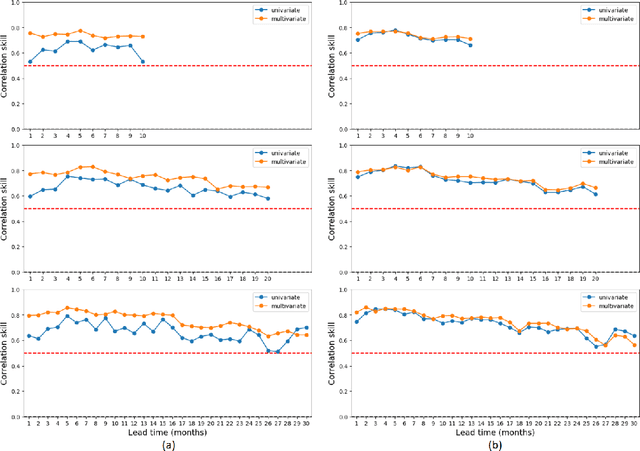
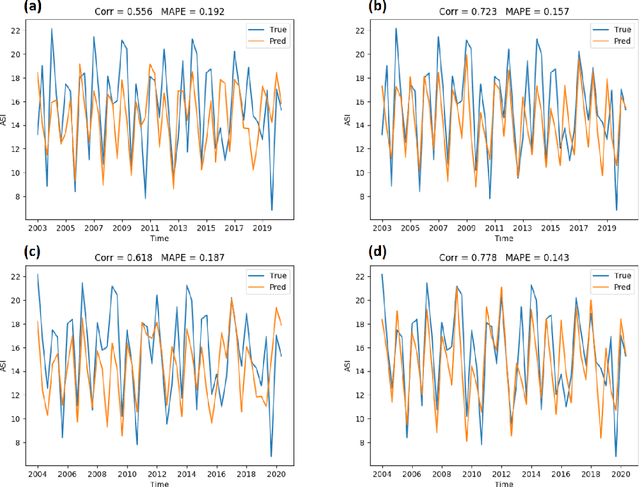
Stagnant weather condition is one of the major contributors to air pollution as it is favorable for the formation and accumulation of pollutants. To measure the atmosphere's ability to dilute air pollutants, Air Stagnation Index (ASI) has been introduced as an important meteorological index. Therefore, making long-lead ASI forecasts is vital to make plans in advance for air quality management. In this study, we found that autumn Ni\~no indices derived from sea surface temperature (SST) anomalies show a negative correlation with wintertime ASI in southern China, offering prospects for a prewinter forecast. We developed an LSTM-based model to predict the future wintertime ASI. Results demonstrated that multivariate inputs (past ASI and Ni\~no indices) achieve better forecast performance than univariate input (only past ASI). The model achieves a correlation coefficient of 0.778 between the actual and predicted ASI, exhibiting a high degree of consistency.
Exploring Semantic Relationships for Unpaired Image Captioning
Jun 20, 2021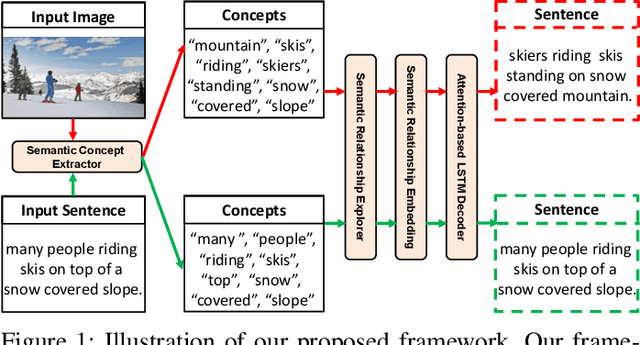
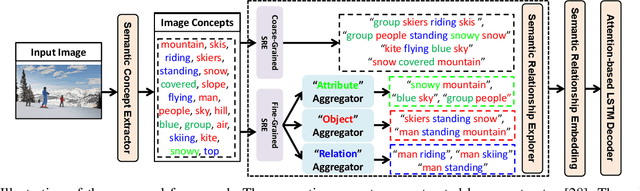
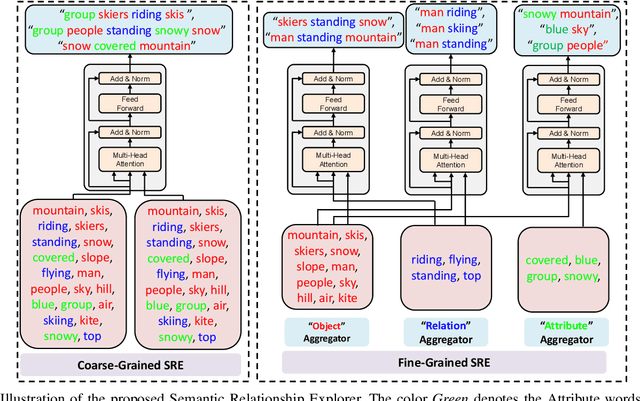

Recently, image captioning has aroused great interest in both academic and industrial worlds. Most existing systems are built upon large-scale datasets consisting of image-sentence pairs, which, however, are time-consuming to construct. In addition, even for the most advanced image captioning systems, it is still difficult to realize deep image understanding. In this work, we achieve unpaired image captioning by bridging the vision and the language domains with high-level semantic information. The motivation stems from the fact that the semantic concepts with the same modality can be extracted from both images and descriptions. To further improve the quality of captions generated by the model, we propose the Semantic Relationship Explorer, which explores the relationships between semantic concepts for better understanding of the image. Extensive experiments on MSCOCO dataset show that we can generate desirable captions without paired datasets. Furthermore, the proposed approach boosts five strong baselines under the paired setting, where the most significant improvement in CIDEr score reaches 8%, demonstrating that it is effective and generalizes well to a wide range of models.