 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Linear Recurrent Models: How Different Gating Strategies Drive Selectivity and Generalization
Jan 18, 2026Linear recurrent neural networks have emerged as efficient alternatives to the original Transformer's softmax attention mechanism, thanks to their highly parallelizable training and constant memory and computation requirements at inference. Iterative refinements of these models have introduced an increasing number of architectural mechanisms, leading to increased complexity and computational costs. Nevertheless, systematic direct comparisons among these models remain limited. Existing benchmark tasks are either too simplistic to reveal substantial differences or excessively resource-intensive for experimentation. In this work, we propose a refined taxonomy of linear recurrent models and introduce SelectivBench, a set of lightweight and customizable synthetic benchmark tasks for systematically evaluating sequence models. SelectivBench specifically evaluates selectivity in sequence models at small to medium scale, such as the capacity to focus on relevant inputs while ignoring context-based distractors. It employs rule-based grammars to generate sequences with adjustable complexity, incorporating irregular gaps that intentionally violate transition rules. Evaluations of linear recurrent models on SelectivBench reveal performance patterns consistent with results from large-scale language tasks. Our analysis clarifies the roles of essential architectural features: gating and rapid forgetting mechanisms facilitate recall, in-state channel mixing is unnecessary for selectivity, but critical for generalization, and softmax attention remains dominant due to its memory capacity scaling with sequence length. Our benchmark enables targeted, efficient exploration of linear recurrent models and provides a controlled setting for studying behaviors observed in large-scale evaluations. Code is available at https://github.com/symseqbench/selectivbench
SymSeqBench: a unified framework for the generation and analysis of rule-based symbolic sequences and datasets
Dec 31, 2025Sequential structure is a key feature of multiple domains of natural cognition and behavior, such as language, movement and decision-making. Likewise, it is also a central property of tasks to which we would like to apply artificial intelligence. It is therefore of great importance to develop frameworks that allow us to evaluate sequence learning and processing in a domain agnostic fashion, whilst simultaneously providing a link to formal theories of computation and computability. To address this need, we introduce two complementary software tools: SymSeq, designed to rigorously generate and analyze structured symbolic sequences, and SeqBench, a comprehensive benchmark suite of rule-based sequence processing tasks to evaluate the performance of artificial learning systems in cognitively relevant domains. In combination, SymSeqBench offers versatility in investigating sequential structure across diverse knowledge domains, including experimental psycholinguistics, cognitive psychology, behavioral analysis, neuromorphic computing and artificial intelligence. Due to its basis in Formal Language Theory (FLT), SymSeqBench provides researchers in multiple domains with a convenient and practical way to apply the concepts of FLT to conceptualize and standardize their experiments, thus advancing our understanding of cognition and behavior through shared computational frameworks and formalisms. The tool is modular, openly available and accessible to the research community.
QS4D: Quantization-aware training for efficient hardware deployment of structured state-space sequential models
Jul 08, 2025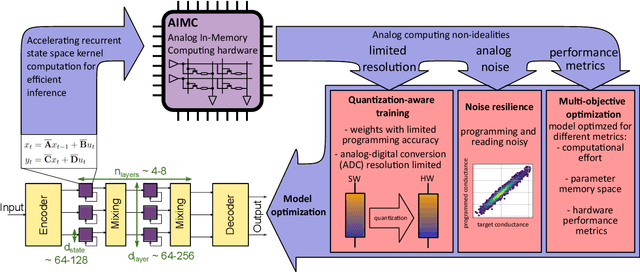
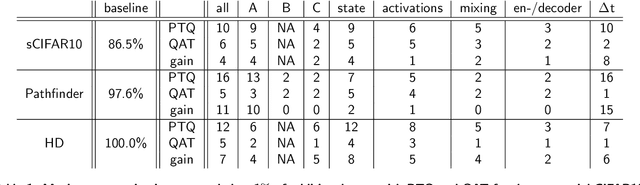
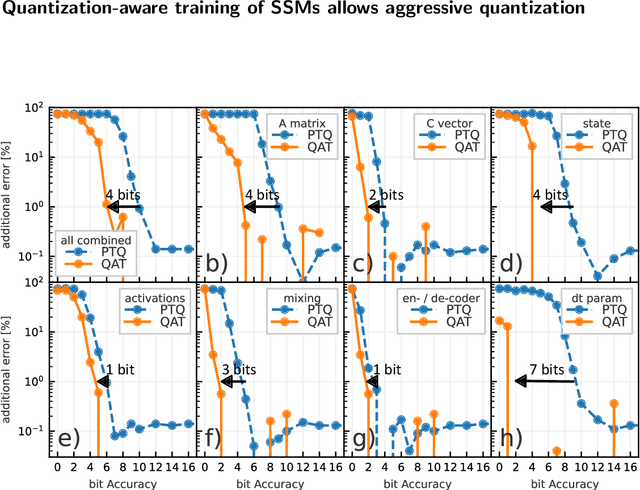
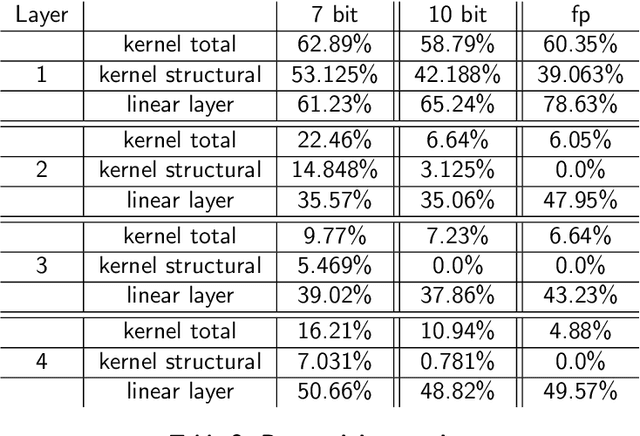
Structured State Space models (SSM) have recently emerged as a new class of deep learning models, particularly well-suited for processing long sequences. Their constant memory footprint, in contrast to the linearly scaling memory demands of Transformers, makes them attractive candidates for deployment on resource-constrained edge-computing devices. While recent works have explored the effect of quantization-aware training (QAT) on SSMs, they typically do not address its implications for specialized edge hardware, for example, analog in-memory computing (AIMC) chips. In this work, we demonstrate that QAT can significantly reduce the complexity of SSMs by up to two orders of magnitude across various performance metrics. We analyze the relation between model size and numerical precision, and show that QAT enhances robustness to analog noise and enables structural pruning. Finally, we integrate these techniques to deploy SSMs on a memristive analog in-memory computing substrate and highlight the resulting benefits in terms of computational efficiency.
Structured State Space Model Dynamics and Parametrization for Spiking Neural Networks
Jun 04, 2025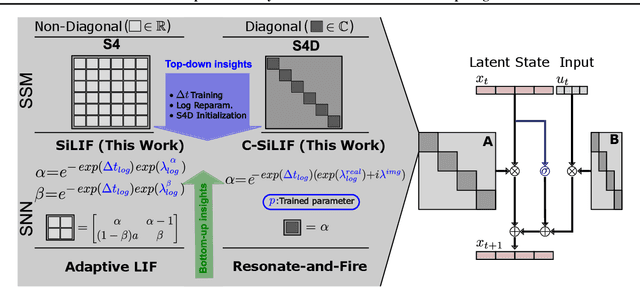
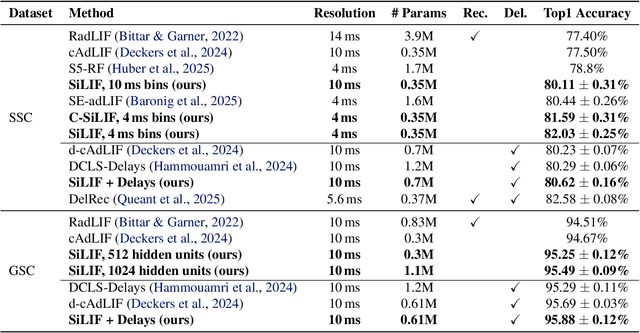
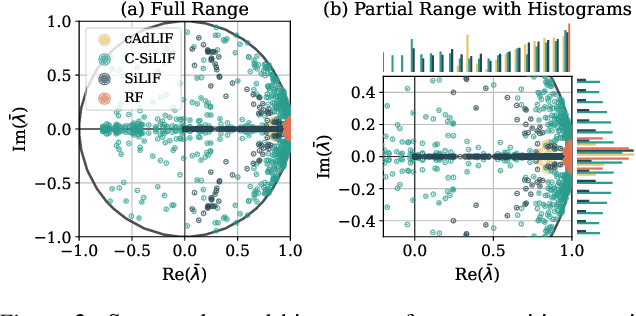

Multi-state spiking neurons such as the adaptive leaky integrate-and-fire (AdLIF) neuron offer compelling alternatives to conventional deep learning models thanks to their sparse binary activations, second-order nonlinear recurrent dynamics, and efficient hardware realizations. However, such internal dynamics can cause instabilities during inference and training, often limiting performance and scalability. Meanwhile, state space models (SSMs) excel in long sequence processing using linear state-intrinsic recurrence resembling spiking neurons' subthreshold regime. Here, we establish a mathematical bridge between SSMs and second-order spiking neuron models. Based on structure and parametrization strategies of diagonal SSMs, we propose two novel spiking neuron models. The first extends the AdLIF neuron through timestep training and logarithmic reparametrization to facilitate training and improve final performance. The second additionally brings initialization and structure from complex-state SSMs, broadening the dynamical regime to oscillatory dynamics. Together, our two models achieve beyond or near state-of-the-art (SOTA) performances for reset-based spiking neuron models across both event-based and raw audio speech recognition datasets. We achieve this with a favorable number of parameters and required dynamic memory while maintaining high activity sparsity. Our models demonstrate enhanced scalability in network size and strike a favorable balance between performance and efficiency with respect to SSM models.
Zero-Shot Temporal Resolution Domain Adaptation for Spiking Neural Networks
Nov 07, 2024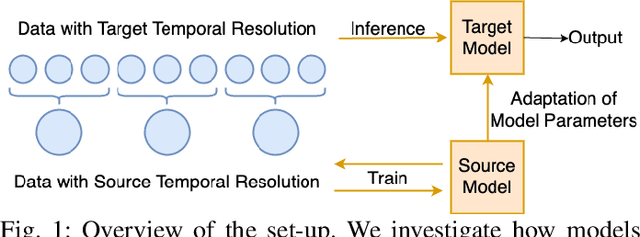
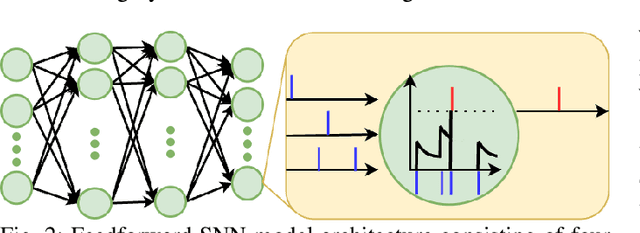


Spiking Neural Networks (SNNs) are biologically-inspired deep neural networks that efficiently extract temporal information while offering promising gains in terms of energy efficiency and latency when deployed on neuromorphic devices. However, SNN model parameters are sensitive to temporal resolution, leading to significant performance drops when the temporal resolution of target data at the edge is not the same with that of the pre-deployment source data used for training, especially when fine-tuning is not possible at the edge. To address this challenge, we propose three novel domain adaptation methods for adapting neuron parameters to account for the change in time resolution without re-training on target time-resolution. The proposed methods are based on a mapping between neuron dynamics in SNNs and State Space Models (SSMs); and are applicable to general neuron models. We evaluate the proposed methods under spatio-temporal data tasks, namely the audio keyword spotting datasets SHD and MSWC as well as the image classification NMINST dataset. Our methods provide an alternative to - and in majority of the cases significantly outperform - the existing reference method that simply scales the time constant. Moreover, our results show that high accuracy on high temporal resolution data can be obtained by time efficient training on lower temporal resolution data and model adaptation.
TEXEL: A neuromorphic processor with on-chip learning for beyond-CMOS device integration
Oct 21, 2024



Recent advances in memory technologies, devices and materials have shown great potential for integration into neuromorphic electronic systems. However, a significant gap remains between the development of these materials and the realization of large-scale, fully functional systems. One key challenge is determining which devices and materials are best suited for specific functions and how they can be paired with CMOS circuitry. To address this, we introduce TEXEL, a mixed-signal neuromorphic architecture designed to explore the integration of on-chip learning circuits and novel two- and three-terminal devices. TEXEL serves as an accessible platform to bridge the gap between CMOS-based neuromorphic computation and the latest advancements in emerging devices. In this paper, we demonstrate the readiness of TEXEL for device integration through comprehensive chip measurements and simulations. TEXEL provides a practical system for testing bio-inspired learning algorithms alongside emerging devices, establishing a tangible link between brain-inspired computation and cutting-edge device research.