 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Communication for Rate-Limited Closed-Loop Distributed Communication-Sensing-Control Systems
Dec 22, 2025



The growing integration of distributed integrated sensing and communication (ISAC) with closed-loop control in intelligent networks demands efficient information transmission under stringent bandwidth constraints. To address this challenge, this paper proposes a unified framework for goal-oriented semantic communication in distributed SCC systems. Building upon Weaver's three-level model, we establish a hierarchical semantic formulation with three error levels (L1: observation reconstruction, L2: state estimation, and L3: control) to jointly optimize their corresponding objectives. Based on this formulation, we propose a unified goal-oriented semantic compression and rate adaptation framework that is applicable to different semantic error levels and optimization goals across the SCC loop. A rate-limited multi-sensor LQR system is used as a case study to validate the proposed framework. We employ a GRU-based AE for semantic compression and a PPO-based rate adaptation algorithm that dynamically allocates transmission rates across sensors. Results show that the proposed framework effectively captures task-relevant semantics and adapts its resource allocation strategies across different semantic levels, thereby achieving level-specific performance gains under bandwidth constraints.
Low-Bit Data Processing Using Multiple-Output Spiking Neurons with Non-linear Reset Feedback
Aug 08, 2025



Neuromorphic computing is an emerging technology enabling low-latency and energy-efficient signal processing. A key algorithmic tool in neuromorphic computing is spiking neural networks (SNNs). SNNs are biologically inspired neural networks which utilize stateful neurons, and provide low-bit data processing by encoding and decoding information using spikes. Similar to SNNs, deep state-space models (SSMs) utilize stateful building blocks. However, deep SSMs, which recently achieved competitive performance in various temporal modeling tasks, are typically designed with high-precision activation functions and no reset mechanisms. To bridge the gains offered by SNNs and the recent deep SSM models, we propose a novel multiple-output spiking neuron model that combines a linear, general SSM state transition with a non-linear feedback mechanism through reset. Compared to the existing neuron models for SNNs, our proposed model clearly conceptualizes the differences between the spiking function, the reset condition and the reset action. The experimental results on various tasks, i.e., a keyword spotting task, an event-based vision task and a sequential pattern recognition task, show that our proposed model achieves performance comparable to existing benchmarks in the SNN literature. Our results illustrate how the proposed reset mechanism can overcome instability and enable learning even when the linear part of neuron dynamics is unstable, allowing us to go beyond the strictly enforced stability of linear dynamics in recent deep SSM models.
* 15 pages, 7 Tables, 6 Figures
Rate-Limited Closed-Loop Distributed ISAC Systems: An Autoencoder Approach
May 03, 2025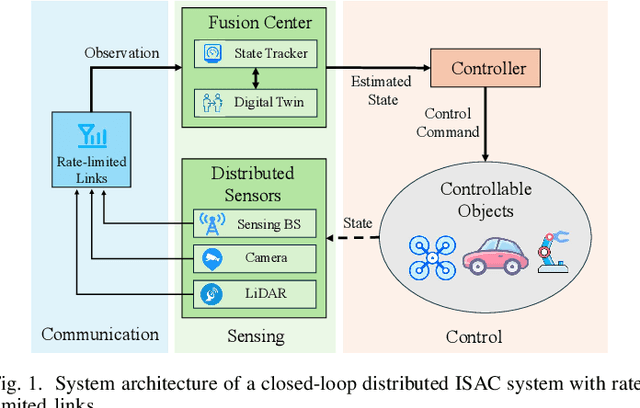
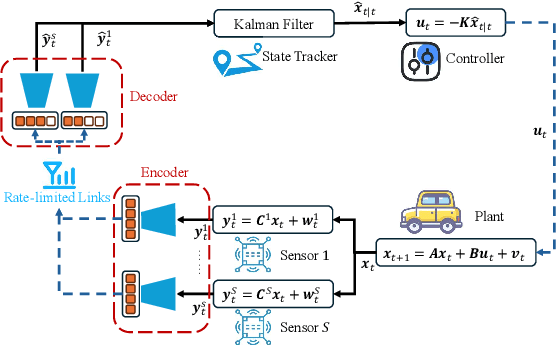
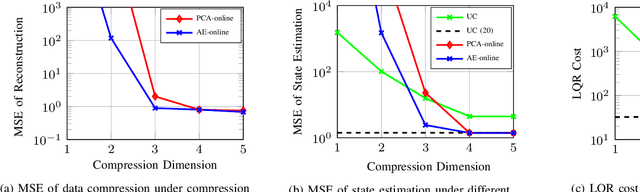
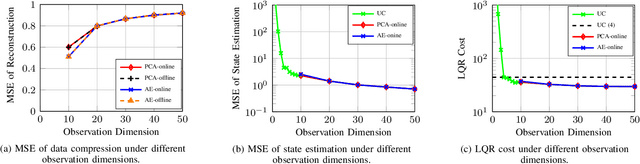
In closed-loop distributed multi-sensor integrated sensing and communication (ISAC) systems, performance often hinges on transmitting high-dimensional sensor observations over rate-limited networks. In this paper, we first present a general framework for rate-limited closed-loop distributed ISAC systems, and then propose an autoencoder-based observation compression method to overcome the constraints imposed by limited transmission capacity. Building on this framework, we conduct a case study using a closed-loop linear quadratic regulator (LQR) system to analyze how the interplay among observation, compression, and state dimensions affects reconstruction accuracy, state estimation error, and control performance. In multi-sensor scenarios, our results further show that optimal resource allocation initially prioritizes low-noise sensors until the compression becomes lossless, after which resources are reallocated to high-noise sensors.
State-Space Model Inspired Multiple-Input Multiple-Output Spiking Neurons
Apr 03, 2025
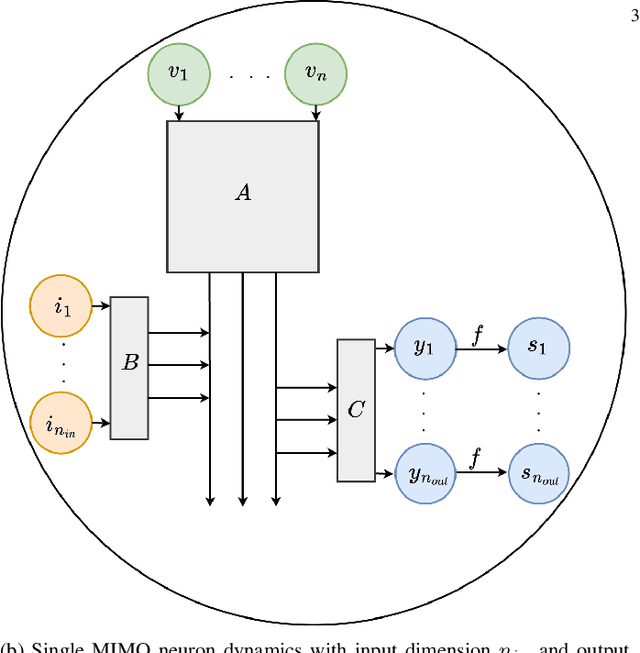


In spiking neural networks (SNNs), the main unit of information processing is the neuron with an internal state. The internal state generates an output spike based on its component associated with the membrane potential. This spike is then communicated to other neurons in the network. Here, we propose a general multiple-input multiple-output (MIMO) spiking neuron model that goes beyond this traditional single-input single-output (SISO) model in the SNN literature. Our proposed framework is based on interpreting the neurons as state-space models (SSMs) with linear state evolutions and non-linear spiking activation functions. We illustrate the trade-offs among various parameters of the proposed SSM-inspired neuron model, such as the number of hidden neuron states, the number of input and output channels, including single-input multiple-output (SIMO) and multiple-input single-output (MISO) models. We show that for SNNs with a small number of neurons with large internal state spaces, significant performance gains may be obtained by increasing the number of output channels of a neuron. In particular, a network with spiking neurons with multiple-output channels may achieve the same level of accuracy with the baseline with the continuous-valued communications on the same reference network architecture.
* 9 pages, 3 figures, 6 tables, conference - 2025 Neuro Inspired Computational Elements (NICE)
Zero-Shot Temporal Resolution Domain Adaptation for Spiking Neural Networks
Nov 07, 2024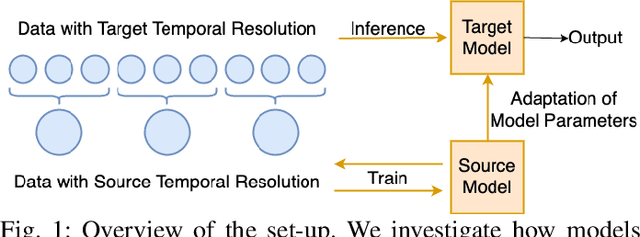


Spiking Neural Networks (SNNs) are biologically-inspired deep neural networks that efficiently extract temporal information while offering promising gains in terms of energy efficiency and latency when deployed on neuromorphic devices. However, SNN model parameters are sensitive to temporal resolution, leading to significant performance drops when the temporal resolution of target data at the edge is not the same with that of the pre-deployment source data used for training, especially when fine-tuning is not possible at the edge. To address this challenge, we propose three novel domain adaptation methods for adapting neuron parameters to account for the change in time resolution without re-training on target time-resolution. The proposed methods are based on a mapping between neuron dynamics in SNNs and State Space Models (SSMs); and are applicable to general neuron models. We evaluate the proposed methods under spatio-temporal data tasks, namely the audio keyword spotting datasets SHD and MSWC as well as the image classification NMINST dataset. Our methods provide an alternative to - and in majority of the cases significantly outperform - the existing reference method that simply scales the time constant. Moreover, our results show that high accuracy on high temporal resolution data can be obtained by time efficient training on lower temporal resolution data and model adaptation.
Distributed Continual Learning with CoCoA in High-dimensional Linear Regression
Dec 04, 2023



We consider estimation under scenarios where the signals of interest exhibit change of characteristics over time. In particular, we consider the continual learning problem where different tasks, e.g., data with different distributions, arrive sequentially and the aim is to perform well on the newly arrived task without performance degradation on the previously seen tasks. In contrast to the continual learning literature focusing on the centralized setting, we investigate the problem from a distributed estimation perspective. We consider the well-established distributed learning algorithm COCOA, which distributes the model parameters and the corresponding features over the network. We provide exact analytical characterization for the generalization error of COCOA under continual learning for linear regression in a range of scenarios, where overparameterization is of particular interest. These analytical results characterize how the generalization error depends on the network structure, the task similarity and the number of tasks, and show how these dependencies are intertwined. In particular, our results show that the generalization error can be significantly reduced by adjusting the network size, where the most favorable network size depends on task similarity and the number of tasks. We present numerical results verifying the theoretical analysis and illustrate the continual learning performance of COCOA with a digit classification task.
Continual Learning with Distributed Optimization: Does CoCoA Forget?
Dec 22, 2022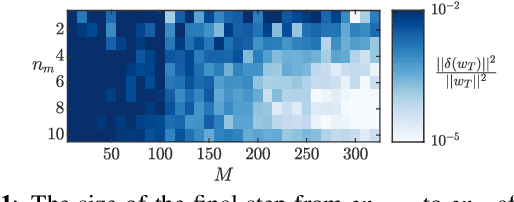
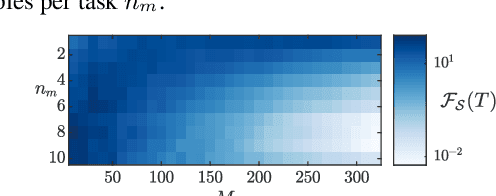
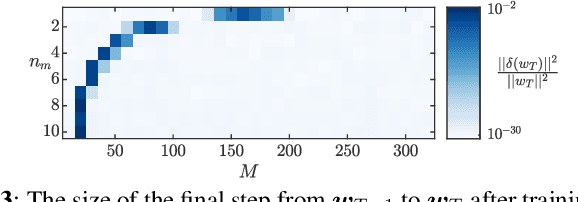
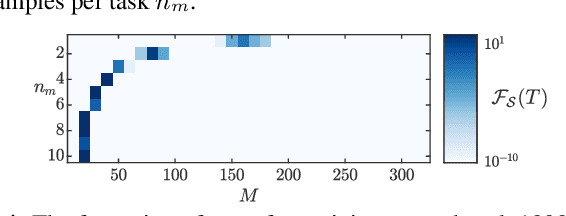
We focus on the continual learning problem where the tasks arrive sequentially and the aim is to perform well on the newly arrived task without performance degradation on the previously seen tasks. In contrast to the continual learning literature focusing on the centralized setting, we investigate the distributed estimation framework. We consider the well-established distributed learning algorithm CoCoA. We derive closed form expressions for the iterations for the overparametrized case. We illustrate the convergence and the error performance of the algorithm based on the over/under-parametrization of the problem. Our results show that depending on the problem dimensions and data generation assumptions, CoCoA can perform continual learning over a sequence of tasks, i.e., it can learn a new task without forgetting previously learned tasks, with access only to one task at a time.
Regularization with Fake Features
Dec 01, 2022

Recent successes of massively overparameterized models have inspired a new line of work investigating the underlying conditions that enable overparameterized models to generalize well. This paper considers a framework where the possibly overparametrized model includes fake features, i.e., features that are present in the model but not in the data. We present a non-asymptotic high-probability bound on the generalization error of the ridge regression problem under the model misspecification of having fake features. Our high-probability results characterize the interplay between the implicit regularization provided by the fake features and the explicit regularization provided by the ridge parameter. We observe that fake features may improve the generalization error, even though they are irrelevant to the data.
Estimation and Model Misspecification: Fake and Missing Features
Mar 07, 2022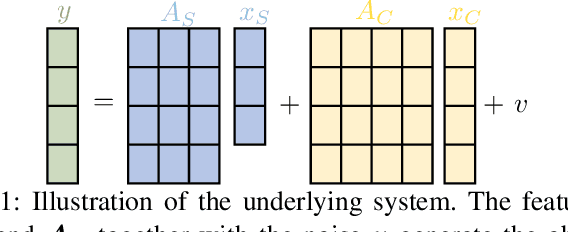
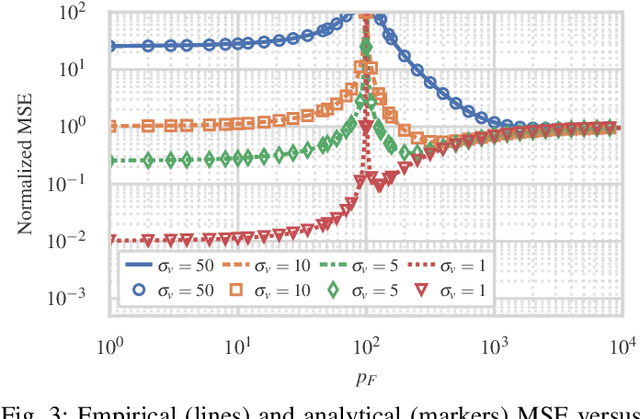
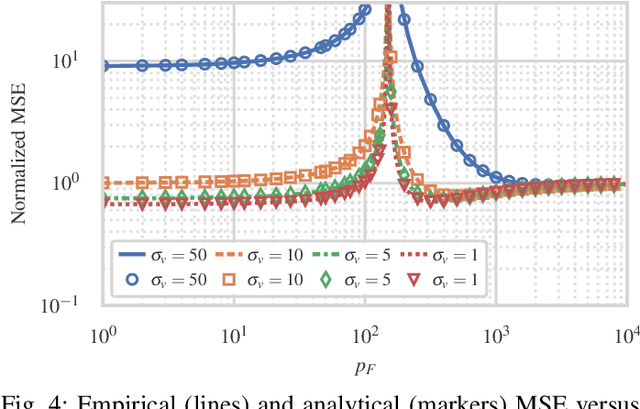

We consider estimation under model misspecification where there is a model mismatch between the underlying system, which generates the data, and the model used during estimation. We propose a model misspecification framework which enables a joint treatment of the model misspecification types of having fake and missing features, as well as incorrect covariance assumptions on the unknowns and the noise. Here, features which are included in the model but are not present in the underlying system, and features which are not included in the model but are present in the underlying system, are referred to as fake and missing features, respectively. Under this framework, we characterize the estimation performance and reveal trade-offs between the missing and fake features and the possibly incorrect noise level assumption. In contrast to existing work focusing on incorrect covariance assumptions or missing features, fake features is a central component of our framework. Our results show that fake features can significantly improve the estimation performance, even though they are not correlated with the features in the underlying system. In particular, we show that the estimation error can be decreased by including more fake features in the model, even to the point where the model is overparametrized, i.e., the model contains more unknowns than observations.
Model Mismatch Trade-offs in LMMSE Estimation
May 25, 2021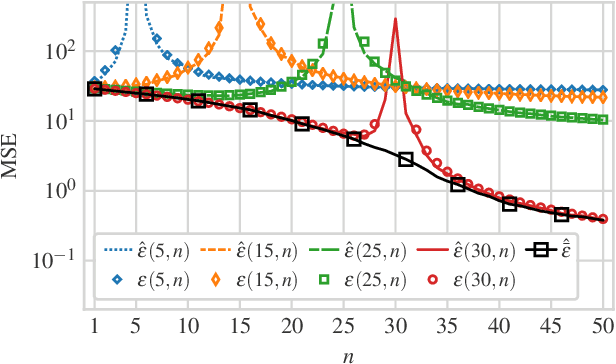
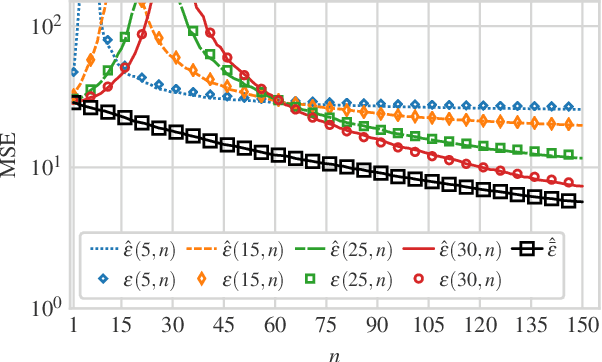
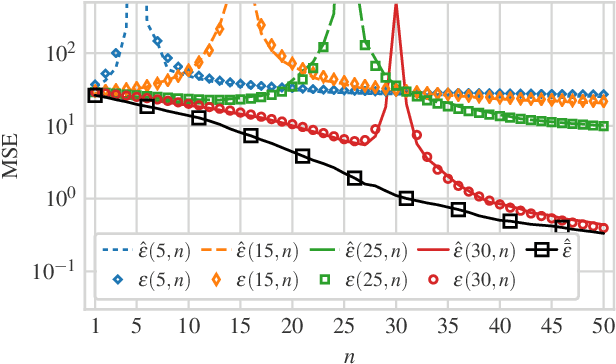
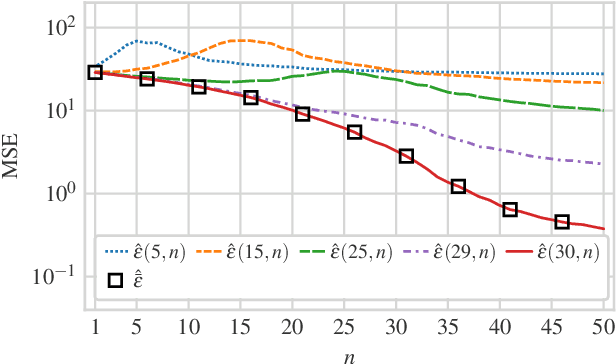
We consider a linear minimum mean squared error (LMMSE) estimation framework with model mismatch where the assumed model order is smaller than that of the underlying linear system which generates the data used in the estimation process. By modelling the regressors of the underlying system as random variables, we analyze the average behaviour of the mean squared error (MSE). Our results quantify how the MSE depends on the interplay between the number of samples and the number of parameters in the underlying system and in the assumed model. In particular, if the number of samples is not sufficiently large, neither increasing the number of samples nor the assumed model complexity is sufficient to guarantee a performance improvement.