 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Continual Learning with CoCoA in High-dimensional Linear Regression
Dec 04, 2023



We consider estimation under scenarios where the signals of interest exhibit change of characteristics over time. In particular, we consider the continual learning problem where different tasks, e.g., data with different distributions, arrive sequentially and the aim is to perform well on the newly arrived task without performance degradation on the previously seen tasks. In contrast to the continual learning literature focusing on the centralized setting, we investigate the problem from a distributed estimation perspective. We consider the well-established distributed learning algorithm COCOA, which distributes the model parameters and the corresponding features over the network. We provide exact analytical characterization for the generalization error of COCOA under continual learning for linear regression in a range of scenarios, where overparameterization is of particular interest. These analytical results characterize how the generalization error depends on the network structure, the task similarity and the number of tasks, and show how these dependencies are intertwined. In particular, our results show that the generalization error can be significantly reduced by adjusting the network size, where the most favorable network size depends on task similarity and the number of tasks. We present numerical results verifying the theoretical analysis and illustrate the continual learning performance of COCOA with a digit classification task.
Continual Learning with Distributed Optimization: Does CoCoA Forget?
Dec 22, 2022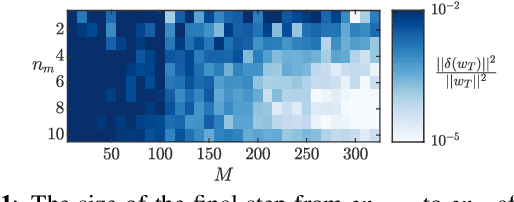
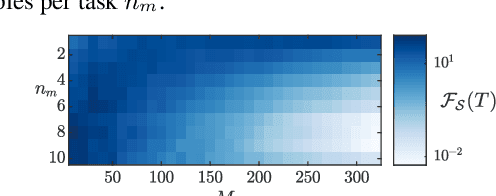
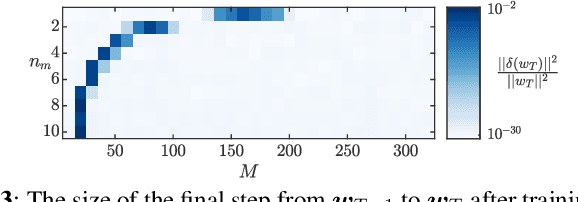
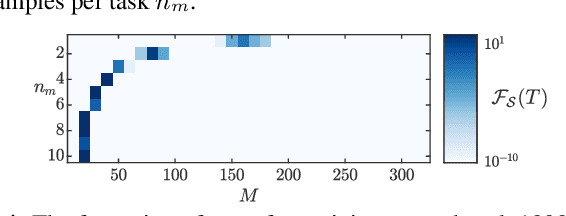
We focus on the continual learning problem where the tasks arrive sequentially and the aim is to perform well on the newly arrived task without performance degradation on the previously seen tasks. In contrast to the continual learning literature focusing on the centralized setting, we investigate the distributed estimation framework. We consider the well-established distributed learning algorithm CoCoA. We derive closed form expressions for the iterations for the overparametrized case. We illustrate the convergence and the error performance of the algorithm based on the over/under-parametrization of the problem. Our results show that depending on the problem dimensions and data generation assumptions, CoCoA can perform continual learning over a sequence of tasks, i.e., it can learn a new task without forgetting previously learned tasks, with access only to one task at a time.
Regularization with Fake Features
Dec 01, 2022

Recent successes of massively overparameterized models have inspired a new line of work investigating the underlying conditions that enable overparameterized models to generalize well. This paper considers a framework where the possibly overparametrized model includes fake features, i.e., features that are present in the model but not in the data. We present a non-asymptotic high-probability bound on the generalization error of the ridge regression problem under the model misspecification of having fake features. Our high-probability results characterize the interplay between the implicit regularization provided by the fake features and the explicit regularization provided by the ridge parameter. We observe that fake features may improve the generalization error, even though they are irrelevant to the data.
Estimation and Model Misspecification: Fake and Missing Features
Mar 07, 2022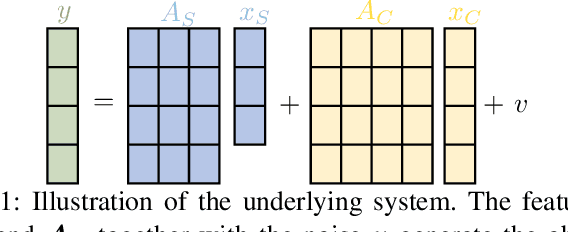
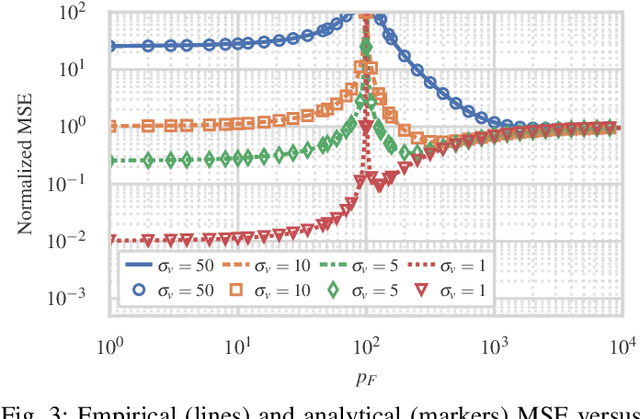
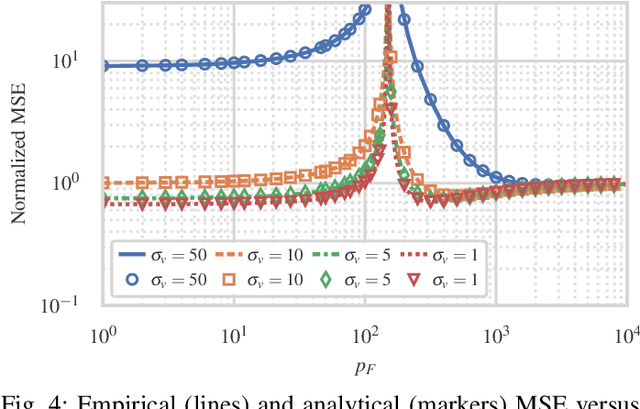

We consider estimation under model misspecification where there is a model mismatch between the underlying system, which generates the data, and the model used during estimation. We propose a model misspecification framework which enables a joint treatment of the model misspecification types of having fake and missing features, as well as incorrect covariance assumptions on the unknowns and the noise. Here, features which are included in the model but are not present in the underlying system, and features which are not included in the model but are present in the underlying system, are referred to as fake and missing features, respectively. Under this framework, we characterize the estimation performance and reveal trade-offs between the missing and fake features and the possibly incorrect noise level assumption. In contrast to existing work focusing on incorrect covariance assumptions or missing features, fake features is a central component of our framework. Our results show that fake features can significantly improve the estimation performance, even though they are not correlated with the features in the underlying system. In particular, we show that the estimation error can be decreased by including more fake features in the model, even to the point where the model is overparametrized, i.e., the model contains more unknowns than observations.
Linear Regression with Distributed Learning: A Generalization Error Perspective
Jan 22, 2021



Distributed learning provides an attractive framework for scaling the learning task by sharing the computational load over multiple nodes in a network. Here, we investigate the performance of distributed learning for large-scale linear regression where the model parameters, i.e., the unknowns, are distributed over the network. We adopt a statistical learning approach. In contrast to works that focus on the performance on the training data, we focus on the generalization error, i.e., the performance on unseen data. We provide high-probability bounds on the generalization error for both isotropic and correlated Gaussian data as well as sub-gaussian data. These results reveal the dependence of the generalization performance on the partitioning of the model over the network. In particular, our results show that the generalization error of the distributed solution can be substantially higher than that of the centralized solution even when the error on the training data is at the same level for both the centralized and distributed approaches. Our numerical results illustrate the performance with both real-world image data as well as synthetic data.
Generalization Error for Linear Regression under Distributed Learning
May 04, 2020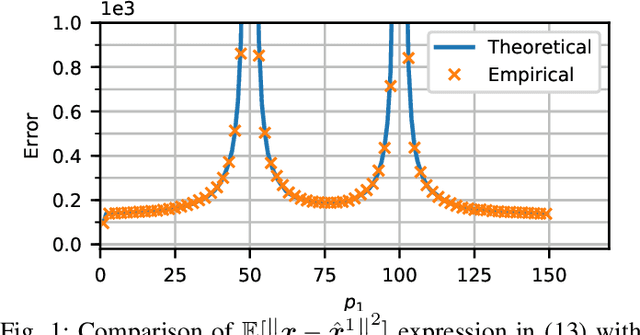
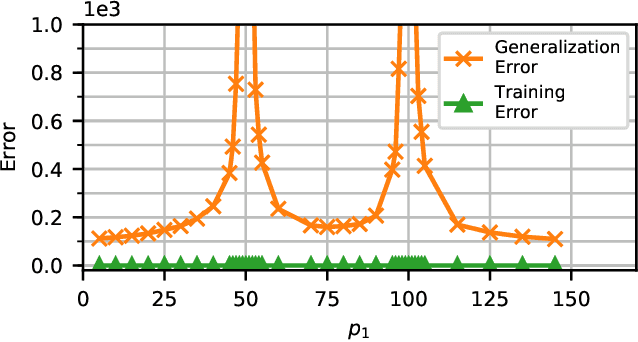
Distributed learning facilitates the scaling-up of data processing by distributing the computational burden over several nodes. Despite the vast interest in distributed learning, generalization performance of such approaches is not well understood. We address this gap by focusing on a linear regression setting. We consider the setting where the unknowns are distributed over a network of nodes. We present an analytical characterization of the dependence of the generalization error on the partitioning of the unknowns over nodes. In particular, for the overparameterized case, our results show that while the error on training data remains in the same range as that of the centralized solution, the generalization error of the distributed solution increases dramatically compared to that of the centralized solution when the number of unknowns estimated at any node is close to the number of observations. We further provide numerical examples to verify our analytical expressions.