 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Convergence Analysis of Network-GIANT: An approximate Hessian-based fully distributed optimization algorithm
Feb 16, 2026In this paper, we present a detailed convergence analysis of a recently developed approximate Newton-type fully distributed optimization method for smooth, strongly convex local loss functions, called Network-GIANT, which has been empirically illustrated to show faster linear convergence properties while having the same communication complexity (per iteration) as its first order distributed counterparts. By using consensus based parameter updates, and a local Hessian based descent direction at the individual nodes with gradient tracking, we first explicitly characterize a global linear convergence rate for Network-GIANT, which can be computed as the spectral radius of a $3 \times 3$ matrix dependent on the Lipschitz continuity ($L$) and strong convexity ($μ$) parameters of the objective functions, and the spectral norm ($σ$) of the underlying undirected graph represented by a doubly stochastic consensus matrix. We provide an explicit bound on the step size parameter $η$, below which this spectral radius is guaranteed to be less than $1$. Furthermore, we derive a mixed linear-quadratic inequality based upper bound for the optimality gap norm, which allows us to conclude that, under small step size values, asymptotically, as the algorithm approaches the global optimum, it achieves a locally linear convergence rate of $1-η(1 -\fracγμ)$ for Network-GIANT, provided the Hessian approximation error $γ$ (between the harmonic mean of the local Hessians and the global hessian (the arithmetic mean of the local Hessians) is smaller than $μ$. This asymptotically linear convergence rate of $\approx 1-η$ explains the faster convergence rate of Network-GIANT for the first time. Numerical experiments are carried out with a reduced CovType dataset for binary logistic regression over a variety of graphs to illustrate the above theoretical results.
VR-VFL: Joint Rate and Client Selection for Vehicular Federated Learning Under Imperfect CSI
Feb 03, 2026Federated learning in vehicular edge networks faces major challenges in efficient resource allocation, largely due to high vehicle mobility and the presence of imperfect channel state information. Many existing methods oversimplify these realities, often assuming fixed communication rounds or ideal channel conditions, which limits their effectiveness in real-world scenarios. To address this, we propose variable rate vehicular federated learning (VR-VFL), a novel federated learning method designed specifically for vehicular networks under imperfect channel state information. VR-VFL combines dynamic client selection with adaptive transmission rate selection, while also allowing round times to flex in response to changing wireless conditions. At its core, VR-VFL is built on a bi-objective optimization framework that strikes a balance between improving learning convergence and minimizing the time required to complete each round. By accounting for both the challenges of mobility and realistic wireless constraints, VR-VFL offers a more practical and efficient approach to federated learning in vehicular edge networks. Simulation results show that the proposed VR-VFL scheme achieves convergence approximately 40% faster than other methods in the literature.
HBNET-GIANT: A communication-efficient accelerated Newton-type fully distributed optimization algorithm
Nov 17, 2025This article presents a second-order fully distributed optimization algorithm, HBNET-GIANT, driven by heavy-ball momentum, for $L$-smooth and $μ$-strongly convex objective functions. A rigorous convergence analysis is performed, and we demonstrate global linear convergence under certain sufficient conditions. Through extensive numerical experiments, we show that HBNET-GIANT with heavy-ball momentum achieves acceleration, and the corresponding rate of convergence is strictly faster than its non-accelerated version, NETWORK-GIANT. Moreover, we compare HBNET-GIANT with several state-of-the-art algorithms, both momentum-based and without momentum, and report significant performance improvement in convergence to the optimum. We believe that this work lays the groundwork for a broader class of second-order Newton-type algorithms with momentum and motivates further investigation into open problems, including an analytical proof of local acceleration in the fully distributed setting for convex optimization problems.
Low-Bit Data Processing Using Multiple-Output Spiking Neurons with Non-linear Reset Feedback
Aug 08, 2025



Neuromorphic computing is an emerging technology enabling low-latency and energy-efficient signal processing. A key algorithmic tool in neuromorphic computing is spiking neural networks (SNNs). SNNs are biologically inspired neural networks which utilize stateful neurons, and provide low-bit data processing by encoding and decoding information using spikes. Similar to SNNs, deep state-space models (SSMs) utilize stateful building blocks. However, deep SSMs, which recently achieved competitive performance in various temporal modeling tasks, are typically designed with high-precision activation functions and no reset mechanisms. To bridge the gains offered by SNNs and the recent deep SSM models, we propose a novel multiple-output spiking neuron model that combines a linear, general SSM state transition with a non-linear feedback mechanism through reset. Compared to the existing neuron models for SNNs, our proposed model clearly conceptualizes the differences between the spiking function, the reset condition and the reset action. The experimental results on various tasks, i.e., a keyword spotting task, an event-based vision task and a sequential pattern recognition task, show that our proposed model achieves performance comparable to existing benchmarks in the SNN literature. Our results illustrate how the proposed reset mechanism can overcome instability and enable learning even when the linear part of neuron dynamics is unstable, allowing us to go beyond the strictly enforced stability of linear dynamics in recent deep SSM models.
* 15 pages, 7 Tables, 6 Figures
State-Space Model Inspired Multiple-Input Multiple-Output Spiking Neurons
Apr 03, 2025
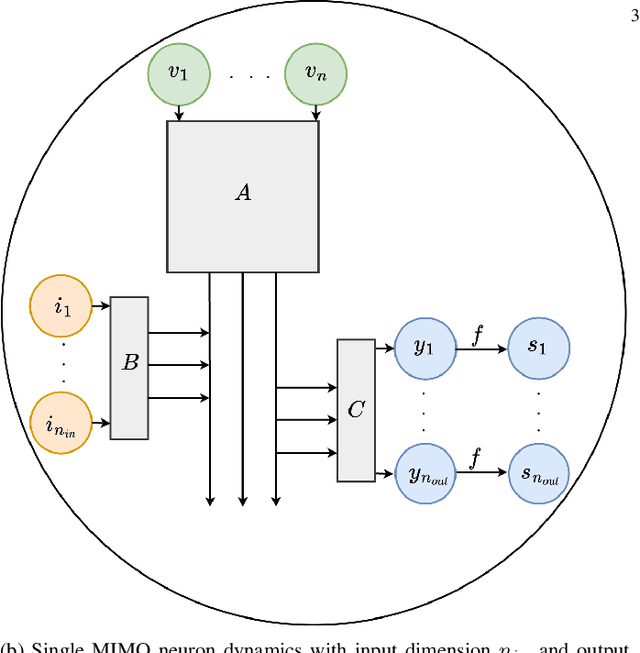


In spiking neural networks (SNNs), the main unit of information processing is the neuron with an internal state. The internal state generates an output spike based on its component associated with the membrane potential. This spike is then communicated to other neurons in the network. Here, we propose a general multiple-input multiple-output (MIMO) spiking neuron model that goes beyond this traditional single-input single-output (SISO) model in the SNN literature. Our proposed framework is based on interpreting the neurons as state-space models (SSMs) with linear state evolutions and non-linear spiking activation functions. We illustrate the trade-offs among various parameters of the proposed SSM-inspired neuron model, such as the number of hidden neuron states, the number of input and output channels, including single-input multiple-output (SIMO) and multiple-input single-output (MISO) models. We show that for SNNs with a small number of neurons with large internal state spaces, significant performance gains may be obtained by increasing the number of output channels of a neuron. In particular, a network with spiking neurons with multiple-output channels may achieve the same level of accuracy with the baseline with the continuous-valued communications on the same reference network architecture.
* 9 pages, 3 figures, 6 tables, conference - 2025 Neuro Inspired Computational Elements (NICE)
Distributed Average Consensus via Noisy and Non-Coherent Over-the-Air Aggregation
Mar 11, 2024
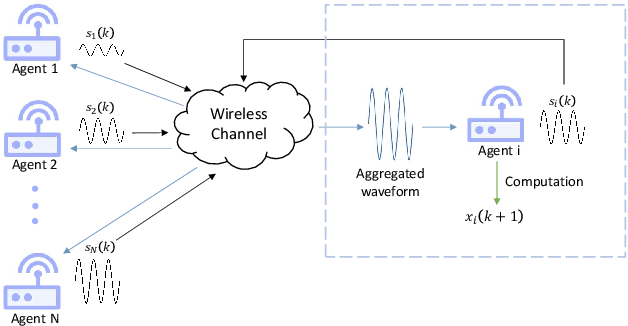
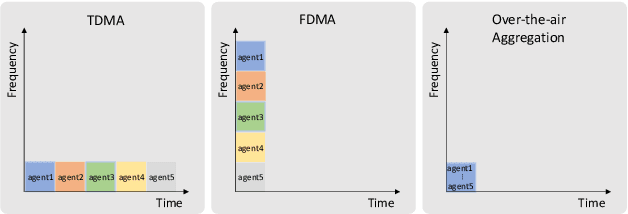
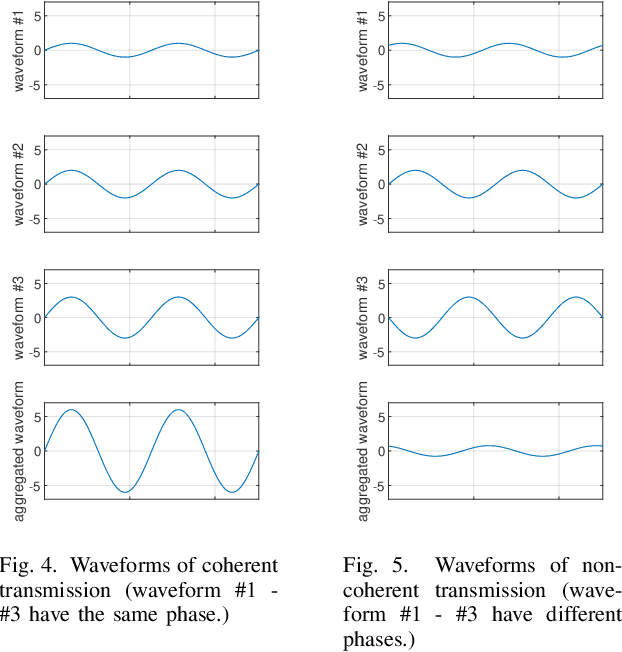
Over-the-air aggregation has attracted widespread attention for its potential advantages in task-oriented applications, such as distributed sensing, learning, and consensus. In this paper, we develop a communication-efficient distributed average consensus protocol by utilizing over-the-air aggregation, which exploits the superposition property of wireless channels rather than combat it. Noisy channels and non-coherent transmission are taken into account, and only half-duplex transceivers are required. We prove that the system can achieve average consensus in mean square and even almost surely under the proposed protocol. Furthermore, we extend the analysis to the scenarios with time-varying topology. Numerical simulation shows the effectiveness of the proposed protocol.
Over-the-air Federated Policy Gradient
Oct 25, 2023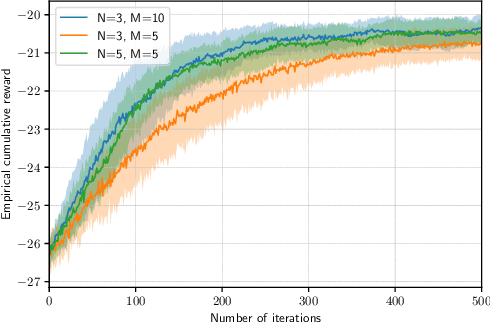
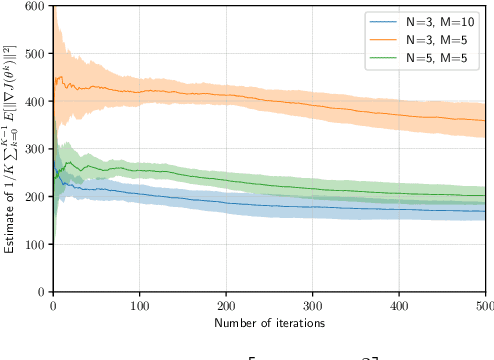
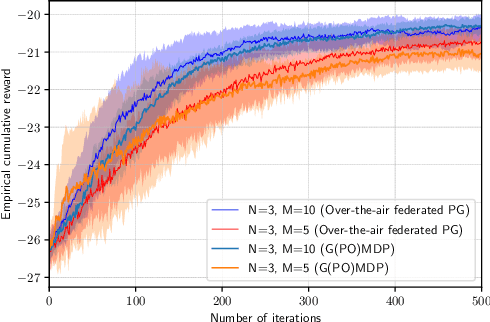
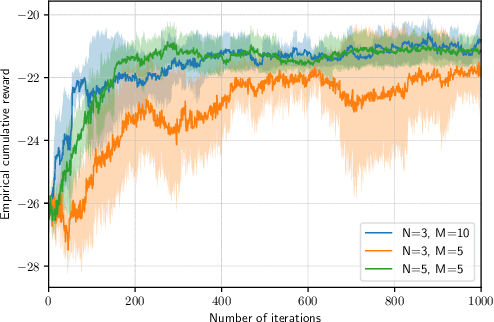
In recent years, over-the-air aggregation has been widely considered in large-scale distributed learning, optimization, and sensing. In this paper, we propose the over-the-air federated policy gradient algorithm, where all agents simultaneously broadcast an analog signal carrying local information to a common wireless channel, and a central controller uses the received aggregated waveform to update the policy parameters. We investigate the effect of noise and channel distortion on the convergence of the proposed algorithm, and establish the complexities of communication and sampling for finding an $\epsilon$-approximate stationary point. Finally, we present some simulation results to show the effectiveness of the algorithm.
FedZeN: Towards superlinear zeroth-order federated learning via incremental Hessian estimation
Sep 29, 2023Federated learning is a distributed learning framework that allows a set of clients to collaboratively train a model under the orchestration of a central server, without sharing raw data samples. Although in many practical scenarios the derivatives of the objective function are not available, only few works have considered the federated zeroth-order setting, in which functions can only be accessed through a budgeted number of point evaluations. In this work we focus on convex optimization and design the first federated zeroth-order algorithm to estimate the curvature of the global objective, with the purpose of achieving superlinear convergence. We take an incremental Hessian estimator whose error norm converges linearly, and we adapt it to the federated zeroth-order setting, sampling the random search directions from the Stiefel manifold for improved performance. In particular, both the gradient and Hessian estimators are built at the central server in a communication-efficient and privacy-preserving way by leveraging synchronized pseudo-random number generators. We provide a theoretical analysis of our algorithm, named FedZeN, proving local quadratic convergence with high probability and global linear convergence up to zeroth-order precision. Numerical simulations confirm the superlinear convergence rate and show that our algorithm outperforms the federated zeroth-order methods available in the literature.
Q-SHED: Distributed Optimization at the Edge via Hessian Eigenvectors Quantization
May 18, 2023

Edge networks call for communication efficient (low overhead) and robust distributed optimization (DO) algorithms. These are, in fact, desirable qualities for DO frameworks, such as federated edge learning techniques, in the presence of data and system heterogeneity, and in scenarios where internode communication is the main bottleneck. Although computationally demanding, Newton-type (NT) methods have been recently advocated as enablers of robust convergence rates in challenging DO problems where edge devices have sufficient computational power. Along these lines, in this work we propose Q-SHED, an original NT algorithm for DO featuring a novel bit-allocation scheme based on incremental Hessian eigenvectors quantization. The proposed technique is integrated with the recent SHED algorithm, from which it inherits appealing features like the small number of required Hessian computations, while being bandwidth-versatile at a bit-resolution level. Our empirical evaluation against competing approaches shows that Q-SHED can reduce by up to 60% the number of communication rounds required for convergence.
Network-GIANT: Fully distributed Newton-type optimization via harmonic Hessian consensus
May 13, 2023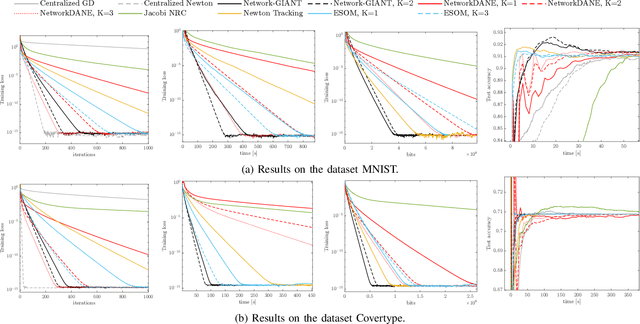
This paper considers the problem of distributed multi-agent learning, where the global aim is to minimize a sum of local objective (empirical loss) functions through local optimization and information exchange between neighbouring nodes. We introduce a Newton-type fully distributed optimization algorithm, Network-GIANT, which is based on GIANT, a Federated learning algorithm that relies on a centralized parameter server. The Network-GIANT algorithm is designed via a combination of gradient-tracking and a Newton-type iterative algorithm at each node with consensus based averaging of local gradient and Newton updates. We prove that our algorithm guarantees semi-global and exponential convergence to the exact solution over the network assuming strongly convex and smooth loss functions. We provide empirical evidence of the superior convergence performance of Network-GIANT over other state-of-art distributed learning algorithms such as Network-DANE and Newton-Raphson Consensus.