 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedZeN: Towards superlinear zeroth-order federated learning via incremental Hessian estimation
Sep 29, 2023Federated learning is a distributed learning framework that allows a set of clients to collaboratively train a model under the orchestration of a central server, without sharing raw data samples. Although in many practical scenarios the derivatives of the objective function are not available, only few works have considered the federated zeroth-order setting, in which functions can only be accessed through a budgeted number of point evaluations. In this work we focus on convex optimization and design the first federated zeroth-order algorithm to estimate the curvature of the global objective, with the purpose of achieving superlinear convergence. We take an incremental Hessian estimator whose error norm converges linearly, and we adapt it to the federated zeroth-order setting, sampling the random search directions from the Stiefel manifold for improved performance. In particular, both the gradient and Hessian estimators are built at the central server in a communication-efficient and privacy-preserving way by leveraging synchronized pseudo-random number generators. We provide a theoretical analysis of our algorithm, named FedZeN, proving local quadratic convergence with high probability and global linear convergence up to zeroth-order precision. Numerical simulations confirm the superlinear convergence rate and show that our algorithm outperforms the federated zeroth-order methods available in the literature.
Network-GIANT: Fully distributed Newton-type optimization via harmonic Hessian consensus
May 13, 2023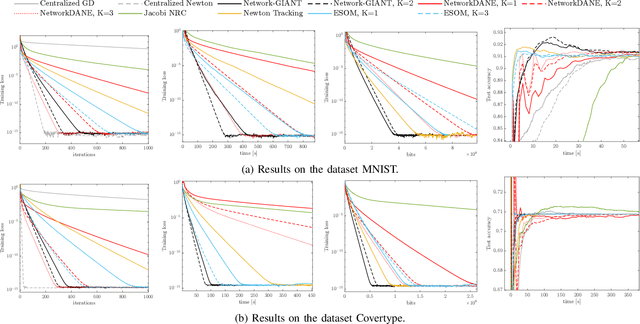
This paper considers the problem of distributed multi-agent learning, where the global aim is to minimize a sum of local objective (empirical loss) functions through local optimization and information exchange between neighbouring nodes. We introduce a Newton-type fully distributed optimization algorithm, Network-GIANT, which is based on GIANT, a Federated learning algorithm that relies on a centralized parameter server. The Network-GIANT algorithm is designed via a combination of gradient-tracking and a Newton-type iterative algorithm at each node with consensus based averaging of local gradient and Newton updates. We prove that our algorithm guarantees semi-global and exponential convergence to the exact solution over the network assuming strongly convex and smooth loss functions. We provide empirical evidence of the superior convergence performance of Network-GIANT over other state-of-art distributed learning algorithms such as Network-DANE and Newton-Raphson Consensus.