 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Communication for Optimal Distributed Learning over Unpredictable Networks
Dec 05, 2023Gradient compression alleviates expensive communication in distributed deep learning by sending fewer values and its corresponding indices, typically via Allgather (AG). Training with high compression ratio (CR) achieves high accuracy like DenseSGD, but has lower parallel scaling due to high communication cost (i.e., parallel efficiency). Using lower CRs improves parallel efficiency by lowering synchronization cost, but degrades model accuracy as well (statistical efficiency). Further, speedup attained with different models and CRs also varies with network latency, effective bandwidth and collective op used for aggregation. In many cases, collectives like Allreduce (AR) have lower cost than AG to exchange the same amount of data. In this paper, we propose an AR-compatible Topk compressor that is bandwidth-optimal and thus performs better than AG in certain network configurations. We develop a flexible communication strategy that switches between AG and AR based on which collective is optimal in the current settings, and model the pareto-relationship between parallel and statistical efficiency as a multi-objective optimization (MOO) problem to dynamically adjust CR and accelerate training while still converging to high accuracy.
Accelerating Distributed ML Training via Selective Synchronization
Jul 16, 2023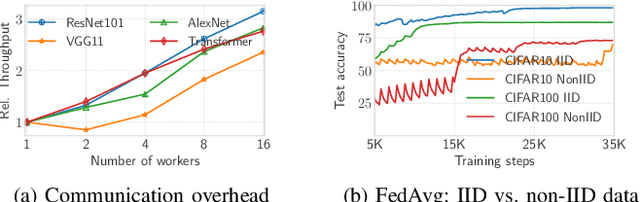

In distributed training, deep neural networks (DNNs) are launched over multiple workers concurrently and aggregate their local updates on each step in bulk-synchronous parallel (BSP) training. However, BSP does not linearly scale-out due to high communication cost of aggregation. To mitigate this overhead, alternatives like Federated Averaging (FedAvg) and Stale-Synchronous Parallel (SSP) either reduce synchronization frequency or eliminate it altogether, usually at the cost of lower final accuracy. In this paper, we present \texttt{SelSync}, a practical, low-overhead method for DNN training that dynamically chooses to incur or avoid communication at each step either by calling the aggregation op or applying local updates based on their significance. We propose various optimizations as part of \texttt{SelSync} to improve convergence in the context of \textit{semi-synchronous} training. Our system converges to the same or better accuracy than BSP while reducing training time by up to 14$\times$.
GraVAC: Adaptive Compression for Communication-Efficient Distributed DL Training
May 20, 2023


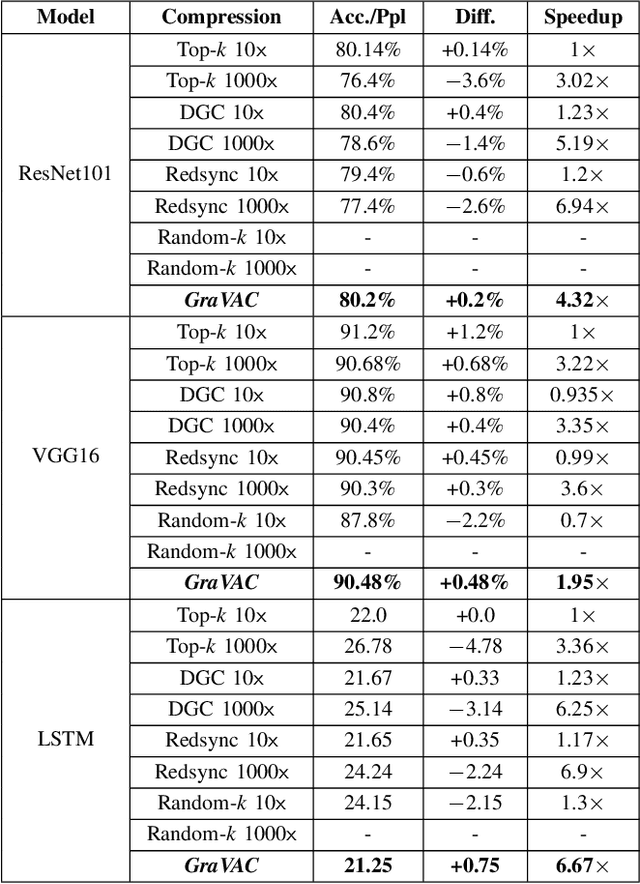
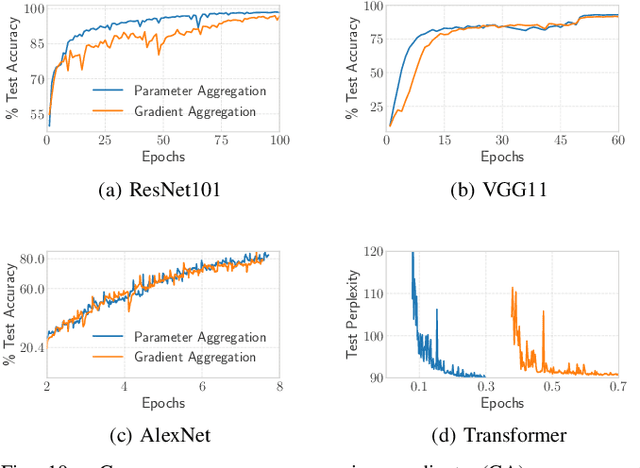
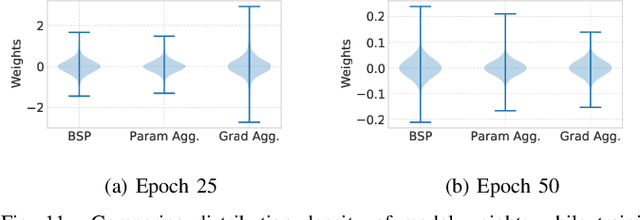
Distributed data-parallel (DDP) training improves overall application throughput as multiple devices train on a subset of data and aggregate updates to produce a globally shared model. The periodic synchronization at each iteration incurs considerable overhead, exacerbated by the increasing size and complexity of state-of-the-art neural networks. Although many gradient compression techniques propose to reduce communication cost, the ideal compression factor that leads to maximum speedup or minimum data exchange remains an open-ended problem since it varies with the quality of compression, model size and structure, hardware, network topology and bandwidth. We propose GraVAC, a framework to dynamically adjust compression factor throughout training by evaluating model progress and assessing gradient information loss associated with compression. GraVAC works in an online, black-box manner without any prior assumptions about a model or its hyperparameters, while achieving the same or better accuracy than dense SGD (i.e., no compression) in the same number of iterations/epochs. As opposed to using a static compression factor, GraVAC reduces end-to-end training time for ResNet101, VGG16 and LSTM by 4.32x, 1.95x and 6.67x respectively. Compared to other adaptive schemes, our framework provides 1.94x to 5.63x overall speedup.
QTrojan: A Circuit Backdoor Against Quantum Neural Networks
Feb 16, 2023We propose a circuit-level backdoor attack, \textit{QTrojan}, against Quantum Neural Networks (QNNs) in this paper. QTrojan is implemented by few quantum gates inserted into the variational quantum circuit of the victim QNN. QTrojan is much stealthier than a prior Data-Poisoning-based Backdoor Attack (DPBA), since it does not embed any trigger in the inputs of the victim QNN or require the access to original training datasets. Compared to a DPBA, QTrojan improves the clean data accuracy by 21\% and the attack success rate by 19.9\%.
Graph Attention Multi-Agent Fleet Autonomy for Advanced Air Mobility
Feb 16, 2023


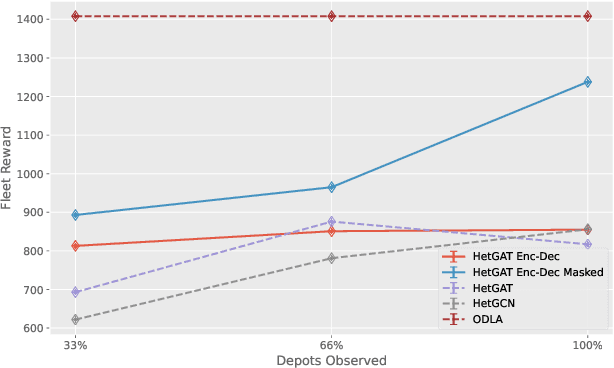
Autonomous mobility is emerging as a new mode of urban transportation for moving cargo and passengers. However, such fleet coordination schemes face significant challenges in scaling to accommodate fast-growing fleet sizes that vary in their operational range, capacity, and communication capabilities. We introduce the concept of partially observable advanced air mobility games to coordinate a fleet of aerial vehicle agents accounting for their heterogeneity and self-interest inherent to commercial mobility fleets. We propose a novel heterogeneous graph attention-based encoder-decoder (HetGAT Enc-Dec) neural network to construct a generalizable stochastic policy stemming from the inter- and intra-agent relations within the mobility system. We train our policy by leveraging deep multi-agent reinforcement learning, allowing decentralized decision-making for the agents using their local observations. Through extensive experimentation, we show that the fleets operating under the HetGAT Enc-Dec policy outperform other state-of-the-art graph neural network-based policies by achieving the highest fleet reward and fulfillment ratios in an on-demand mobility network.
ScaDLES: Scalable Deep Learning over Streaming data at the Edge
Jan 21, 2023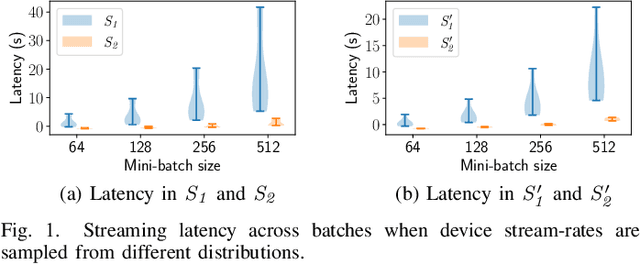
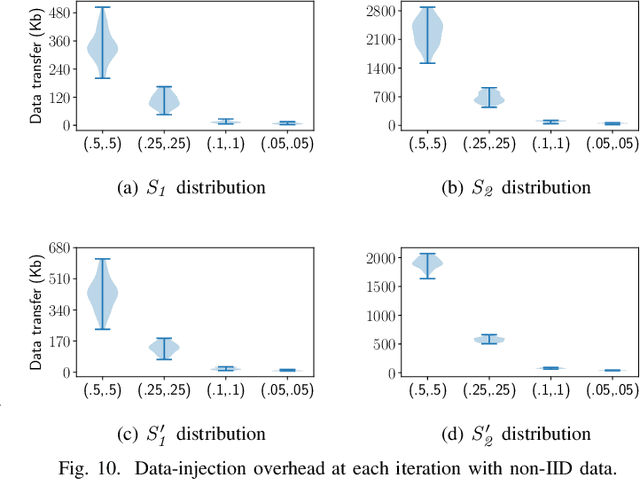
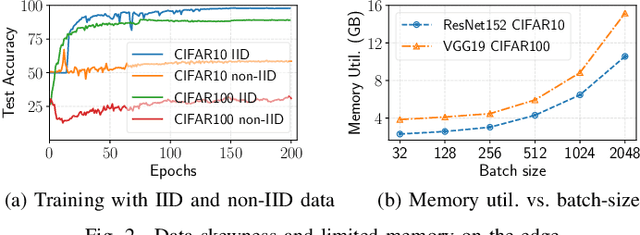
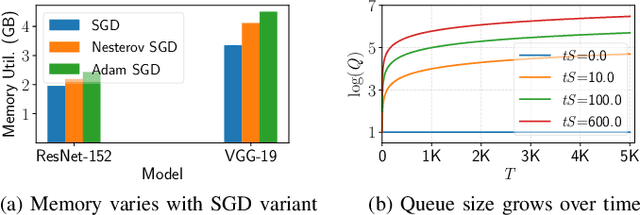
Distributed deep learning (DDL) training systems are designed for cloud and data-center environments that assumes homogeneous compute resources, high network bandwidth, sufficient memory and storage, as well as independent and identically distributed (IID) data across all nodes. However, these assumptions don't necessarily apply on the edge, especially when training neural networks on streaming data in an online manner. Computing on the edge suffers from both systems and statistical heterogeneity. Systems heterogeneity is attributed to differences in compute resources and bandwidth specific to each device, while statistical heterogeneity comes from unbalanced and skewed data on the edge. Different streaming-rates among devices can be another source of heterogeneity when dealing with streaming data. If the streaming rate is lower than training batch-size, device needs to wait until enough samples have streamed in before performing a single iteration of stochastic gradient descent (SGD). Thus, low-volume streams act like stragglers slowing down devices with high-volume streams in synchronous training. On the other hand, data can accumulate quickly in the buffer if the streaming rate is too high and the devices can't train at line-rate. In this paper, we introduce ScaDLES to efficiently train on streaming data at the edge in an online fashion, while also addressing the challenges of limited bandwidth and training with non-IID data. We empirically show that ScaDLES converges up to 3.29 times faster compared to conventional distributed SGD.
Graphical Games for UAV Swarm Control Under Time-Varying Communication Networks
May 04, 2022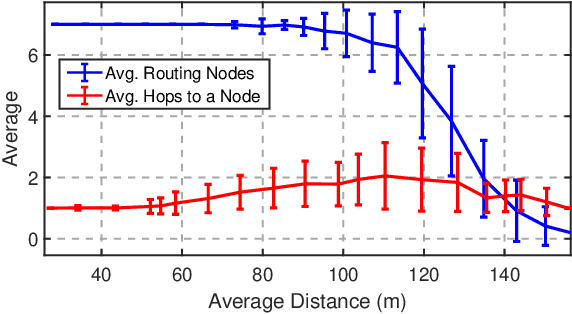
We propose a unified framework for coordinating Unmanned Aerial Vehicle (UAV) swarms operating under time-varying communication networks. Our framework builds on the concept of graphical games, which we argue provides a compelling paradigm to subsume the interaction structures found in networked UAV swarms thanks to the shared local neighborhood properties. We present a general-sum, factorizable payoff function for cooperative UAV swarms based on the aggregated local states and yield a Nash equilibrium for the stage games. Further, we propose a decomposition-based approach to solve stage-graphical games in a scalable and decentralized fashion by approximating virtual, mean neighborhoods. Finally, we discuss extending the proposed framework toward general-sum stochastic games by leveraging deep Q-learning and model-predictive control.
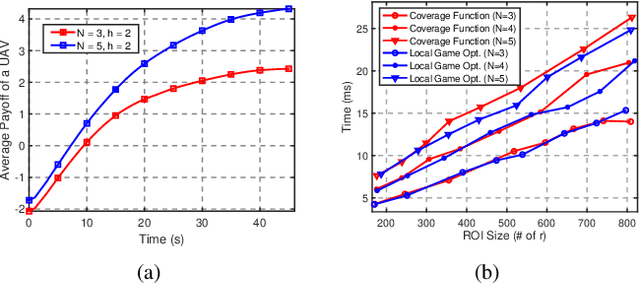
CoCo Games: Graphical Game-Theoretic Swarm Control for Communication-Aware Coverage
Nov 08, 2021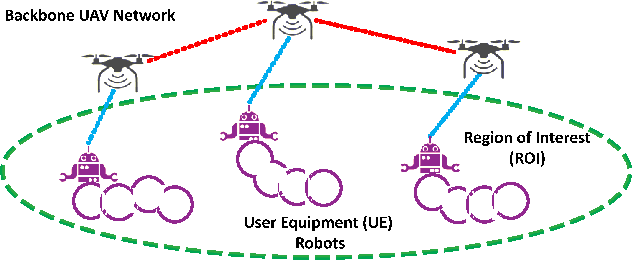
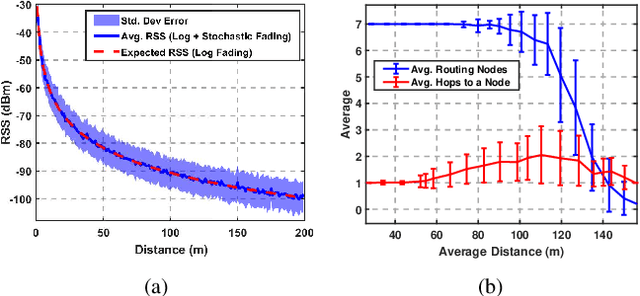
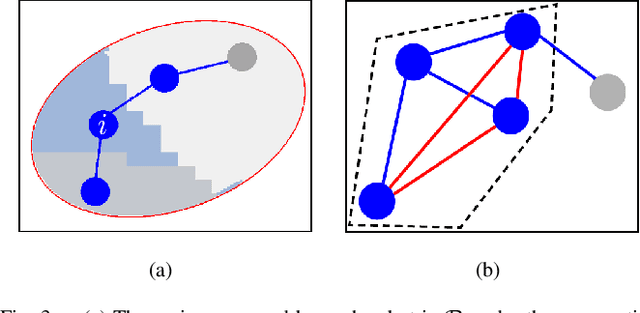
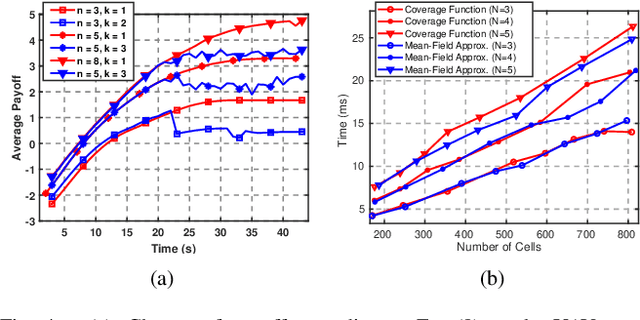
We present a novel approach to maximize the communication-aware coverage for robots operating over large-scale geographical regions of interest (ROIs). Our approach complements the underlying network topology in neighborhood selection and control, rendering it highly robust in dynamic environments. We formulate the coverage as a multi-stage, cooperative graphical game and employ Variational Inference (VI) to reach the equilibrium. We experimentally validate our approach in an mobile ad-hoc wireless network scenario using Unmanned Aerial Vehicles (UAV) and User Equipment (UE) robots. We show that it can cater to ROIs defined by stationary and moving User Equipment (UE) robots under realistic network conditions.