 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTula: Optimizing Time, Cost, and Generalization in Distributed Large-Batch Training
Mar 18, 2026Distributed training increases the number of batches processed per iteration either by scaling-out (adding more nodes) or scaling-up (increasing the batch-size). However, the largest configuration does not necessarily yield the best performance. Horizontal scaling introduces additional communication overhead, while vertical scaling is constrained by computation cost and device memory limits. Thus, simply increasing the batch-size leads to diminishing returns: training time and cost decrease initially but eventually plateaus, creating a knee-point in the time/cost versus batch-size pareto curve. The optimal batch-size therefore depends on the underlying model, data and available compute resources. Large batches also suffer from worse model quality due to the well-known generalization gap. In this paper, we present Tula, an online service that automatically optimizes time, cost, and convergence quality for large-batch training of convolutional models. It combines parallel-systems modeling with statistical performance prediction to identify the optimal batch-size. Tula predicts training time and cost within 7.5-14% error across multiple models, and achieves up to 20x overall speedup and improves test accuracy by 9% on average over standard large-batch training on various vision tasks, thus successfully mitigating the generalization gap and accelerating training at the same time.
Flexible Communication for Optimal Distributed Learning over Unpredictable Networks
Dec 05, 2023Gradient compression alleviates expensive communication in distributed deep learning by sending fewer values and its corresponding indices, typically via Allgather (AG). Training with high compression ratio (CR) achieves high accuracy like DenseSGD, but has lower parallel scaling due to high communication cost (i.e., parallel efficiency). Using lower CRs improves parallel efficiency by lowering synchronization cost, but degrades model accuracy as well (statistical efficiency). Further, speedup attained with different models and CRs also varies with network latency, effective bandwidth and collective op used for aggregation. In many cases, collectives like Allreduce (AR) have lower cost than AG to exchange the same amount of data. In this paper, we propose an AR-compatible Topk compressor that is bandwidth-optimal and thus performs better than AG in certain network configurations. We develop a flexible communication strategy that switches between AG and AR based on which collective is optimal in the current settings, and model the pareto-relationship between parallel and statistical efficiency as a multi-objective optimization (MOO) problem to dynamically adjust CR and accelerate training while still converging to high accuracy.
Accelerating Distributed ML Training via Selective Synchronization
Jul 16, 2023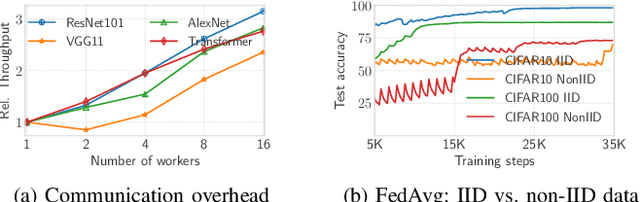

In distributed training, deep neural networks (DNNs) are launched over multiple workers concurrently and aggregate their local updates on each step in bulk-synchronous parallel (BSP) training. However, BSP does not linearly scale-out due to high communication cost of aggregation. To mitigate this overhead, alternatives like Federated Averaging (FedAvg) and Stale-Synchronous Parallel (SSP) either reduce synchronization frequency or eliminate it altogether, usually at the cost of lower final accuracy. In this paper, we present \texttt{SelSync}, a practical, low-overhead method for DNN training that dynamically chooses to incur or avoid communication at each step either by calling the aggregation op or applying local updates based on their significance. We propose various optimizations as part of \texttt{SelSync} to improve convergence in the context of \textit{semi-synchronous} training. Our system converges to the same or better accuracy than BSP while reducing training time by up to 14$\times$.
Taming Resource Heterogeneity In Distributed ML Training With Dynamic Batching
May 20, 2023Current techniques and systems for distributed model training mostly assume that clusters are comprised of homogeneous servers with a constant resource availability. However, cluster heterogeneity is pervasive in computing infrastructure, and is a fundamental characteristic of low-cost transient resources (such as EC2 spot instances). In this paper, we develop a dynamic batching technique for distributed data-parallel training that adjusts the mini-batch sizes on each worker based on its resource availability and throughput. Our mini-batch controller seeks to equalize iteration times on all workers, and facilitates training on clusters comprised of servers with different amounts of CPU and GPU resources. This variable mini-batch technique uses proportional control and ideas from PID controllers to find stable mini-batch sizes. Our empirical evaluation shows that dynamic batching can reduce model training times by more than 4x on heterogeneous clusters.
GraVAC: Adaptive Compression for Communication-Efficient Distributed DL Training
May 20, 2023


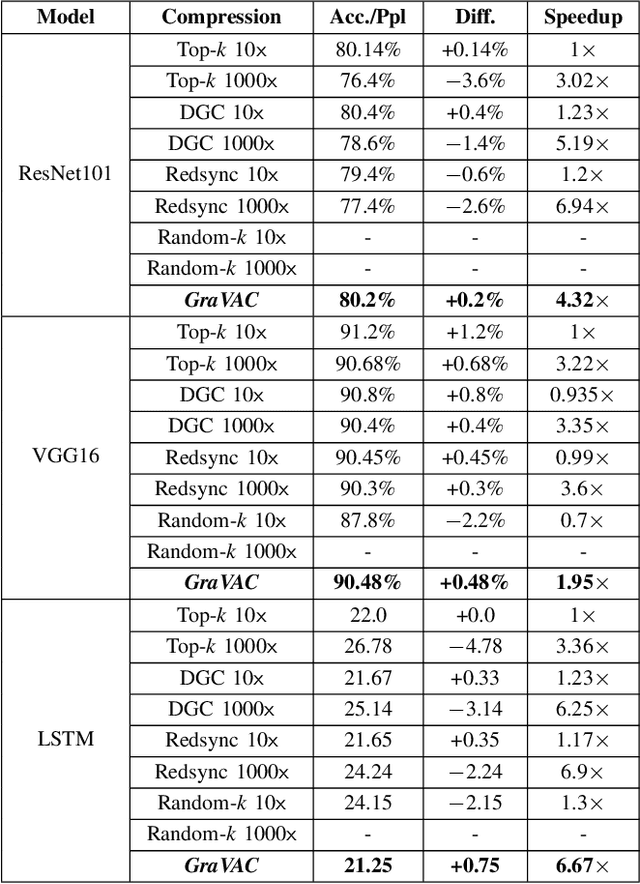
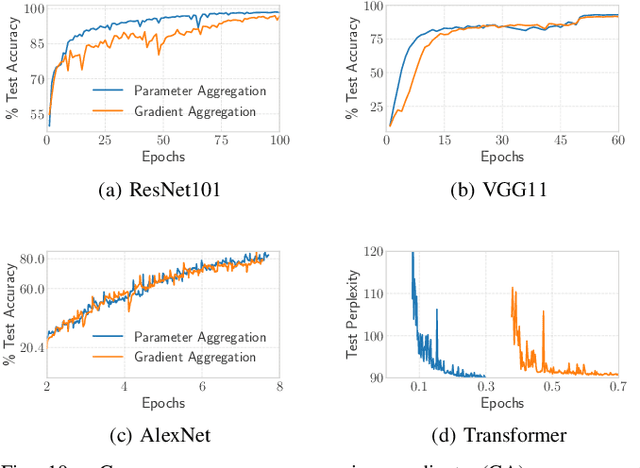
Distributed data-parallel (DDP) training improves overall application throughput as multiple devices train on a subset of data and aggregate updates to produce a globally shared model. The periodic synchronization at each iteration incurs considerable overhead, exacerbated by the increasing size and complexity of state-of-the-art neural networks. Although many gradient compression techniques propose to reduce communication cost, the ideal compression factor that leads to maximum speedup or minimum data exchange remains an open-ended problem since it varies with the quality of compression, model size and structure, hardware, network topology and bandwidth. We propose GraVAC, a framework to dynamically adjust compression factor throughout training by evaluating model progress and assessing gradient information loss associated with compression. GraVAC works in an online, black-box manner without any prior assumptions about a model or its hyperparameters, while achieving the same or better accuracy than dense SGD (i.e., no compression) in the same number of iterations/epochs. As opposed to using a static compression factor, GraVAC reduces end-to-end training time for ResNet101, VGG16 and LSTM by 4.32x, 1.95x and 6.67x respectively. Compared to other adaptive schemes, our framework provides 1.94x to 5.63x overall speedup.
Scavenger: A Cloud Service for Optimizing Cost and Performance of ML Training
Mar 12, 2023While the pay-as-you-go nature of cloud virtual machines (VMs) makes it easy to spin-up large clusters for training ML models, it can also lead to ballooning costs. The 100s of virtual machine sizes provided by cloud platforms also makes it extremely challenging to select the ``right'' cloud cluster configuration for training. Furthermore, the training time and cost of distributed model training is highly sensitive to the cluster configurations, and presents a large and complex tradeoff-space. In this paper, we develop principled and practical techniques for optimizing the training time and cost of distributed ML model training on the cloud. Our key insight is that both parallel and statistical efficiency must be considered when selecting the optimum job configuration parameters such as the number of workers and the batch size. By combining conventional parallel scaling concepts and new insights into SGD noise, our models accurately estimate the time and cost on different cluster configurations with < 5% error. Using the repetitive nature of training and our models, we can search for optimum cloud configurations in a black-box, online manner. Our approach reduces training times by 2 times and costs more more than 50%. Compared to an oracle-based approach, our performance models are accurate to within 2% such that the search imposes an overhead of just 10%.
ScaDLES: Scalable Deep Learning over Streaming data at the Edge
Jan 21, 2023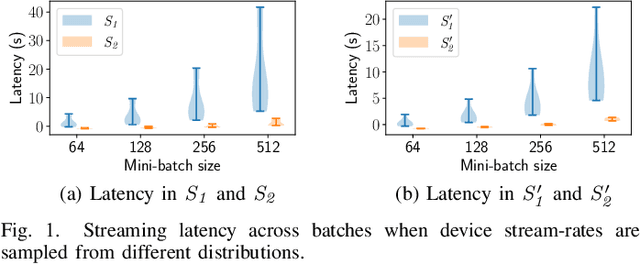
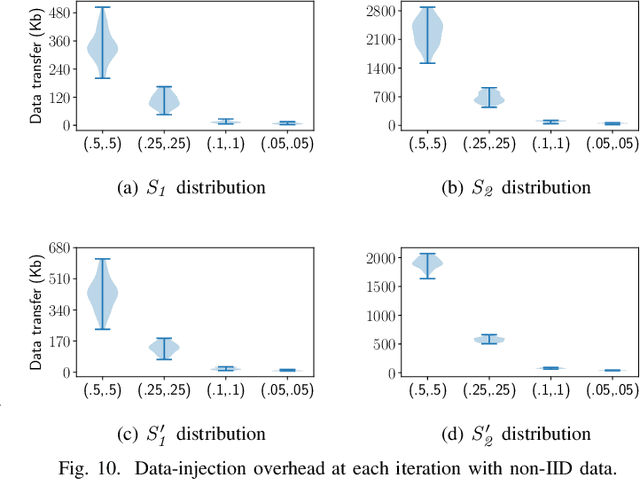
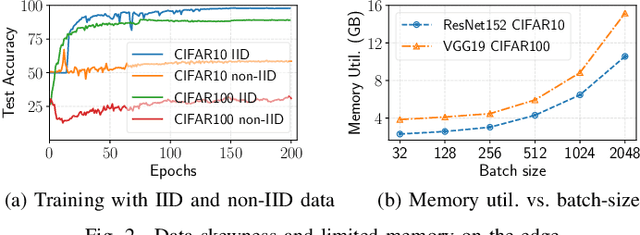
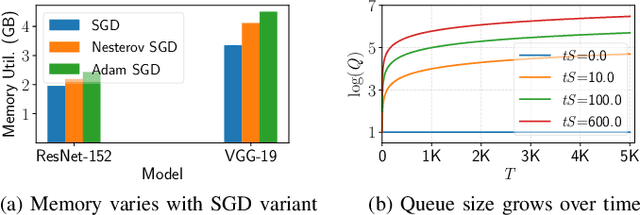
Distributed deep learning (DDL) training systems are designed for cloud and data-center environments that assumes homogeneous compute resources, high network bandwidth, sufficient memory and storage, as well as independent and identically distributed (IID) data across all nodes. However, these assumptions don't necessarily apply on the edge, especially when training neural networks on streaming data in an online manner. Computing on the edge suffers from both systems and statistical heterogeneity. Systems heterogeneity is attributed to differences in compute resources and bandwidth specific to each device, while statistical heterogeneity comes from unbalanced and skewed data on the edge. Different streaming-rates among devices can be another source of heterogeneity when dealing with streaming data. If the streaming rate is lower than training batch-size, device needs to wait until enough samples have streamed in before performing a single iteration of stochastic gradient descent (SGD). Thus, low-volume streams act like stragglers slowing down devices with high-volume streams in synchronous training. On the other hand, data can accumulate quickly in the buffer if the streaming rate is too high and the devices can't train at line-rate. In this paper, we introduce ScaDLES to efficiently train on streaming data at the edge in an online fashion, while also addressing the challenges of limited bandwidth and training with non-IID data. We empirically show that ScaDLES converges up to 3.29 times faster compared to conventional distributed SGD.