 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Examination of Wearable Sensors and Video Data Capture for Human Exercise Classification
Jul 10, 2023



Wearable sensors such as Inertial Measurement Units (IMUs) are often used to assess the performance of human exercise. Common approaches use handcrafted features based on domain expertise or automatically extracted features using time series analysis. Multiple sensors are required to achieve high classification accuracy, which is not very practical. These sensors require calibration and synchronization and may lead to discomfort over longer time periods. Recent work utilizing computer vision techniques has shown similar performance using video, without the need for manual feature engineering, and avoiding some pitfalls such as sensor calibration and placement on the body. In this paper, we compare the performance of IMUs to a video-based approach for human exercise classification on two real-world datasets consisting of Military Press and Rowing exercises. We compare the performance using a single camera that captures video in the frontal view versus using 5 IMUs placed on different parts of the body. We observe that an approach based on a single camera can outperform a single IMU by 10 percentage points on average. Additionally, a minimum of 3 IMUs are required to outperform a single camera. We observe that working with the raw data using multivariate time series classifiers outperforms traditional approaches based on handcrafted or automatically extracted features. Finally, we show that an ensemble model combining the data from a single camera with a single IMU outperforms either data modality. Our work opens up new and more realistic avenues for this application, where a video captured using a readily available smartphone camera, combined with a single sensor, can be used for effective human exercise classification.
Faking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022
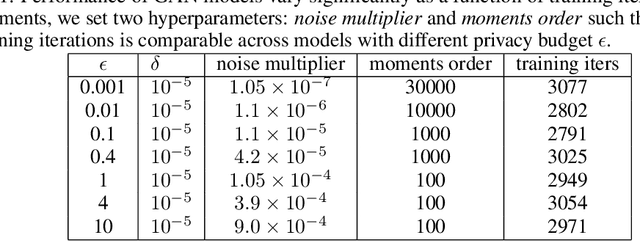

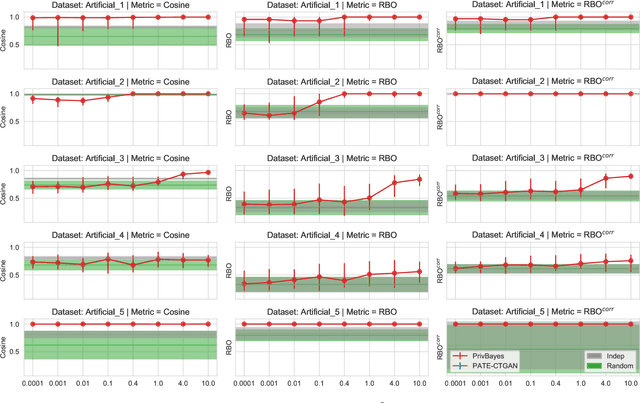
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
Interpretable Time Series Classification using Linear Models and Multi-resolution Multi-domain Symbolic Representations
May 31, 2020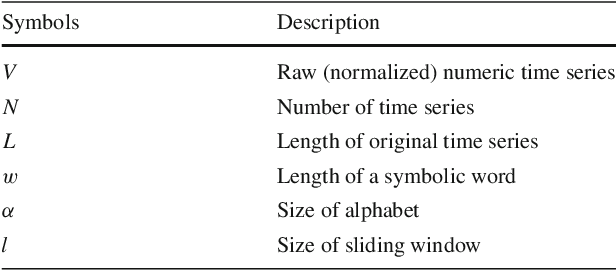
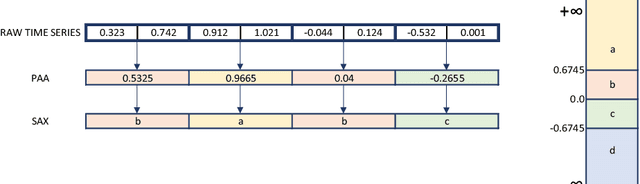
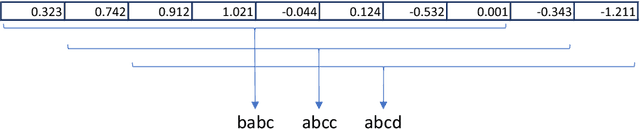

The time series classification literature has expanded rapidly over the last decade, with many new classification approaches published each year. Prior research has mostly focused on improving the accuracy and efficiency of classifiers, with interpretability being somewhat neglected. This aspect of classifiers has become critical for many application domains and the introduction of the EU GDPR legislation in 2018 is likely to further emphasize the importance of interpretable learning algorithms. Currently, state-of-the-art classification accuracy is achieved with very complex models based on large ensembles (COTE) or deep neural networks (FCN). These approaches are not efficient with regard to either time or space, are difficult to interpret and cannot be applied to variable-length time series, requiring pre-processing of the original series to a set fixed-length. In this paper we propose new time series classification algorithms to address these gaps. Our approach is based on symbolic representations of time series, efficient sequence mining algorithms and linear classification models. Our linear models are as accurate as deep learning models but are more efficient regarding running time and memory, can work with variable-length time series and can be interpreted by highlighting the discriminative symbolic features on the original time series. We show that our multi-resolution multi-domain linear classifier (mtSS-SEQL+LR) achieves a similar accuracy to the state-of-the-art COTE ensemble, and to recent deep learning methods (FCN, ResNet), but uses a fraction of the time and memory required by either COTE or deep models. To further analyse the interpretability of our classifier, we present a case study on a human motion dataset collected by the authors. We release all the results, source code and data to encourage reproducibility.
* arXiv admin note: substantial text overlap with arXiv:1808.04022