 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground Knowledge Injection for Interpretable Sequence Classification
Jun 25, 2020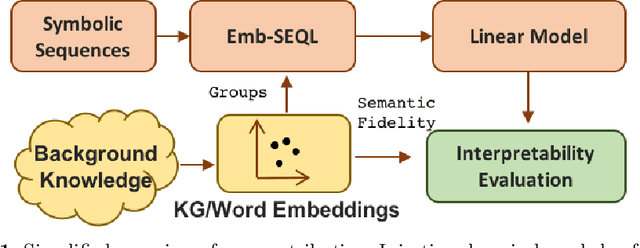
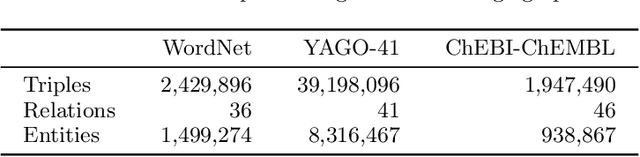
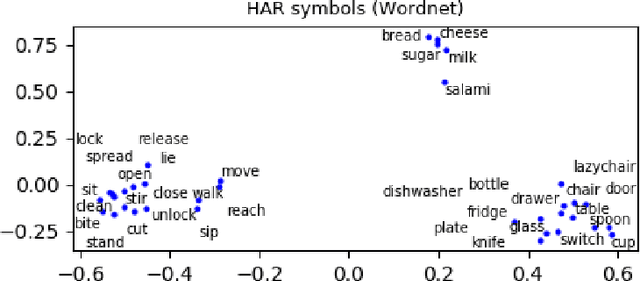
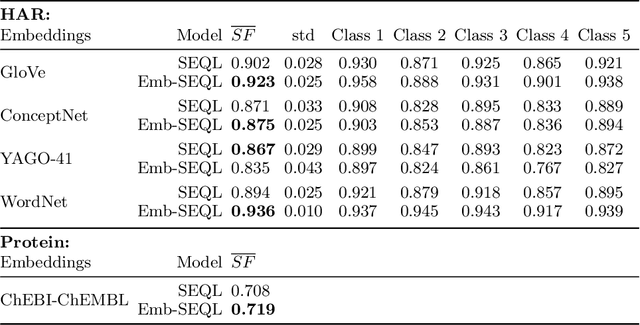
Sequence classification is the supervised learning task of building models that predict class labels of unseen sequences of symbols. Although accuracy is paramount, in certain scenarios interpretability is a must. Unfortunately, such trade-off is often hard to achieve since we lack human-independent interpretability metrics. We introduce a novel sequence learning algorithm, that combines (i) linear classifiers - which are known to strike a good balance between predictive power and interpretability, and (ii) background knowledge embeddings. We extend the classic subsequence feature space with groups of symbols which are generated by background knowledge injected via word or graph embeddings, and use this new feature space to learn a linear classifier. We also present a new measure to evaluate the interpretability of a set of symbolic features based on the symbol embeddings. Experiments on human activity recognition from wearables and amino acid sequence classification show that our classification approach preserves predictive power, while delivering more interpretable models.
Interpretable Time Series Classification using Linear Models and Multi-resolution Multi-domain Symbolic Representations
May 31, 2020
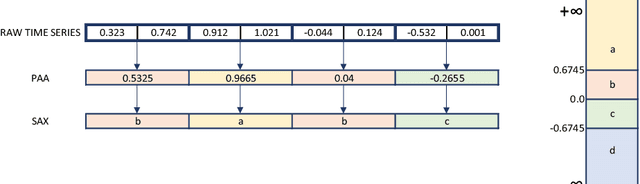
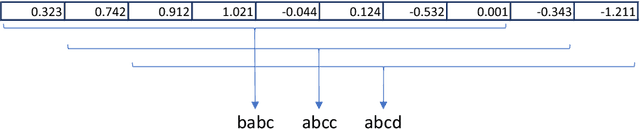

The time series classification literature has expanded rapidly over the last decade, with many new classification approaches published each year. Prior research has mostly focused on improving the accuracy and efficiency of classifiers, with interpretability being somewhat neglected. This aspect of classifiers has become critical for many application domains and the introduction of the EU GDPR legislation in 2018 is likely to further emphasize the importance of interpretable learning algorithms. Currently, state-of-the-art classification accuracy is achieved with very complex models based on large ensembles (COTE) or deep neural networks (FCN). These approaches are not efficient with regard to either time or space, are difficult to interpret and cannot be applied to variable-length time series, requiring pre-processing of the original series to a set fixed-length. In this paper we propose new time series classification algorithms to address these gaps. Our approach is based on symbolic representations of time series, efficient sequence mining algorithms and linear classification models. Our linear models are as accurate as deep learning models but are more efficient regarding running time and memory, can work with variable-length time series and can be interpreted by highlighting the discriminative symbolic features on the original time series. We show that our multi-resolution multi-domain linear classifier (mtSS-SEQL+LR) achieves a similar accuracy to the state-of-the-art COTE ensemble, and to recent deep learning methods (FCN, ResNet), but uses a fraction of the time and memory required by either COTE or deep models. To further analyse the interpretability of our classifier, we present a case study on a human motion dataset collected by the authors. We release all the results, source code and data to encourage reproducibility.
* arXiv admin note: substantial text overlap with arXiv:1808.04022
Interpretable Time Series Classification using All-Subsequence Learning and Symbolic Representations in Time and Frequency Domains
Aug 12, 2018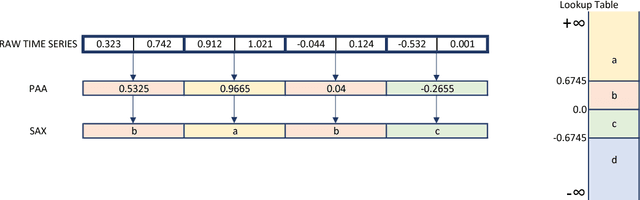


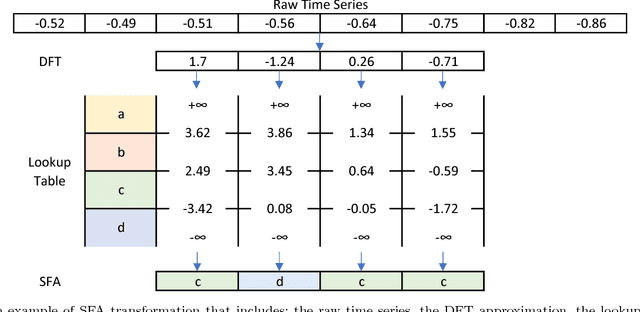
The time series classification literature has expanded rapidly over the last decade, with many new classification approaches published each year. The research focus has mostly been on improving the accuracy and efficiency of classifiers, while their interpretability has been somewhat neglected. Classifier interpretability has become a critical constraint for many application domains and the introduction of the 'right to explanation' GDPR EU legislation in May 2018 is likely to further emphasize the importance of explainable learning algorithms. In this work we analyse the state-of-the-art for time series classification, and propose new algorithms that aim to maintain the classifier accuracy and efficiency, but keep interpretability as a key design constraint. We present new time series classification algorithms that advance the state-of-the-art by implementing the following three key ideas: (1) Multiple resolutions of symbolic approximations: we combine symbolic representations obtained using different parameters; (2) Multiple domain representations: we combine symbolic approximations in time (e.g., SAX) and frequency (e.g., SFA) domains; (3) Efficient navigation of a huge symbolic-words space: we adapt a symbolic sequence classifier named SEQL, to make it work with multiple domain representations (e.g., SAX-SEQL, SFA-SEQL), and use its greedy feature selection strategy to effectively filter the best features for each representation. We show that a multi-resolution multi-domain linear classifier, SAX-SFA-SEQL, achieves a similar accuracy to the state-of-the-art COTE ensemble, and to a recent deep learning method (FCN), but uses a fraction of the time required by either COTE or FCN. We discuss the accuracy, efficiency and interpretability of our proposed algorithms. To further analyse the interpretability aspect of our classifiers, we present a case study on an ecology benchmark.